



一、剪枝的概念
剪枝是一种模型压缩技术,通过移除神经网络中冗余或不重要的连接、神经元或整个层,减少模型大小和计算量。其核心思想是识别并删除对模型性能影响较小的参数,同时尽量保持模型精度。
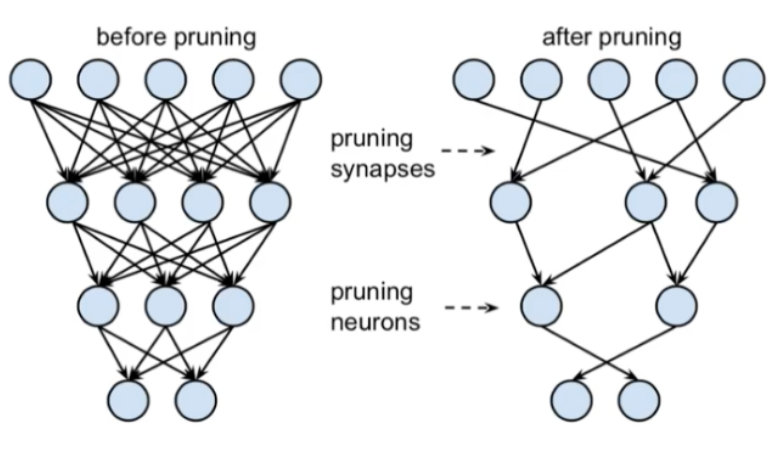
二、剪枝的作用
(1)减少模型大小:降低存储和传输成本,便于部署在资源受限的设备上。
(2)加速推理:减少计算量,提升推理速度。
(3)降低过拟合风险:移除冗余参数可能提升模型泛化能力。
三、剪枝使用场景
(1)边缘设备部署:如移动端、嵌入式设备等计算资源有限的环境。
(2)实时性要求高的场景:需要低延迟推理的任务(如自动驾驶、视频处理)。
(3)大型模型优化:对参数量巨大的模型(如BERT、ResNet)进行轻量化处理。
四、分类以及对应的代码示例(基于pytorch)
这里按“剪什么”——粒度/结构来分类
非结构化剪枝:
通过移除模型中不重要的权重或神经元来减少计算量和参数数量。与结构化剪枝不同,非结构化剪枝不依赖于预定义的结构(如整个通道或层),而是独立评估每个权重的重要性,允许更细粒度的剪枝。但得靠专用硬件才能真的跑得快。
特点:
(1)细粒度剪枝:操作对象是单个权重或神经元,而非整个层或通道,灵活性更高。
(2)稀疏性引入:剪枝后模型权重矩阵呈现稀疏性,可能生成大量零值,需借助稀疏计算库(如CUDA稀疏核)加速推理。
(3)依赖评估准则:通常基于权重大小(如L1范数)、梯度信息或二阶导数(Hessian矩阵)判断重要性。
基于 torch.nn.utils.prune 实现随机非结构化剪枝:
import torch
import torch.nn as nn
import torch.nn.utils.prune as prune
# 定义简单模型
model = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10)
)
# 对第一层权重进行随机剪枝(剪枝比例30%)
prune.random_unstructured(model[0], name="weight", amount=0.3)
# 检查稀疏性
print(f"稀疏度: {100 * torch.sum(model[0].weight == 0) / model[0].weight.numel():.2f}%")
# 永久移除剪枝的权重(可选)
prune.remove(model[0], "weight")
函数参数解释:
model[0]:
指定需要剪枝的模块。model[0] 表示模型的第一个层(如 nn.Linear 或 nn.Conv2d)。剪枝操作将直接作用于该层的权重或偏置。
name="weight":
指定剪枝的目标参数。默认值为 "weight",表示对权重矩阵进行剪枝。也可以设置为 "bias",表示对偏置进行剪枝。目标参数必须是模块的可学习参数(如 nn.Module 的 weight 属性)。
amount=x:
x指定剪枝比例,范围为 [0, 1]。0.3 表示剪枝 30% 的参数。例如,若权重矩阵有 100 个元素,剪枝后将保留 70 个,其余 30 个被置零。
结构化剪枝
通过移除网络中冗余的结构化单元(如整个滤波器、通道、层或块),显著减少模型参数量和计算量,同时保持网络架构的完整性。与非结构化剪枝(移除单个权重)不同,结构化剪枝更易于硬件加速,适合实际部署。
特点:
(1)结构化单元移除:剪枝对象为完整的滤波器、通道或层,而非单个连接。例如,在卷积层中移除整个输出通道,对应输入通道的卷积核也会被移除。
(2)硬件友好性:剪枝后的模型可直接运行在标准硬件(如GPU)上,无需定制稀疏计算库。
(3)粒度可控:支持从细粒度(通道/滤波器)到粗粒度(整个层)的剪枝,平衡精度与效率。
使用 torch-pruning 库剪枝整个通道:
# 需安装 torch-pruning: pip install torch-pruning
import torch
import torch.nn as nn
import torch_pruning as tp
model = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.AdaptiveAvgPool2d(1)
)
# 定义剪枝策略(剪枝50%的通道)
strategy = tp.strategy.L1Strategy()
pruning_plan = strategy(model[0], amount=0.5)
# 执行剪枝
tp.prune(pruning_plan)
# 检查输出通道数
print(f"剪枝后通道数: {model[0].out_channels}")
五、使用的时机
非结构化剪枝的使用时机
非结构化剪枝(移除单个权重或神经元)可在模型训练的不同阶段应用,具体取决于目标(如压缩模型、加速推理或减少过拟合)。
训练前剪枝(初始化阶段)
作用:在训练开始前对模型权重进行剪枝,通常基于某种初始化规则(如小权重移除)。
适用场景:希望从一开始就减少模型复杂度,或探索稀疏架构。
代码示例(PyTorch):
import torch.nn.utils.prune as prune
model = MyModel() # 假设已定义模型
# 对某层(如fc1)进行随机剪枝,比例20%
prune.random_unstructured(model.fc1, name='weight', amount=0.2)
# 永久移除剪枝的权重(否则mask会保留)
prune.remove(model.fc1, 'weight')
训练中剪枝(动态剪枝)
作用:在训练过程中定期剪枝,结合梯度信息动态调整稀疏度。
适用场景:需要逐步优化模型结构,避免一次性剪枝导致性能骤降。
代码示例:
for epoch in range(epochs):
model.train()
# ...训练逻辑...
if epoch % 5 == 0: # 每5轮剪枝一次
prune.l1_unstructured(model.conv1, name='weight', amount=0.1)
训练后剪枝(微调阶段)
作用:在模型训练完成后剪枝,通常需微调以恢复精度。
适用场景:追求推理效率,且有时间进行剪枝后微调。
代码示例:
pretrained_model = load_pretrained()
# 对全连接层剪枝50%
prune.ln_unstructured(model.fc2, name='weight', amount=0.5, n=2)
# 微调剪枝后的模型
fine_tune(model)
fine_tune不是内置函数,是指“对已经剪枝完的模型再跑一段小规模训练,用很小学习率把精度追回来。”
判断剪枝作用层的方法:
基于敏感度分析:逐层剪枝并评估验证集损失,选择对精度影响较小的层。
参数量分布:参数量大或计算成本高的层(如全连接层)优先剪枝。
稀疏度目标:某些层(如浅层卷积)可能需保留更高密度以提取基础特征。
敏感度分析示例:
for name, module in model.named_modules():
if isinstance(module, torch.nn.Linear):
original_accuracy = evaluate(model)
prune.l1_unstructured(module, name='weight', amount=0.2)
new_accuracy = evaluate(model)
print(f"{name} 剪枝后精度下降: {original_accuracy - new_accuracy:.2f}%")
prune.remove(module, 'weight') # 恢复原始权重
结构化剪枝的使用时机
结构化剪枝的时机
结构化剪枝通常在模型训练的不同阶段实施,具体时机取决于目标需求。训练前剪枝适用于轻量化初始模型,训练中剪枝通过动态调整稀疏性平衡精度与效率,训练后剪枝则用于压缩已训练好的模型。测试阶段需加载剪枝后模型进行评估。
剪枝阶段与层选择方法
训练前剪枝
通过预设规则(如卷积核的L1范数)直接初始化稀疏模型。适合计算资源有限且对精度要求不高的场景。
