






最近很多人在聊MCP,但大多数都在讲MCP中的“服务端”、“客户端”的概念。但有些开发者仍然是一头雾水,搞不懂MCP到底是什么,也不知道如何在开发中应用MCP。接下来,本文将揭开MCP的神秘面纱,带你彻底搞懂MCP。
一、LLM的函数调用(Function Calling)
这一篇文章中解读了OpenManus的代码
从代码中,我们可以发现,实现Manus的关键思路,就是学会让模型调用函数工具。OpenManus通过四个核心函数工具实现了智能体的所有操作,分别为:
-
执行Python函数
-
谷歌搜索
-
操作浏览器
-
保存文件
OpenManus首先会对任务进行拆解,让模型规划应该调用哪些函数工具,何时调用函数工具,以及如何填写函数工具的参数。
因此,让LLM学会调用函数工具,是智能体的关键。
让LLM学会调用工具,步骤如下:
(1)写好函数工具
开发者需要在本地写好函数工具,例如,如果想让LLM学会查询天气,我们需要在本地写好一个查询天气的函数
(2)写好函数的介绍(这个很关键)
LLM将会函数的介绍,理解函数的作用。函数介绍包括:函数的作用、参数的类型、参数的作用等。例如,DeepSeek的函数介绍格式如下:
tools =[
{
"type":"function",
"function":{
"name":"get_weather",
"description":"Get weather of an location, the user shoud supply a location first",
"parameters":{
"type":"object",
"properties":{
"location":{
"type":"string",
"description":"The city and state, e.g. San Francisco, CA",
}
},
"required":["location"]
},
}
},
]这是一个天气查询的函数,参数为location,LLM将会通过这些介绍,学会如何调用函数。
(3)解析响应,并在本地执行函数
若DeepSeek认为当前应该调用函数,则会输出参数的填写方式,格式如下:
{
"message": {
"role": "assistant",
"content": "",
"tool_calls": [{
"index": 0,
"id": "call 0_c2fd458f-b1e3-43a0-b76a-c9138e609678",
"type": "function",
"function": {
"name": "get_weather",
"arguments": "{\"location\":\"Beijing\"}"
}
}]
}
}我们可以通过解析message中是的tool_calls字段,将DeepSeek给出的参数填写在函数中,并在本地执行函数。
(4)LLM根据运行结果进行总结并回复
最后把函数执行的结果反馈给DeepSeek,DeepSeek再整理执行结果,给出回复。
在这个过程中,会遇到一些问题:
对于DeepSeek来说,这个功能是不稳定的,DeepSeek团队也表示正在积极修复。

