







一、实验目的
- (1)熟悉银河操作系统下 C++程序的编辑、编译和运行,理解计算机体系结关系。
- (2)了解 MPI 分布式内存并行和 OpenMP 共享内存并行的基本特点
二、实验说明
- 了解 VPN,远程登陆,远程文件传输;
- 在天河新一代系统上测试字节序和分预测效果;
- 根据知识库中的指导,运行“MPI 矩阵乘编程 DEMO” 和 “OpenMP 并行演示程序”
三、实验内容
1、配置并登录天河新一代 VPN
1)使用 Easy Connect 客户端登录超算中心 VPN
-
使用 Web 浏览器访问 https://218.77.58.134/,点击“下载客户端”按钮,下载并安装与操作系统匹配的客户端

-
打开安装好的 Easy Connect 客户端,填写地址https://218.77.58.134/ 后按回车键继续

-
分别在用户名和密码框内填入中心提供的 VPN 账号及密码,然后输入图形验证码并点击登录

-
“默认资源组”显示用户可访问的系统与对应的访问 IP,如“天河新一代”、“知识库系统”等。

2)使用SSH 客户端登录超算系统
使用 SSH 客户端登录系统,如下图以 MobaXterm 为例:
-
首先安装MobaXterm,教程:MobaXterm(终端工具)下载&安装&使用教程-【优快云】
-
点击 Session(新建会话)

-
点击 SSH、输入相应 IP地址(“默认资源组”中有相应显示)和用户名、点击 OK
- 上面“天河新一代”的IP为25.8.100.24-25.8.100.26:组内多人的,可输入不同的IP地址(我用的25.8.100.25,另外25.8.100.24好像是不行的)。用户名输入申请的“账号名”;

- 上面“天河新一代”的IP为25.8.100.24-25.8.100.26:组内多人的,可输入不同的IP地址(我用的25.8.100.25,另外25.8.100.24好像是不行的)。用户名输入申请的“账号名”;
-
最后在终端输入密码(账号和密码是发到组长邮箱里的):

- 点击YES,保存登录密码,下次登录就不需要再输入登录密码了:(也可以选No)
 - 主密码用于加密所有存储的密码
- 主密码用于加密所有存储的密码 
- 点击YES,保存登录密码,下次登录就不需要再输入登录密码了:(也可以选No)
-
登录成功