import torch.nn.utils.prune as prune
model = ResNet18()
# 对卷积层进行L1结构化剪枝(保留前30%的通道)
prune.ln_structured(
module=model.conv1,
name="weight",
amount=0.7,
n=1,
dim=0 # 沿通道维度剪枝
)
训练中剪枝
在反向传播期间动态修剪权重,结合重训练恢复性能。典型方法如迭代式剪枝,每N个epoch调整一次稀疏度。
for epoch in range(epochs):
train(model)
if epoch % 5 == 0: # 每5轮剪枝一次
for layer in model.modules():
if isinstance(layer, nn.Conv2d):
prune.l1_unstructured(
layer, name="weight", amount=0.2
)
训练后剪枝
基于预训练模型的权重重要性进行剪枝,常需微调。层选择依赖敏感度分析:逐层剪枝后验证精度下降,优先保留敏感层(如靠近输出的层)。
# 敏感度分析示例
baseline_acc = evaluate(model)
for name, module in model.named_modules():
if isinstance(module, nn.Conv2d):
prune.random_structured(module, name="weight", amount=0.3, dim=0)
acc = evaluate(model)
print(f"{name} 剪枝后精度下降: {baseline_acc - acc:.2f}%")
prune.remove(module, 'weight') # 撤销临时剪枝
# 正式剪枝敏感度最低的层
prune.ln_structured(model.conv3, name="weight", amount=0.4, n=2, dim=0)
fine_tune(model) # 微调恢复性能
测试阶段注意事项
测试时需使用prune.remove永久应用剪枝,或通过forward_pre_hooks保持动态剪枝。剪枝层输出维度变化可能影响后续层,需检查模型结构的连贯性。示例:
prune.remove(model.conv1, 'weight')
test_acc = evaluate(model) # 使用剪枝后的固定结构
六、剪枝与Dropout的区别
剪枝(Pruning)和Dropout是深度学习中两种不同的正则化技术,用于防止模型过拟合,但工作机制和适用场景存在显著差异。
剪枝:
-
通过移除神经网络中不重要的权重或神经元(如权重接近零的节点)来简化模型结构。
-
通常在模型训练完成后进行,属于后处理步骤。
-
直接减少模型参数量,提升推理效率。
-
适用于需要模型轻量化的场景(如嵌入式设备)。
Dropout:
-
在训练过程中随机屏蔽(置零)一部分神经元的输出,迫使网络不依赖特定神经元。
-
属于动态正则化,仅在训练时激活,推理时所有神经元均参与计算。
-
通过引入随机性提升模型泛化能力,但不会减少参数量。
-
适用于训练大规模网络时的过拟合抑制。
剪枝的典型场景:
-
模型部署到资源受限的设备(如移动端、IoT设备)。
-
需要减少模型存储空间或计算延迟。
-
结合量化技术进一步压缩模型(如TensorRT优化)。
Dropout的典型场景:
-
训练大型全连接网络(如Transformer的FFN层)。
-
数据量较小但模型容量较大的任务(如医学图像分类)。
-
与其他正则化方法(如权重衰减)联合使用。
选择建议
当目标是模型压缩和推理加速时,优先考虑剪枝。
当目标是提高训练泛化性且资源充足时,优先使用Dropout。
两者可结合使用:先通过Dropout训练鲁棒模型,再对训练好的模型剪枝优化。


















 3959
3959




 到【灌水乐园】发言
到【灌水乐园】发言







