




数据集文件夹构建格式看这篇
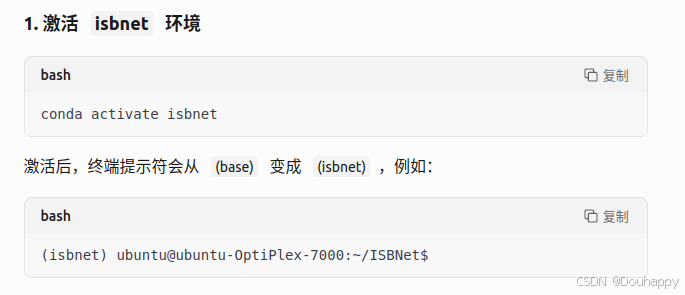
需要先激活isbnet环境(非常重要!)
conda activate isbnetpy文件里面的内容——文件路径根据你自己的修改
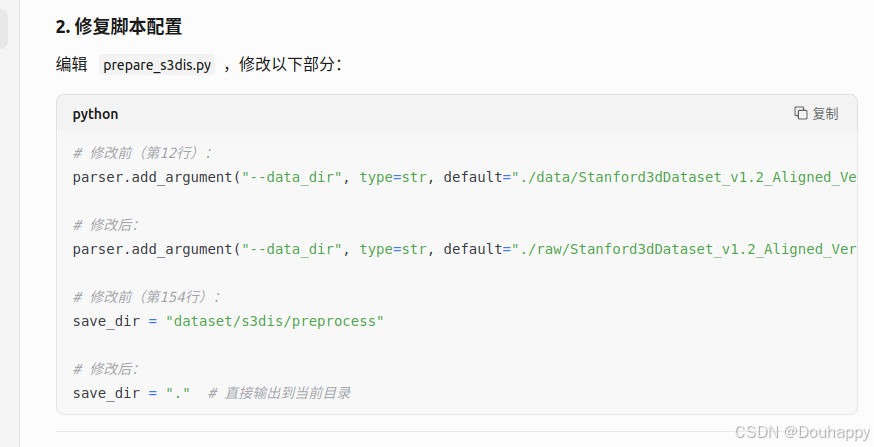
首先是prepare_s3dis.py文件的问题
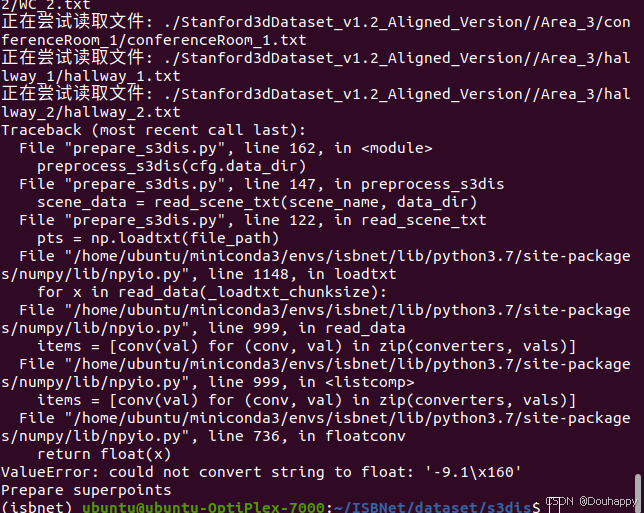
4月1日晚上遇到一个问题:
prepare_s3dis.py 在尝试读取 Area_X/room_Y/room_Y.txt 时,发现文件中包含非法字符串 '167.\x1000000'(应为 167.1000000)。
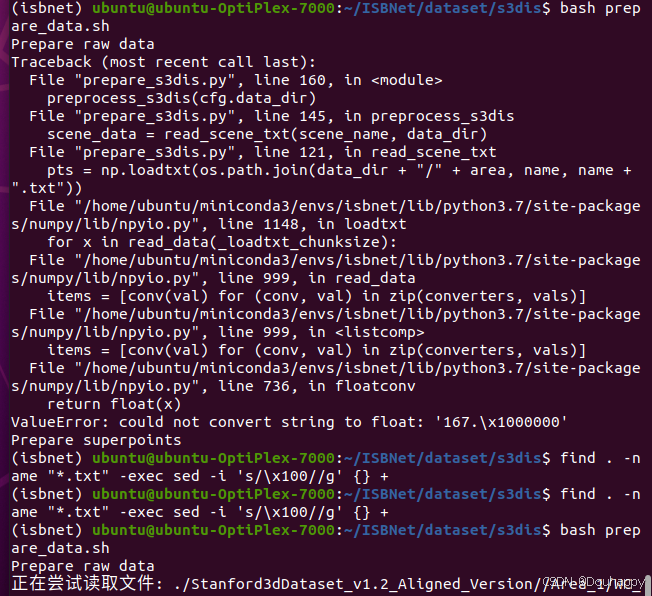
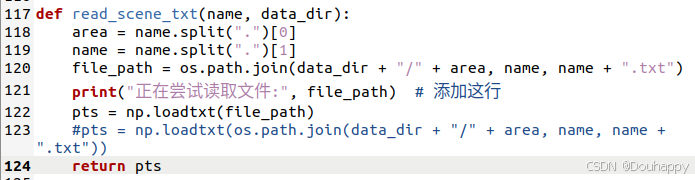
4月2日在我添加一个提示后,神奇的好了,因为昨天是愚人节吗哈哈
然后,多跑了几个文件后又出问题了
之前出现的很多问题都是在.DS_Store文件中的,所以把它们都给删除
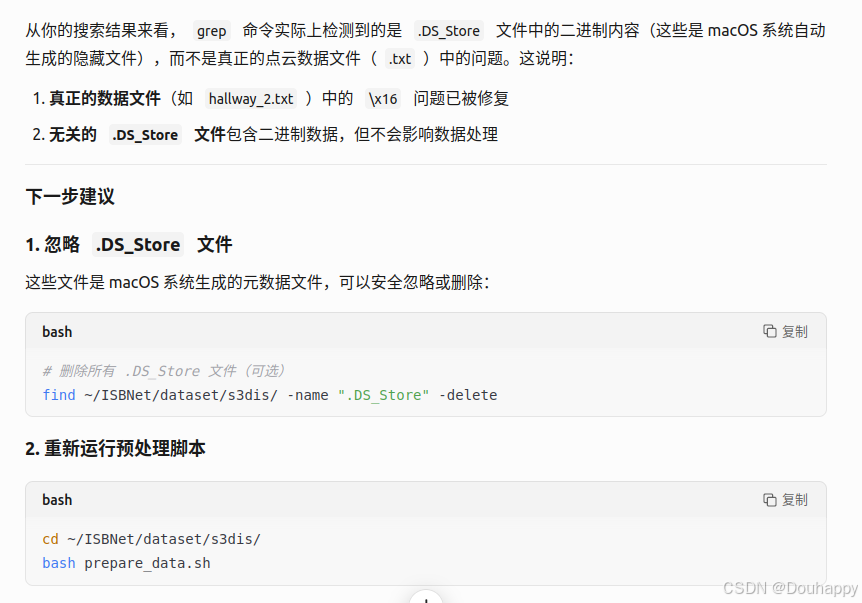
# 删除所有 .DS_Store 文件(可选)
find ~/ISBNet/dataset/s3dis/ -name ".DS_Store" -delete
# 重新运行脚本
cd ~/ISBNet/dataset/s3dis/
bash prepare_data.sh查找可能有问题的文件
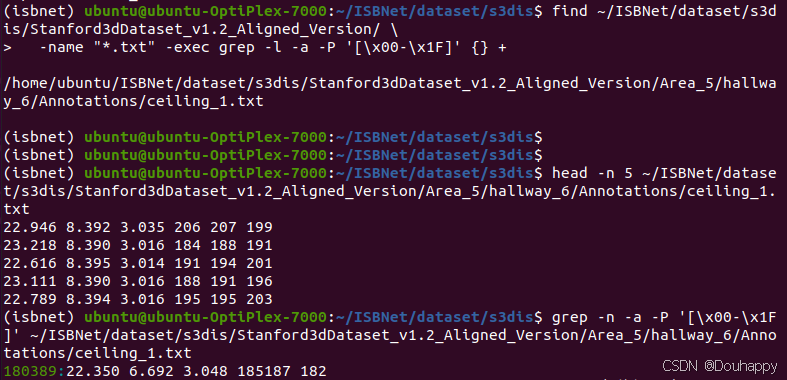