对于不同模型来说,不同模型的函数介绍格式不同、返回的参数格式不同。如果我们的项目中需要兼容DeepSeek、GPT、Grok等多家不同的模型,那我们就需要针对每一家模型设置参数解析的格式,增加了开发的工作量。
二、MCP
MCP,全称Model Context Protocol(模型上下文协议),是一个开放、基于共识的协议,由Claude(Anthropic)领导,旨在帮助AI模型(如LLM)与各种工具、服务和数据库进行标准化交互。它通过MCP服务器使AI模型能以统一方式调用外部能力,而无需为每个集成编写自定义代码。这似乎能提高AI应用的开发效率和可靠性。
讲人话,MCP就是一个扩展坞,兼容不同模型的参数格式,方便我们调用。
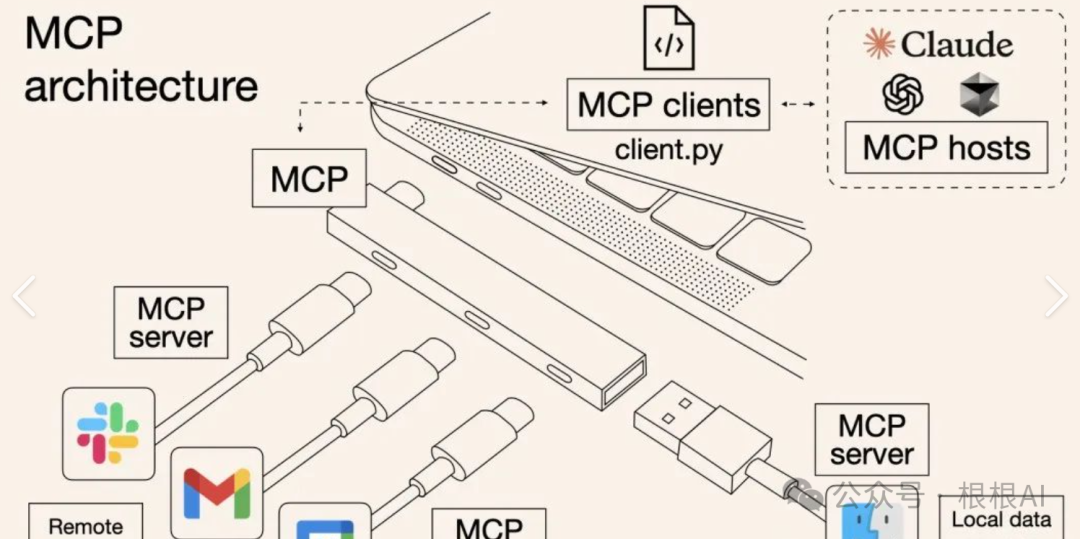
那么问题又来了,MCP是如何兼容这么多模型的格式的?
难道是MCP已经帮我们预设好了每家模型的格式?
其实不然,MCP使用了更巧妙的办法。
我们可以分析一段MCP官方给出的代码示例
https://github.com/modelcontextprotocol/python-sdk/blob/main/examples/clients/simple-chatbot/mcp_simple_chatbot/main.py#L196
all_tools = []
for server in self.servers:
tools = await server.list_tools()
all_tools.extend(tools)
tools_description = "\n".join([tool.format_for_llm() for tool in all_tools])
system_message = (
"You are a helpful assistant with access to these tools:\n\n"
f"{tools_description}\n"
"Choose the appropriate tool based on the user's question. "
"If no tool is needed, reply directly.\n\n"
"IMPORTANT: When you need to use a tool, you must ONLY respond with "
"the exact JSON object format below, nothing else:\n"
"{\n"
' "tool": "tool-name",\n'
' "arguments": {\n'
' "argument-name": "value"\n'
" }\n"
"}\n\n"
"After receiving a tool's response:\n"
"1. Transform the raw data into a natural, conversational response\n"
"2. Keep responses concise but informative\n"
"3. Focus on the most relevant information\n"
"4. Use appropriate context from the user's question\n"
"5. Avoid simply repeating the raw data\n\n"
"Please use only the tools that are explicitly defined above."
)方便起见,我们翻译一些系统提示词:
您是一个有用的助手,可以访问这些工具:
{tools_description}
根据用户的问题选择合适的工具。如果不需要工具,请直接回复。
重要提示:当您需要使用工具时,您必须只回复下面确切的JSON对象格式,不回复别的内容:
{
"tool": "tool-name",
"arguments": {
"argument-name": "value"
}
}
收到执行结果后:
1.将原始数据转换为自然的对话式响应
2.保持回答简洁但信息丰富
3.关注最相关的信息
4.使用用户问题中的适当上下文
5.避免简单地重复原始数据
你只能使用上面明确定义的工具。看到这里,你是不是恍然大悟。
MCP实际上就是把函数的介绍写在了系统提示词里。
对于Function Calling来说,我需要把函数的参数填到请求参数tools里面,这些函数最终以什么样的方式输入到模型里,这个过程是不透明的,解析tools的工作是在云端进行的,返回的格式也是在云端定义的。我们只能通过官方文档来确定返回参数的格式。
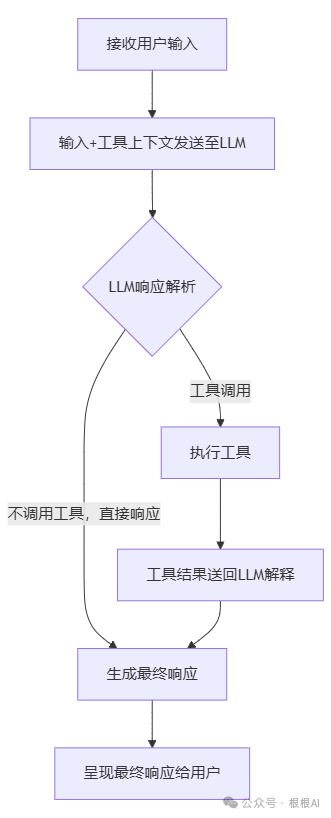
而MCP很巧妙的绕过了云端解析tools的过程。MCP把函数的介绍、参数的返回格式都写在了系统提示里面,这样一来,只要LLM能够理解系统提示词,就能够按照提示词定义的格式输出。这就实现了格式的统一。
在理解了MCP的原理后,我们就能很清晰地解释MCP的服务端和客户端了:
✅MCP服务端就是执行函数工具的场所。
✅MCP客户端就是与LLM交互的场所,包括介绍函数和获取函数的参数
对于大多数的开发者来说,需要开发的是MCP客户端,MCP服务端中常用的函数工具、数据查询工具等已经由社区的开发者们开发好了,可以直接进行调用。
而在MCP客户端中,开发者根据业务流程,让LLM选择合适的函数工具进行调用,最终实现业务逻辑。



















 1589
1589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