2、远程登录天河新一代,上传测试代码
-
点击“↑”箭头

-
选中“字节序文件”后,即上传到远端(后面需要编译运行,需要上传.c文件;而且这里只有gcc,没有g++,所以不能编译c++文件);分支预测的代码同理


-
字节序代码(指导书给的代码)
void byteorder()
{
union
{
short value;
char union_bytes[sizeof(short)];
}test;
test.value = 0x0102;
if (sizeof(short) == 2)
{
if (test.union_bytes[0] == 1 && test.union_bytes[1] == 2)
cout << "big endian" << endl;
else if (test.union_bytes[0] == 2 && test.union_bytes[1] == 1)
cout << "little endian" << endl;
else
cout << "unknown" << endl;
}
else
{
cout << "sizeof(short) == " << sizeof(short) << endl;
}
return ;
}
- 字节序代码(修改后的:改为main函数,c形式的输入输出)
#include <stdio.h>
// void byteorder()
int main()
{
union
{
short value;
char union_bytes[sizeof(short)];
}test;
test.value = 0x0102;
if (sizeof(short) == 2)
{
if (test.union_bytes[0] == 1 && test.union_bytes[1] == 2)
printf("big endian\n");
else if (test.union_bytes[0] == 2 && test.union_bytes[1] == 1)
printf("little endian\n");
else
printf("unknown\n");
}
else
{
printf("sizeof(short) == %ld",sizeof(short) );
}
return 0;
}
- 分支预测代码(指导书给的代码)
#include <algorithm>
#include <ctime>
#include <iostream>
int main()
{
// 随机产生整数,用分区函数填充,以避免出现分桶不均
const unsigned arraySize = 32768;
int data[arraySize];
for (unsigned c = 0; c < arraySize; ++c)
data[c] = std::rand() % 256;
// !!! 排序后下面的Loop运行将更快
std::sort(data, data + arraySize);
// 测试部分
clock_t start = clock();
long long sum = 0;
for (unsigned i = 0; i < 100000; ++i)
{
// 主要计算部分,选一半元素参与计算
for (unsigned c = 0; c < arraySize; ++c)
{
if (data[c] >= 128)
sum += data[c];
}
}