(isbnet) ubuntu@ubuntu-OptiPlex-7000:~/ISBNet/dataset/s3dis$ find ~/ISBNet/dataset/s3dis/Stanford3dDataset_v1.2_Aligned_Version/ \
> -name "*.txt" -exec grep -l -a -P '[\x00-\x1F]' {} +
/home/ubuntu/ISBNet/dataset/s3dis/Stanford3dDataset_v1.2_Aligned_Version/Area_5/hallway_6/Annotations/ceiling_1.txt
(isbnet) ubuntu@ubuntu-OptiPlex-7000:~/ISBNet/dataset/s3dis$
(isbnet) ubuntu@ubuntu-OptiPlex-7000:~/ISBNet/dataset/s3dis$
(isbnet) ubuntu@ubuntu-OptiPlex-7000:~/ISBNet/dataset/s3dis$ head -n 5 ~/ISBNet/dataset/s3dis/Stanford3dDataset_v1.2_Aligned_Version/Area_5/hallway_6/Annotations/ceiling_1.txt
22.946 8.392 3.035 206 207 199
23.218 8.390 3.016 184 188 191
22.616 8.395 3.014 191 194 201
23.111 8.390 3.016 188 191 196
22.789 8.394 3.016 195 195 203
(isbnet) ubuntu@ubuntu-OptiPlex-7000:~/ISBNet/dataset/s3dis$ grep -n -a -P '[\x00-\x1F]' ~/ISBNet/dataset/s3dis/Stanford3dDataset_v1.2_Aligned_Version/Area_5/hallway_6/Annotations/ceiling_1.txt
180389:22.350 6.692 3.048 185187 182
直接打开文件就发现了问题
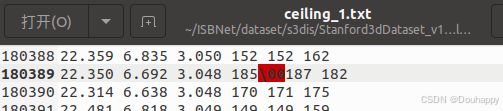
然后我就直接手动删除了
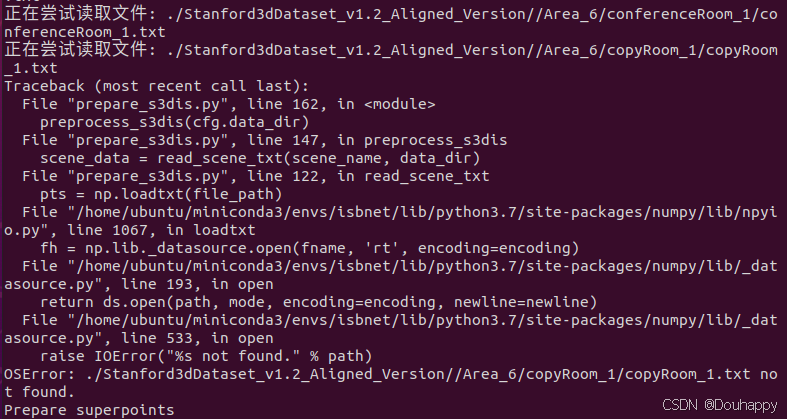
又出现找不到文件的错误,打开文件夹后发现是命名多了个_
这数据集真让人感到无语了......
又修改了代码,让它能接着上次的进行
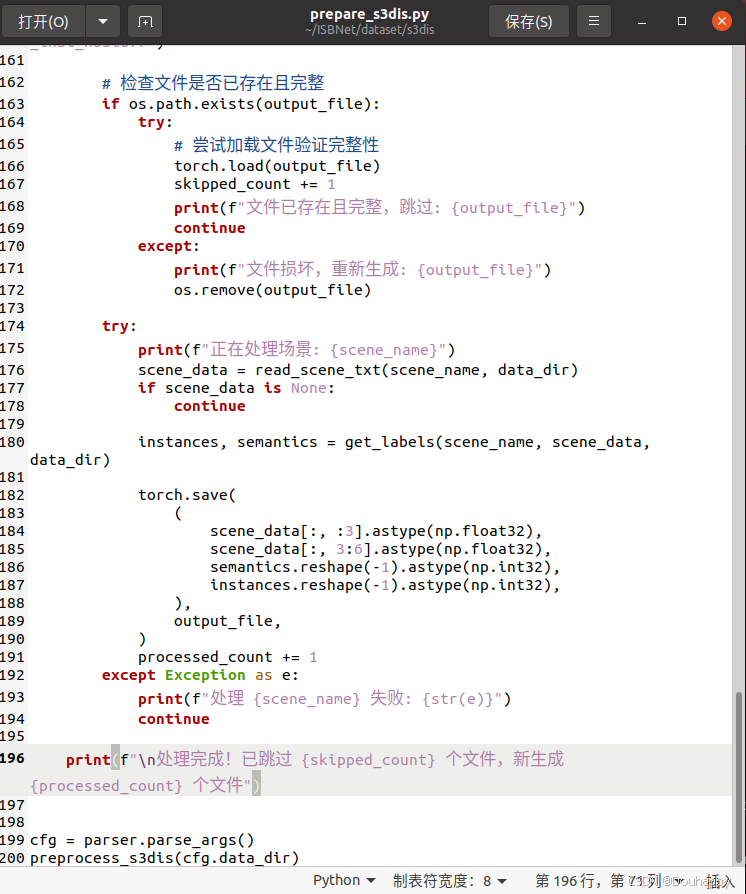
下面是prepare_superpoints.py的问题了
python3 prepare_superpoints.py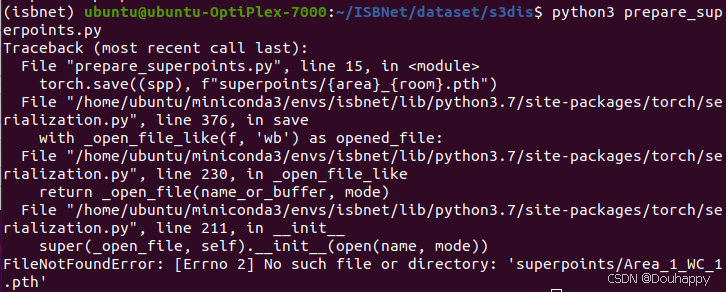
这个错误表明程序无法找到 superpoints/ 目录来保存输出文件。
使用Deepseek改成下面的代码就成功了
import numpy as np
import torch
import glob
import os
# 确保输出目录存在
os.makedirs("superpoints", exist_ok=True)
files = sorted(glob.glob("learned_superpoint_graph_segmentations/*.npy"))
