



 本文介绍了Pandas中的变形操作,包括透视表、交叉表和哑变量的概念与使用。透视表允许动态数据分析,交叉表展示多变量频率分布,哑变量用于量化质的属性。此外,还探讨了melt、crosstab、pivot、pivot_table、stack和unstack等函数的特性及其在多级索引中的应用。文章指出,stack和unstack虽类似pivot_table,但有各自独特用途,且使用stack后立即使用unstack不一定能恢复原状。最后,通过比较,发现pivot通常比crosstab和pivot_table速度快。
本文介绍了Pandas中的变形操作,包括透视表、交叉表和哑变量的概念与使用。透视表允许动态数据分析,交叉表展示多变量频率分布,哑变量用于量化质的属性。此外,还探讨了melt、crosstab、pivot、pivot_table、stack和unstack等函数的特性及其在多级索引中的应用。文章指出,stack和unstack虽类似pivot_table,但有各自独特用途,且使用stack后立即使用unstack不一定能恢复原状。最后,通过比较,发现pivot通常比crosstab和pivot_table速度快。
(1)透视表:
数据透视表(Pivot Table)是一种交互式的表,可以进行某些计算,如求和与计数等。所进行的计算与数据跟数据透视表中的排列有关。
称为数据透视表,是因为可以动态地改变它们的版面布置,以便按照不同方式分析数据,也可以重新安排行号、列标和页字段。每一次改变版面布置时,数据透视表会立即按照新的布置重新计算数据。另外,如果原始数据发生更改,则可以更新数据透视表。
(2)交叉表:
交叉表是矩阵格式的一种表格,显示变量的(多变量)频率分布。
(3)哑变量:
虚拟变量 ( Dummy Variables) 又称虚设变量、名义变量或哑变量,用以反映质的属性的一个人工变量,是量化了的自变量,通常取值为0或1。引入哑变量可使线形回归模型变得更复杂,但对问题描述更简明,一个方程能达到两个方程的作用,而且接近现实。
(4)因子化
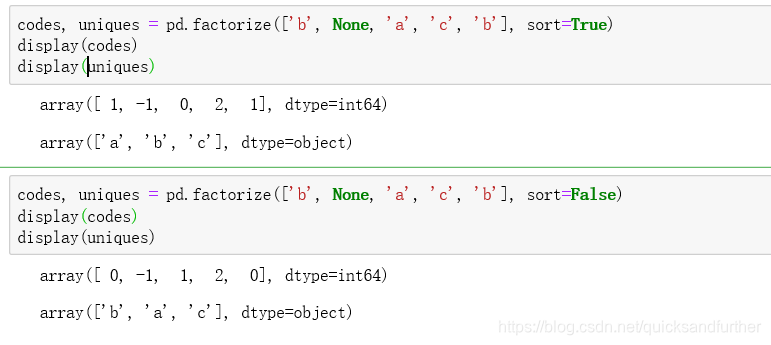
