



注:作者为初学者,有些知识不太熟悉,可能描述有误,望见谅。
Unet网络简介
Unet是一种对称的编码器-解码器结构,最初由Olaf Ronneberger等人于2015年提出,因为其网络结构像“U”型,故称为Unet,主要用于生物医学图像分割。其核心特点是跳跃连接(Skip Connection),通过将编码器的高分辨率特征与解码器的上采样特征融合,解决了传统卷积神经网络在图像分割中丢失空间信息的问题。
编码器其实是逐步的下采样过程,解码器是逐步的上采样过程。
适用场景
医学图像分割:如细胞分割、肿瘤检测、MRI/CT图像分析。(最适合)
遥感图像处理:土地分类、建筑物提取。
工业检测:缺陷识别、自动化质检。
自然图像分割:自动驾驶中的道路、行人分割。
网络结构讲解
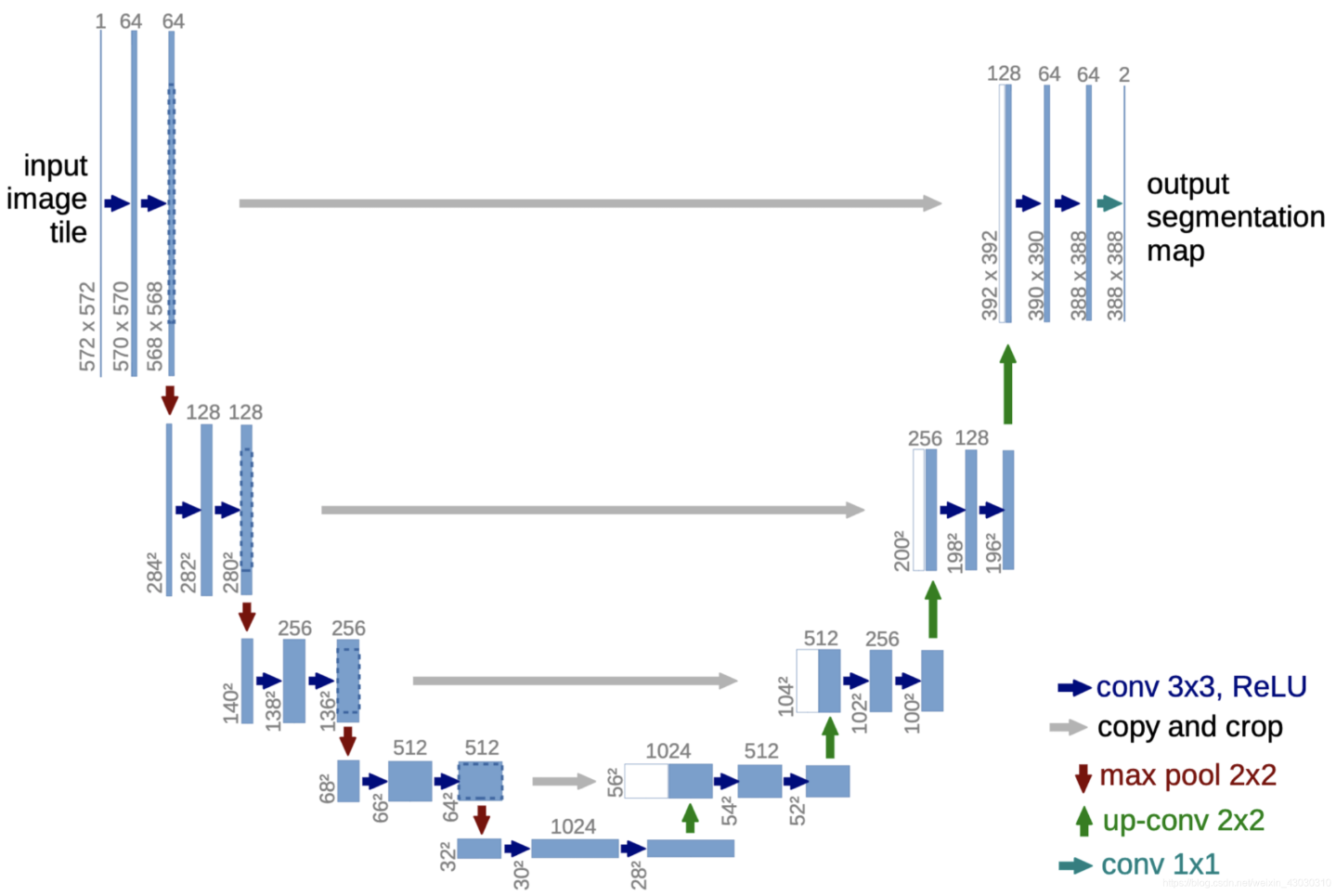
接下来我会以最直接最简单的方式一步一步实现Unet,先把整个网络结构分为编码器(左边下采样过程)与解码器(右边上采样过程)。
编码器
编码器由连续的卷积层和最大池化层组成,逐步提取特征并降低空间分辨率。每层包含两个卷积操作(Conv+ReLU)和一个最大池化操作。
(1)输入图像尺寸:572*572*1。这个尺寸是在“conv + 4 级下采样 + 要输出 388×388”这一组特定参数下,反推出来的入口尺寸。(如果修改 padding 值使得每次卷积后大小不变,则输入尺寸可以更加自由,但是要保证每一次下采样必须是“整数倍)
(2)第一块: 两次 3×3 卷积 + ReLU 输出 568×568×64
(所有的卷积操作都是stride=1,padding=0)
最大池化 2×2 最大池化 下采样为 284×284×64(kernel_size=2,stride=2)
(3)第二块: 两次 3×3 卷积 + ReLU 输出 280×280×128
最大池化 2×2 最大池化 下采样为 140×140×128
(4)第三块: 两次 3×3 卷积 + ReLU 输出 136×136×256
最大池化 2×2 最大池化 下采样为 68×68×256
(5)第四块: 两次 3×3 卷积 + ReLU 输出 64×64×512
最大池化 2×2 最大池化 下采样为 32×32×512
(6)第五块:(瓶颈层) 两次 3×3 卷积 + ReLU 输出 28×28×1024
import torch
import torch.nn as nn
class unet(nn.Module):
def __init__(self):
super(unet,self).__init__()
#编码器(卷积层以及下采样)
self.conv1_1 = nn.Conv2d(in_channels=1,out_channels=64,kernel_size=3,stride=1,padding=0)
self.relu1_1 = nn.ReLU(inplace=True)
self.conv1_2 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=0)
self.relu1_2 = nn.ReLU(inplace=True)
self.maxpool_1 = nn.MaxPool2d(kernel_size=2,stride=2)
self.conv2_1 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=0)
self.relu2_1 = nn.ReLU(inplace=True)
self.conv2_2 = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=0)
self.relu2_2 = nn.ReLU(inplace=True)
self.maxpool_2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv3_1 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=0)
self.relu3_1 = nn.ReLU(inplace=True)
self.conv3_2 = nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=0)
self.relu3_2 = nn.ReLU(inplace=True)
self.maxpool_3 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv4_1 = nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=0)
self.relu4_1 = nn.ReLU(inplace=True)
self.conv4_2 = nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=0)