success_count = 0
skip_count = 0
error_count = 0
for file in files:
try:
# 解析文件名
filename = os.path.basename(file)
area, room = filename.split(".")[:2] # 获取Area和Room部分
# 构建输出路径
output_path = os.path.join("superpoints", f"{area}_{room}.pth")
# 检查文件是否已存在
if os.path.exists(output_path):
print(f"文件已存在,跳过: {output_path}")
skip_count += 1
continue
# 加载并处理数据
data = np.load(file, allow_pickle=True).item()
if "segments" not in data:
raise ValueError(f"文件 {filename} 中缺少'segments'键")
# 保存结果
torch.save(data["segments"], output_path)
success_count += 1
print(f"成功处理: {filename} -> {output_path}")
except Exception as e:
error_count += 1
print(f"处理文件 {filename} 时出错: {str(e)}")
# 打印汇总信息
print(f"\n处理完成!\n成功: {success_count}\n跳过: {skip_count}\n失败: {error_count}")这次数据就都准备好了
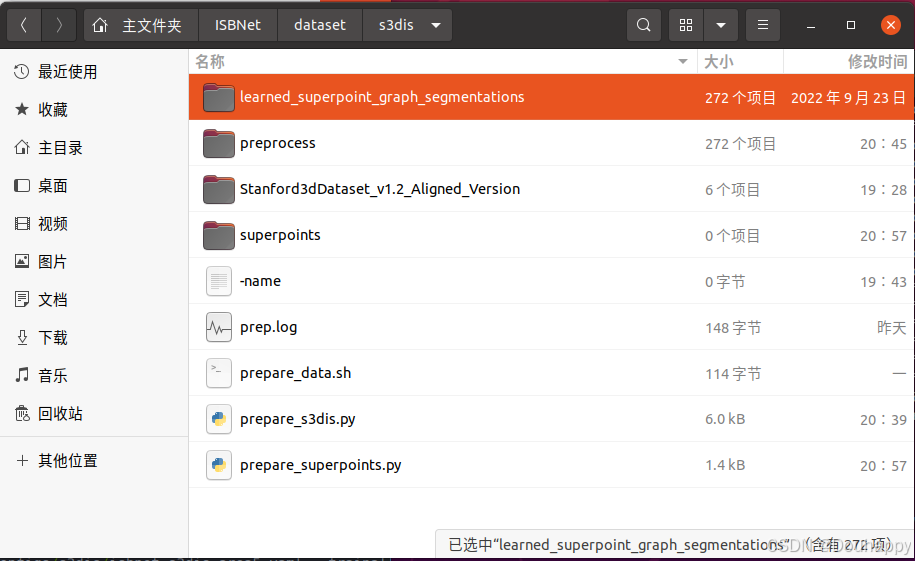
接下来开始训练
# Pretrain step 骨干网络预训练
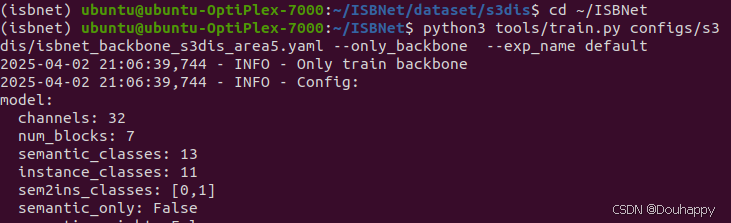
python3 tools/train.py configs/s3dis/isbnet_backbone_s3dis_area5.yaml --only_backbone --exp_name default
# Train entire model 完整模型训练
python3 tools/train.py configs/s3dis/isbnet_s3dis_area5.yaml --trainall --exp_name default出现了参考文章里面一样的问题
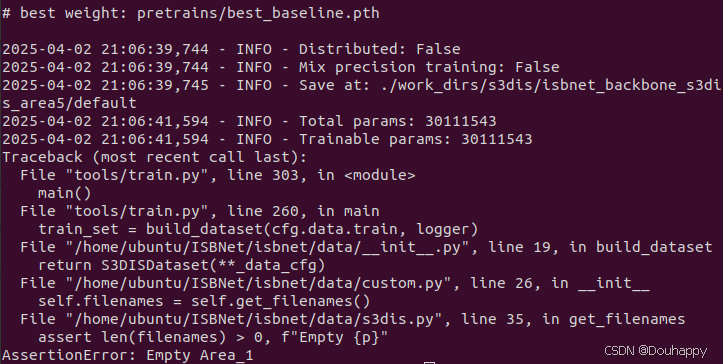
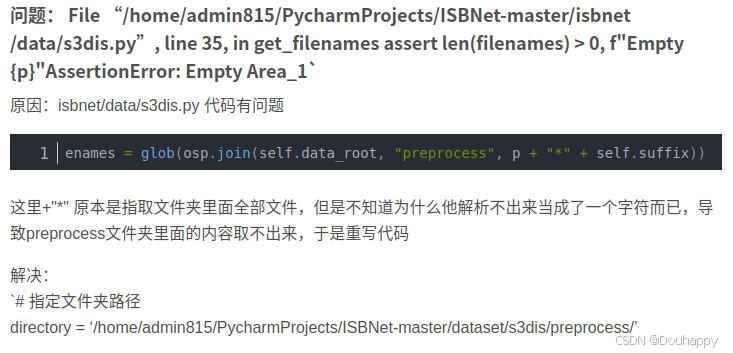
然后我deepseek修改了代码好了
问题:
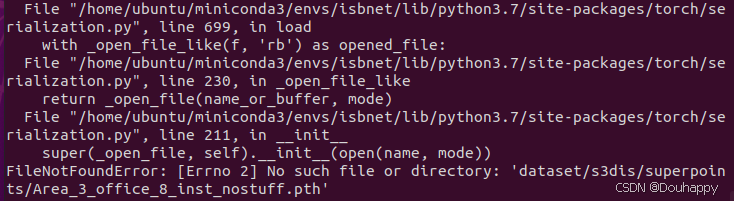

新的问题已经出现——GPU内存不足
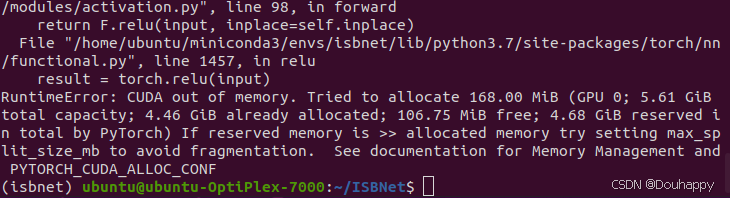


然后又出现了新的问题

这个CUDA错误 (CUBLAS_STATUS_INVALID_VALUE) 通常是由于GPU内存不足或张量形状不匹配导致的


















 2493
2493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