double elapsedTime = static_cast<double>(clock() - start) / CLOCKS_PER_SEC;
std::cout << elapsedTime << std::endl;
std::cout << "sum = " << sum << std::endl;
}
- 分支预测代码(修改后的:改为c形式的输入输出;algorithm,ctime都得改成c形式的;后面要求记录两种不同情况下的运行结果,所以排序前后的结果分别输出)
#include <stdlib.h>
#include <time.h>
#include <stdio.h>
int comp(const void*a,const void*b)
{
return *(int*)a-*(int*)b;
}
int main()
{
// 随机产生整数,用分区函数填充,以避免出现分桶不均
const unsigned arraySize = 32768;
int data[arraySize];
unsigned c = 0;
for (; c < arraySize; ++c)
data[c] = rand() % 256;
printf("Before sorted:\n");
// 测试部分
clock_t start = clock();
long long sum = 0;
unsigned i = 0;
for (; i < 100000; ++i)
{
// 主要计算部分,选一半元素参与计算
c = 0;
for (; c < arraySize; ++c)
{
if (data[c] >= 128)
sum += data[c];
}
}
double elapsedTime = (double)(clock() - start) / CLOCKS_PER_SEC;
printf("%f\n",elapsedTime);
printf( "sum = %lld\n" ,sum );
printf("\nAfter sorted:\n");
// !!! 排序后下面的Loop运行将更快
qsort(data, arraySize,sizeof(int),comp);
// 测试部分
start = clock();
sum = 0;
i = 0;
for (; i < 100000; ++i)
{
// 主要计算部分,选一半元素参与计算
c = 0;
for (; c < arraySize; ++c)
{
if (data[c] >= 128)
sum += data[c];
}
}
elapsedTime = (double)(clock() - start) / CLOCKS_PER_SEC;
printf("%f\n",elapsedTime);
printf( "sum = %lld\n" ,sum );
}
3、编译两个程序
-
配置gcc
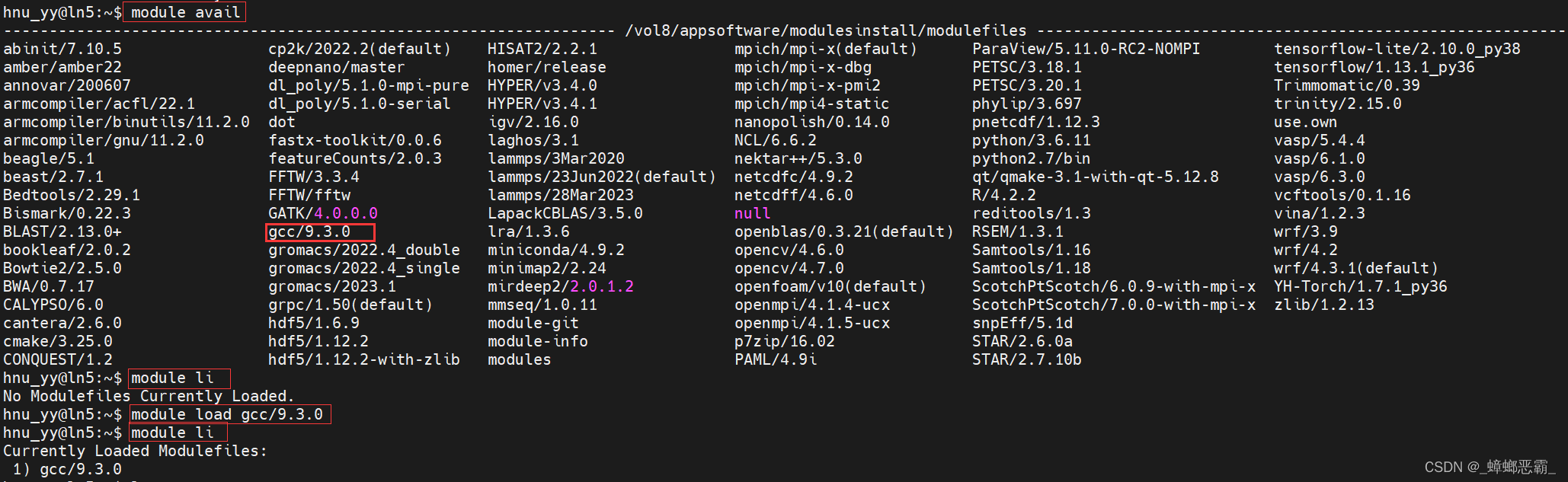
- 命令 module av :查看系统已安装软件、模块、函数库等;
- 命令module load :载入相应模块;
- 命令 module li :查看已载入模块
-
编译:
- c语言没有algorithm的sort,而是stdlib的qsort;也没有ctime,而是time.h;
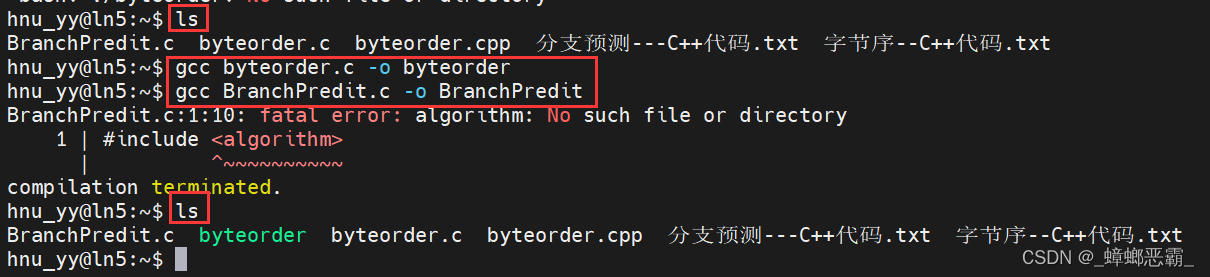
- 分支预测的代码修改后通过:

- c语言没有algorithm的sort,而是stdlib的qsort;也没有ctime,而是time.h;
4、字节序测试
1) 运行字节序测试程序,请截图,记录程序输出
运行结果:little endian

2) 根据程序输出,判定字节序类型,并说明理由
字节序类型:小端;
- 理由:测试程序的数据为0x0102;
- 若为小端类型:则 数据低位 存储在 地址低位;而short为2字节,所以数据的低2字节【0x02】存储在地址的低位bytes[0];
- 若为大端类型:则 数据低位 存储在 地址高位;而short为2字节,所以数据的低2字节【0x02】存储在地址的高位bytes[1];
union
{
short value;
char union_bytes[sizeof(short)];
}test;
test.value = 0x0102;
if (sizeof(short) == 2)
{
if (test.union_bytes[0] == 1 && test.union_bytes[1] == 2)
printf("big endian\n");
else if (test.union_bytes[0] == 2 && test.union_bytes[1] == 1)
printf("little endian\n");
else
printf("unknown\n");
}
else
{
printf("sizeof(short) == %ld",sizeof(short) );
}
5、分支预测性能测试
1)运行分支预测程序,截屏、记录两种不同情况下的运行结果
运行结果:差了大概2.48倍

2) 请截图,展示执行完以上操作后整个 cache 系统的状态
点击“Remote monitoring”,能看到服务器的资源(CPU、RAM、Network、disk…) 使用情况
Remote-monitoring information for session 25.8.100.25 (hnu_yy)
CPU:
Current CPU load: 9%RAM:
Total RAM: 127079 MB
Used RAM: 18657 MB
Available RAM: 108421 MB
Cached RAM: 2164 MB
Buffers: 537 MB
6、 根据知识库指导,运行 MPI 并行和 OpenMP 并行程序:
-
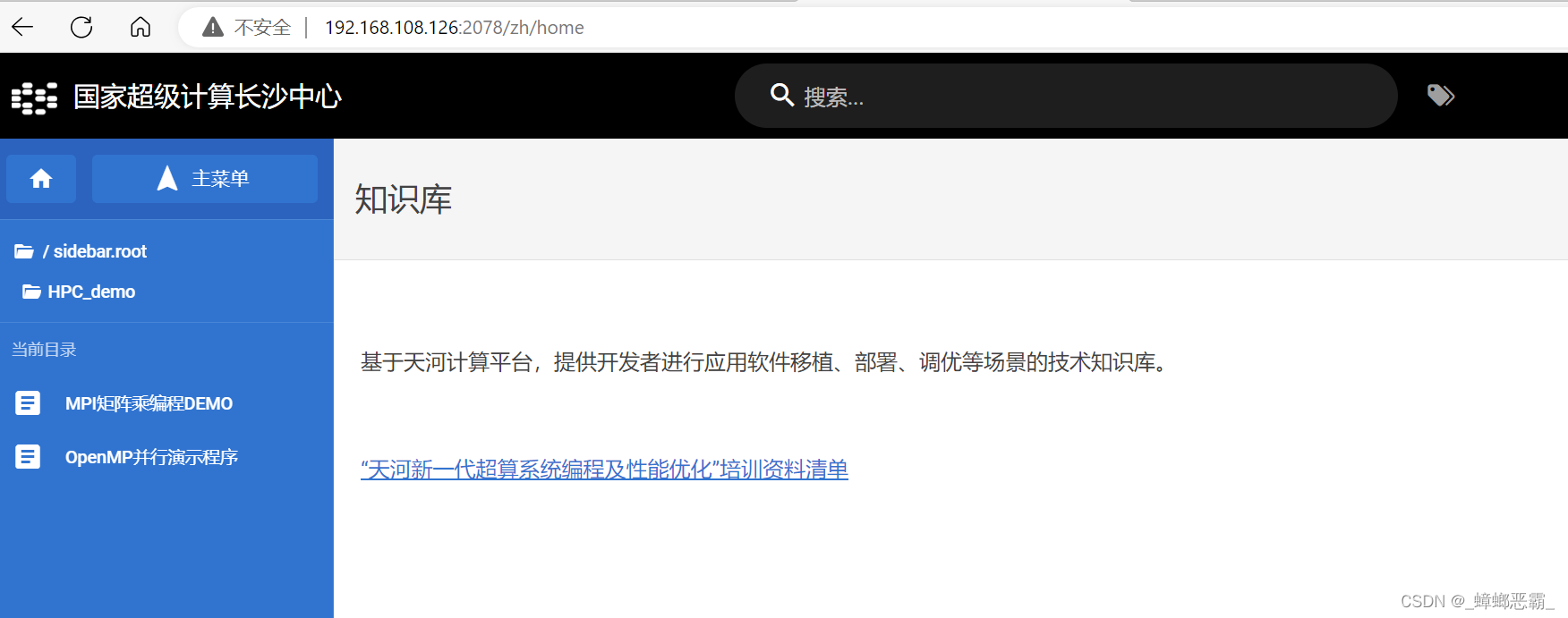
在 VPN 登录情况下,在浏览器中打开知识库网页; 知识库 | 国家超级计算长沙中心,进入主页。
-
点击浏览,出现主菜单:
-
点击左侧目录 HPC_demo,出现两个子目录“MPI 矩阵乘编程 DEMO”和“OpenMP 并行演示程序”
7、分别进入两目录,分析并行效果
分别进入“MPI 矩阵乘编程 DEMO”和“OpenMP 并行演示程序”目录,
按指南对源程序进行编辑、编译;修改脚本、提交任务;记录结果,分析并行效果。
1)MPI 矩阵乘编程 DEMO
-
1.配置环境
- “知识库”中的环境准备,需要gcc和openmpi:

- 使用命令module配置

- “知识库”中的环境准备,需要gcc和openmpi:
-
2.上传、解压文件:上传跟上面类似,使用“↑”箭头;解压见下:
tar -xvzf multi_matrix_demo.tar.gz

-
3.编译:先切换到multi_matrix_demo文件夹下,再gcc编译
gcc -o matrix_s matrix_s.c;mpicc -o matrix_p matrix_p.c

-
4.编辑脚本
- (1)直接运行给定的脚本会出错
- 其实英语好的话,这里就知道因为“批处理作业提交失败:不允许用户组使用此分区”,也就不用下面的试错了。但一开始没看出来,就隐约记住了not permitted

- 其实英语好的话,这里就知道因为“批处理作业提交失败:不允许用户组使用此分区”,也就不用下面的试错了。但一开始没看出来,就隐约记住了not permitted
- (2)“指南”中也说需要编辑:

- (3)去《手册》找为什么:按给的步骤需要先查看资源,再编写脚本,再用yhbatch提交任务;

- (4) yhi查看资源:

- 找不同:分区、节点数不一样;之前隐约记得有个“不许可”,所以就怀疑是分区的问题

- 找不同:分区、节点数不一样;之前隐约记得有个“不许可”,所以就怀疑是分区的问题
- (5)修改脚本:把分区改成自己的分区即可(双击.sh文件,打开直接修改就可以)

- (1)直接运行给定的脚本会出错
-
5.运行程序
yhbatch ./matrix_p.sh
-
6.查看运行结果
- 运行后会在当前目录输出slurm-xxxxx.out的文件,xxxx一般为jobid,可以用cat命令查看输出内容
- 这里xxxxx就是1895361:
cat slurm-1895361.out
- 串行运行结果:计算两个1024*1024的A,B矩阵(两个矩阵的大小需要输入运行指令后,手动输入1024 1024)乘积所费的时间为:47.205643秒;
./matrix_s