self.relu4_2 = nn.ReLU(inplace=True)
self.maxpool_4 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv5_1 = nn.Conv2d(in_channels=512, out_channels=1024, kernel_size=3, stride=1, padding=0)
self.relu5_1 = nn.ReLU(inplace=True)
self.conv5_2 = nn.Conv2d(in_channels=1024, out_channels=1024, kernel_size=3, stride=1, padding=0)
self.relu5_2 = nn.ReLU(inplace=True)
self.maxpool_5 = nn.MaxPool2d(kernel_size=2, stride=2)特征裁剪
在进行解码阶段的同时还要进行裁剪与拼接的操作,这是相对而言较为难理解的一部分。
进行特征裁剪的原因(主要是为了可以拼接)
在UNet的编码器(下采样)路径中,每次池化或卷积操作会减少特征图的空间尺寸(如从256x256变为128x128)。而在解码器(上采样)路径中,需要通过转置卷积或插值恢复原始尺寸。由于编码器和解码器的特征图尺寸不一致,需将编码器中的特征图裁剪至与解码器当前层相同的尺寸,才能进行拼接。
拼接的目的
UNet的核心设计是通过跳跃连接(Skip Connection)将编码器的多尺度特征与解码器的上采样特征拼接。这种操作实现了以下功能:
-
保留低级细节信息:编码器的浅层特征包含边缘、纹理等细节,直接拼接到解码器可弥补上采样过程中的信息损失。
-
融合多尺度特征:通过结合不同层级的特征,网络能同时利用局部和全局信息,提升分割精度(尤其在医学图像中微小结构的识别)。
这一步对应网络结构图中的灰色箭头,详细步骤与代码在下面完整代码部分呈现。
def copy_crop(self,tensor,target_tensor):
target_size = target_tensor.size()[2]
tensor_size = tensor.size()[2]
t = tensor_size - target_size
t=t//2 #用t/2得到的是2.0。用// 是“整数除法”,规则是:先做除法,再向下取整,结果类型永远是 int。
return tensor[:,:,t:tensor_size-t,t:tensor_size-t]代码简单解读:
target_size = target_tensor.size()[2]:取目标张量的宽/高(假设输入是正方形,h=w,因此只拿第 2 维)。
tensor_size = tensor.size()[2]:取待裁剪张量的宽/高。
t = tensor_size - target_size:计算两边一共多出的像素数。
t = t // 2:整数除法,得出单边需要削掉多少行/列。
tensor[:, :, t : tensor_size-t, t : tensor_size-t]:在第二、三维(H、W)上各裁掉 t 个像素,保留中心区域,使其尺寸与 target_tensor 完全一致。维度是从0开始的,切片区间是左闭右开,所以 tensor_size-t 那一行/列不会取到,正好对齐。
解码器
解码器通过转置卷积进行上采样,并与编码器对应层的特征进行拼接(跳跃连接),逐步恢复空间分辨率。
注:详细上采样方法(如转置卷积)知识点请看博主的这篇文章:
(1)上采样1: 2×2 反卷积(转置卷积) 将 28×28×1024 → 56×56×512
拼接1 与编码器第四层输出拼接 56×56×512 + 64×64×512 → 裁剪后拼接为 56×56×1024
卷积1 两次 3×3 卷积 + ReLU 输出 52×52×512
(2)上采样2: 2×2 反卷积 52×52×512 → 104×104×256
拼接2 与编码器第三层输出拼接 裁剪后拼接为 104×104×512
卷积2 两次 3×3 卷积 + ReLU 输出 100×100×256
(3)上采样3: 2×2 反卷积 100×100×256 → 200×200×128
拼接3 与编码器第二层输出拼接 裁剪后拼接为 200×200×256
卷积3 两次 3×3 卷积 + ReLU 输出 196×196×128
(4)上采样4: 2×2 反卷积 196×196×128 → 392×392×64
拼接4 与编码器第一层输出拼接 裁剪后拼接为 392×392×128
卷积4 两次 3×3 卷积 + ReLU 输出 388×388×64
(5)输出层:1×1 卷积(通道=类别数)+ 激活(二分类用 Sigmoid,多分类用 Softmax),原始 valid-conv 单类分割示例输出 388×388×1,实际尺寸/通道随输入大小与任务类别而变。