类似于将一些已知的项变成0或者1表示,缺失值为-1, factorize方法中参数sort默认为false,是布尔值,表示排序后赋值。
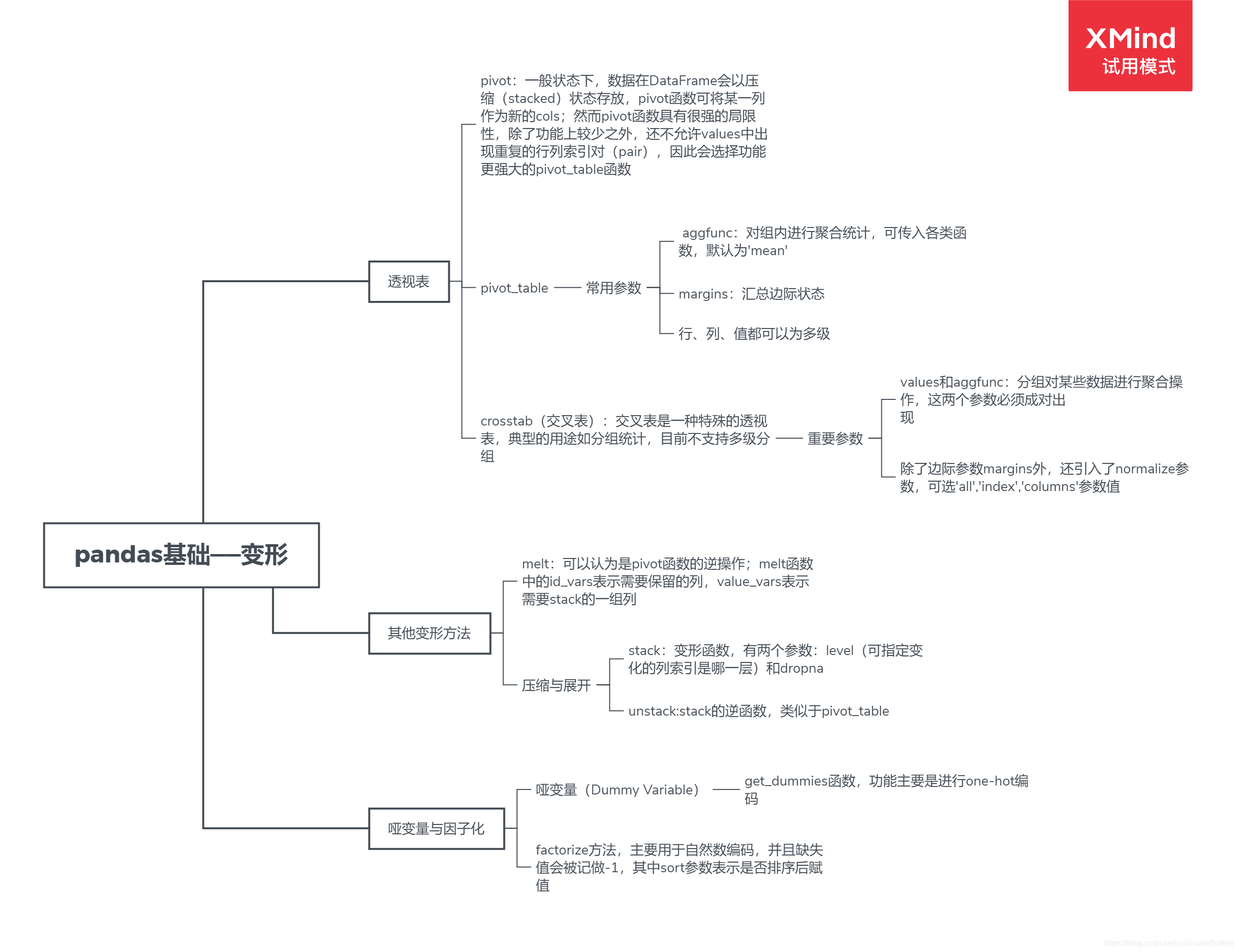
下图为做的一个简易思维导图(关于pandas中变形这一块):
问题:
【问题一】 上面提到了许多变形函数,如melt/crosstab/pivot/pivot_table/stack/unstack函数,请总结它们各自的使用特点。
Melt:pivot的逆操作
Crosstab:不支持多级分组
Pivot:在参数values中不能出现重复的索引对,假如第一个索引中的values值,不能在第二个索引中重复出现
Pivot_table:弥补了pivot中的重复出现问题,但是运行速度慢
Stack:将数据压缩,其中参数level指定变化得层数
Unstack:类似于pivot_table,同样可以指定level参数
【问题二】 变形函数和多级索引是什么关系?哪些变形函数会使得索引维数变化?具体如何变化?
变形函数是使数据的行列发生变化,多级索引是索引不再是一个,多个,多维索引;stack,unstack,
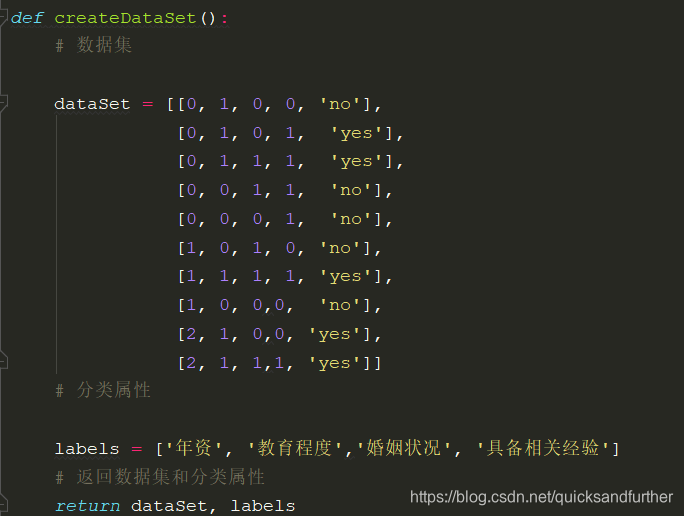
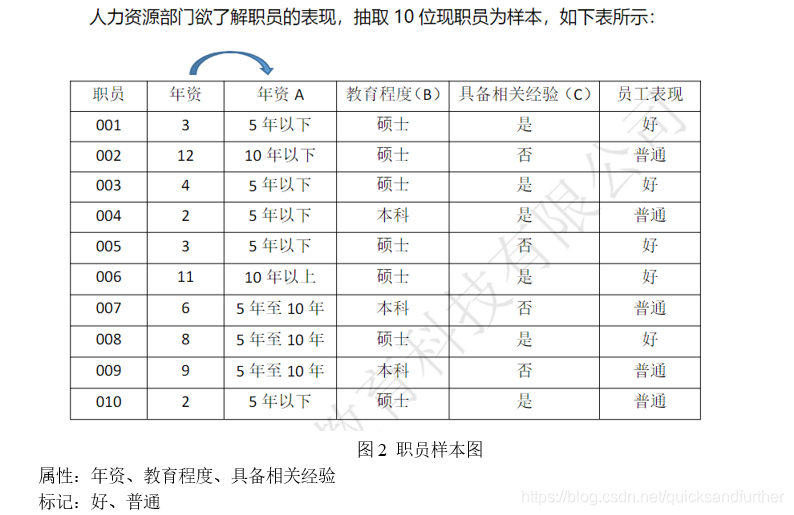
【问题三】 请举出一个除了上文提过的关于哑变量方法的例子。
【问题四】 使用完stack后立即使用unstack一定能保证变化结果与原始表完全一致吗?
不一致
【问题五】 透视表中涉及了三个函数,请分别使用它们完成相同的目标(任务自定)并比较哪个速度最快。
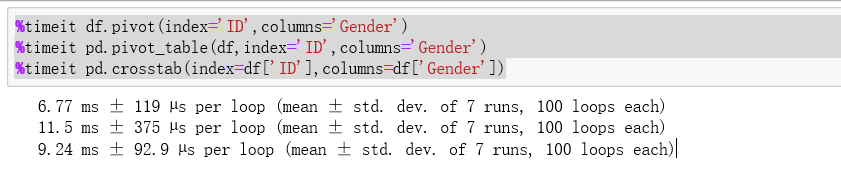
V_pivot>V_crosstab>V_pivot_table
【问题六】 既然melt起到了stack的功能,为什么再设计stack函数?
虽然功能类似于melt,是堆叠的含义,将行索引转化为列索引,里面的参数level可以指定变化的层数,dropna用于去掉缺失数据

















 5234
5234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