- 对比:
- 串行结果47.205643,而通过mpi并行规模为12核的并行程序计算只需要8.907275秒;
- 可以看出并行加速比为约5.30,并行计算效率为5.30/12=44%
2)OpenMP 并行演示程序
分别创建文件parallelMatrix.c,paraPi.c,fft.c,并把代码复制进去:(代码在“OpenMP 并行演示程序”目录里)

- 1.parallelMatrix.c
- 编译运行
gcc -g -O0 -fopenmp -std=c99 parallelMatrix.c -o gccpara.out./gccpara.out
- 运行结果:

- 作图

- 作图程序
- 编译运行
import matplotlib
import numpy as np
import matplotlib.pyplot as plt
matplotlib.rc("font", family='Microsoft YaHei')
xpoints = np.array([1, 2, 4, 8,32,48,60])
# times = np.array([49.437591,25.199742,12.801155,6.695927,2.662523,2.528642,2.86362])
times = np.array([120.072972,62.014002,32.736311,16.249100,4.903782,3.590005,2.937059])
speedup = times[0] / times
print(speedup)
parallel_efficiency = speedup / xpoints
print(parallel_efficiency)
plt.title('运行统计')
plt.plot(xpoints, times,label="running time(s)",color='b')
plt.plot(xpoints, speedup,label='speedup',color='r')
plt.plot(xpoints, parallel_efficiency,label='parallel_efficiency',color='k')
plt.legend()
plt.show()
-
2.paraPi.c
- 编译运行
- “知识库”中给的编译命令
gcc -g -O0 -lm -fopenmp paraPi.c -o gccpara.out,但用这个会报错:

- 原因:gcc 编译错误:"undefined reference to ‘sqrt’
- gcc默认指定的有几个库文件,比如libstd。但是不包括math的库,所需要的math库不是gcc默认指定的,所以需要手动连接math库,需要在编译的时候加上一个-lm选项。
- -l是指定XXX库,m就指math库。即:gcc hello.c -lm -lm就是链接到math库的问题。
- 然后试错过程中,发现把“-lm”放到最后就可以编译成功了:
gcc -g -O0 -fopenmp paraPi.c -o gccpara.out -lm

- “知识库”中给的编译命令
原因说明:
- 编译指令说明:
gcc:调用 GCC 编译器。-g: 生成调试信息。-O0: 禁用优化(保持代码尽可能的原始形式,便于调试)。-lm: 链接数学库 libm。-fopenmp: 启用 OpenMP 支持,用于并行编程。paraPi.c: 源文件。-o gccpara.out: 指定输出的可执行文件名。
- 错误原因:
gcc -g -O0 -lm -fopenmp paraPi.c -o gccpara.out- 命令行参数的顺序会影响 GCC 如何处理这些参数,特别是在链接阶段。
- 当
-lm出现在源文件之前时,链接器可能会找不到需要的符号,导致编译失败。 - 正确的顺序是先指定源文件,然后指定需要的库文件,这样才能确保链接阶段能够找到并使用这些库中的符号
-
./gccpara.out -
运行结果:

-
作图

-
作图程序
- 编译运行
import matplotlib
import numpy as np
import matplotlib.pyplot as plt
matplotlib.rc("font", family='Microsoft YaHei')
xpoints = np.array([1, 2, 4, 8,32,48,60])
# times = np.array([49.437591,25.199742,12.801155,6.695927,2.662523,2.528642,2.86362])
times = np.array([17.638941,9.835184,4.922509,2.472987,0.652800,0.468996,0.484045])
speedup = times[0] / times
print(speedup)
parallel_efficiency = speedup / xpoints
print(parallel_efficiency)
plt.title('运行统计')
plt.plot(xpoints, times,label="running time(s)",color='b')
plt.plot(xpoints, speedup,label='speedup',color='r')
plt.plot(xpoints, parallel_efficiency,label='parallel_efficiency',color='k')
plt.legend()
plt.show()
- 3.fft.c
- 编译运行
-
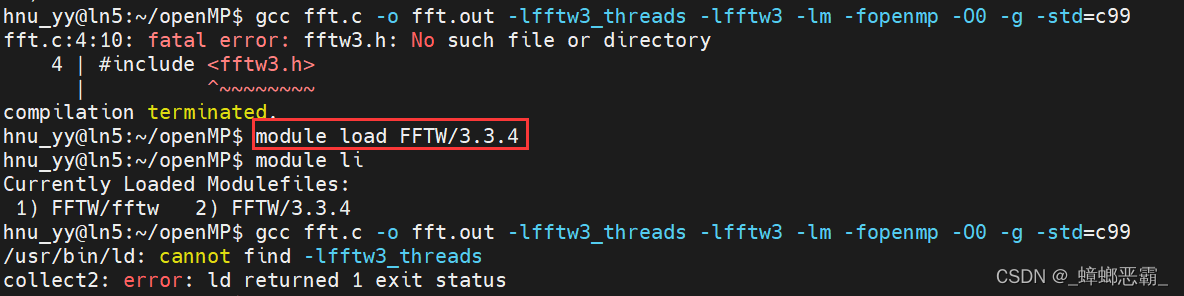
“知识库”中给的编译命令
gcc fft.c -o fft.out -lfftw3_threads -lfftw3 -lm -fopenmp -O0 -g -std=c99,但用这个会报错:

-
试错:把FFTW/3.3.4 load之后,上面错误消失,出现了新的错误;
-
【失败的尝试】:Linux下编译程序/usr/bin/ld: cannot find -l*错误的解决方法
- 创建符号链接的权限不够;
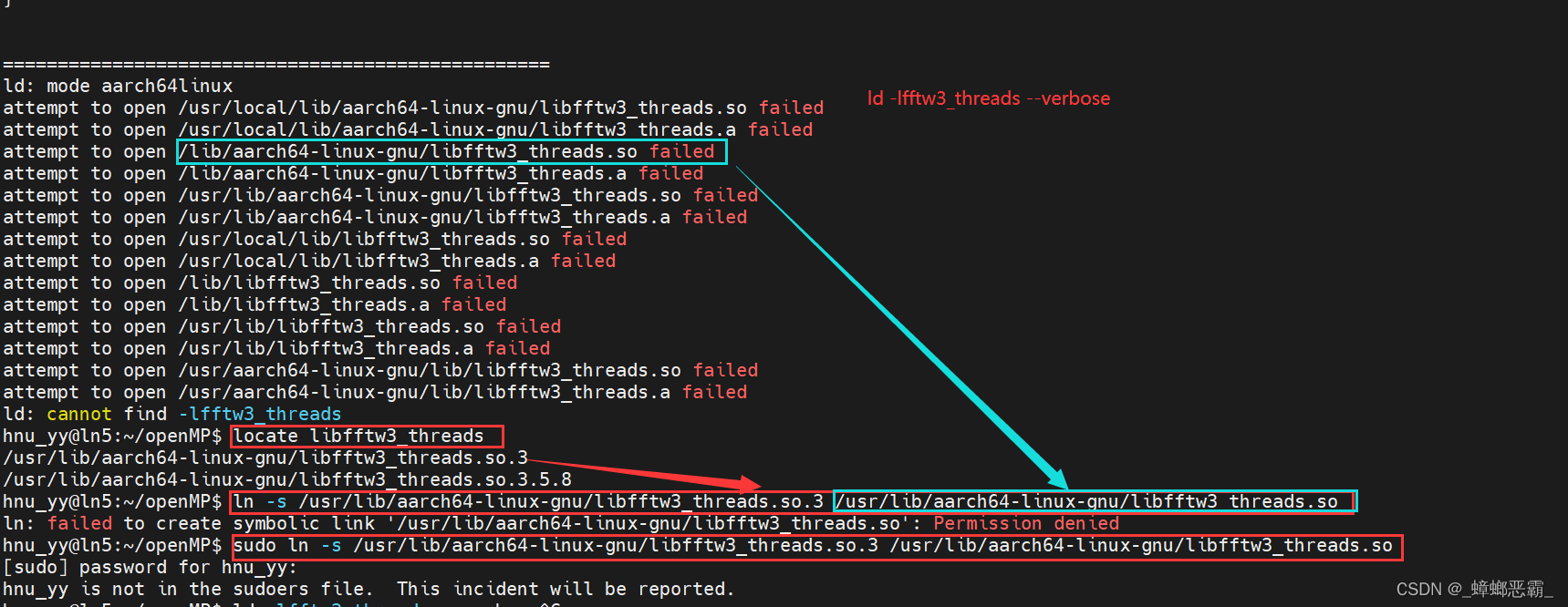
- 创建符号链接的权限不够;
-
- 解决:助教说:“第四次实验里有一部分需要安装fftw库,这个题目不用做”
- 编译运行

















 1807
1807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