self.up_conv1 = nn.ConvTranspose2d(in_channels=1024,out_channels=512,kernel_size=2,stride=2,padding=0)
self.conv6_1 = nn.Conv2d(in_channels=1024, out_channels=512, kernel_size=3, stride=1, padding=0)
self.relu6_1 = nn.ReLU(inplace=True)
self.conv6_2 = nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=0)
self.relu6_2 = nn.ReLU(inplace=True)
self.up_conv2 = nn.ConvTranspose2d(in_channels=512, out_channels=256, kernel_size=2, stride=2, padding=0)
self.conv7_1 = nn.Conv2d(in_channels=512, out_channels=256, kernel_size=3, stride=1, padding=0)
self.relu7_1 = nn.ReLU(inplace=True)
self.conv7_2 = nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=0)
self.relu7_2 = nn.ReLU(inplace=True)
self.up_conv3 = nn.ConvTranspose2d(in_channels=256, out_channels=128, kernel_size=2, stride=2, padding=0)
self.conv8_1 = nn.Conv2d(in_channels=256, out_channels=128, kernel_size=3, stride=1, padding=0)
self.relu8_1 = nn.ReLU(inplace=True)
self.conv8_2 = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=0)
self.relu8_2 = nn.ReLU(inplace=True)
self.up_conv4 = nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=2, stride=2, padding=0)
self.conv9_1 = nn.Conv2d(in_channels=128, out_channels=64, kernel_size=3, stride=1, padding=0)
self.relu9_1 = nn.ReLU(inplace=True)
self.conv9_2 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=0)
self.relu9_2 = nn.ReLU(inplace=True)
self.conv10 = nn.Conv2d(in_channels=64,out_channels=2,kernel_size=1,stride=1,padding=0)完整Unet代码(建议读者自己多梳理几遍)
注意前向传播阶段,每一步使用不同的X_i,因为要保存下来,供解码器阶段的裁剪拼接时使用。
import torch
import torch.nn as nn
class unet(nn.Module):
def __init__(self):
super(unet,self).__init__()
#编码器(卷积层以及下采样)
self.conv1_1 = nn.Conv2d(in_channels=1,out_channels=64,kernel_size=3,stride=1,padding=0)
self.relu1_1 = nn.ReLU(inplace=True)
self.conv1_2 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=0)
self.relu1_2 = nn.ReLU(inplace=True)
self.maxpool_1 = nn.MaxPool2d(kernel_size=2,stride=2)
self.conv2_1 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=0)
self.relu2_1 = nn.ReLU(inplace=True)
self.conv2_2 = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=0)
self.relu2_2 = nn.ReLU(inplace=True)
self.maxpool_2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv3_1 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=0)
self.relu3_1 = nn.ReLU(inplace=True)
self.conv3_2 = nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=0)
self.relu3_2 = nn.ReLU(inplace=True)
self.maxpool_3 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv4_1 = nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=0)
self.relu4_1 = nn.ReLU(inplace=True)
self.conv4_2 = nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=0)
self.relu4_2 = nn.ReLU(inplace=True)
self.maxpool_4 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv5_1 = nn.Conv2d(in_channels=512, out_channels=1024, kernel_size=3, stride=1, padding=0)
self.relu5_1 = nn.ReLU(inplace=True)
self.conv5_2 = nn.Conv2d(in_channels=1024, out_channels=1024, kernel_size=3, stride=1, padding=0)
self.relu5_2 = nn.ReLU(inplace=True)
self.maxpool_5 = nn.MaxPool2d(kernel_size=2, stride=2)
self.up_conv1 = nn.ConvTranspose2d(in_channels=1024,out_channels=512,kernel_size=2,stride=2,padding=0)
self.conv6_1 = nn.Conv2d(in_channels=1024, out_channels=512, kernel_size=3, stride=1, padding=0)
self.relu6_1 = nn.ReLU(inplace=True)
self.conv6_2 = nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=0)
self.relu6_2 = nn.ReLU(inplace=True)
self.up_conv2 = nn.ConvTranspose2d(in_channels=512, out_channels=256, kernel_size=2, stride=2, padding=0)
self.conv7_1 = nn.Conv2d(in_channels=512, out_channels=256, kernel_size=3, stride=1, padding=0)
self.relu7_1 = nn.ReLU(inplace=True)
self.conv7_2 = nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=0)
self.relu7_2 = nn.ReLU(inplace=True)
self.up_conv3 = nn.ConvTranspose2d(in_channels=256, out_channels=128, kernel_size=2, stride=2, padding=0)
self.conv8_1 = nn.Conv2d(in_channels=256, out_channels=128, kernel_size=3, stride=1, padding=0)
self.relu8_1 = nn.ReLU(inplace=True)
self.conv8_2 = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=0)
self.relu8_2 = nn.ReLU(inplace=True)
self.up_conv4 = nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=2, stride=2, padding=0)
self.conv9_1 = nn.Conv2d(in_channels=128, out_channels=64, kernel_size=3, stride=1, padding=0)
self.relu9_1 = nn.ReLU(inplace=True)
self.conv9_2 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=0)
self.relu9_2 = nn.ReLU(inplace=True)
self.conv10 = nn.Conv2d(in_channels=64,out_channels=2,kernel_size=1,stride=1,padding=0)
def copy_crop(self,tensor,target_tensor):
target_size = target_tensor.size()[2]
tensor_size = tensor.size()[2]
t = tensor_size - target_size
t=t//2 #用t/2得到的是2.0。用// 是“整数除法”,规则是:先做除法,再向下取整,结果类型永远是 int。
return tensor[:,:,t:tensor_size-t,t:tensor_size-t]
def forward(self,x):
#编码器
x1 = self.conv1_1(x)
x1 = self.relu1_1(x1)
x1 = self.conv1_2(x1)
x1 = self.relu1_2(x1)
down1 = self.maxpool_1(x1)
x2 = self.conv2_1(down1)
x2 = self.relu2_1(x2)
x2 = self.conv2_2(x2)
x2 = self.relu2_2(x2)
down2 = self.maxpool_2(x2)
x3 = self.conv3_1(down2)
x3 = self.relu3_1(x3)
x3 = self.conv3_2(x3)
x3 = self.relu3_2(x3)
down3 = self.maxpool_3(x3)
x4 = self.conv4_1(down3)
x4 = self.relu4_1(x4)
x4 = self.conv4_2(x4)
x4 = self.relu4_2(x4)
down4 = self.maxpool_4(x4)
x5 = self.conv5_1(down4)
x5 = self.relu5_1(x5)
x5 = self.conv5_2(x5)
x5 = self.relu5_2(x5) #1024
#解码器
up1 = self.up_conv1(x5)
crop1 = self.copy_crop(x4,up1)
up_1 = torch.cat([crop1,up1],dim=1)
x6 = self.conv6_1(up_1)
x6 = self.relu6_1(x6)
x6 = self.conv6_2(x6)
x6 = self.relu6_2(x6)
up2 = self.up_conv2(x6)
crop2 = self.copy_crop(x3, up2)
up_2 = torch.cat([crop2, up2], dim=1)
x7 = self.conv7_1(up_2)
x7 = self.relu7_1(x7)
x7 = self.conv7_2(x7)
x7 = self.relu7_2(x7)
up3 = self.up_conv3(x7)
crop3 = self.copy_crop(x2, up3)
up_3 = torch.cat([crop3, up3], dim=1)
x8 = self.conv8_1(up_3)
x8 = self.relu8_1(x8)
x8 = self.conv8_2(x8)
x8 = self.relu8_2(x8)
up4 = self.up_conv4(x8)
crop4 = self.copy_crop(x1, up4)
up_4 = torch.cat([crop4, up4], dim=1)
x9 = self.conv9_1(up_4)
x9 = self.relu9_1(x9)
x9 = self.conv9_2(x9)
x9 = self.relu9_2(x9)
out = self.conv10(x9)
return out
补充
一般在Unet网络中会加入BN(批归一化处理)层,来提高模型的效果。BN 能加速收敛、缓解深层梯度消失,对 U-Net 这种 20+ 层 Conv 网络非常有效。
每Conv→BN→ReLU(俗称“CBR”顺序),即卷积做完立刻批归一化,再送激活函数。简单示例如下:
self.conv1_1 = nn.Conv2d(1, 64, 3, 1, 0)
self.bn1_1 = nn.BatchNorm2d(64)
self.relu1_1 = nn.ReLU(inplace=True)注:BN层的详细介绍请看博主的这篇文章:
后续会更新Unet简单实战,DRIVE数据集的训练。
敬请期待。



















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









