






图解:
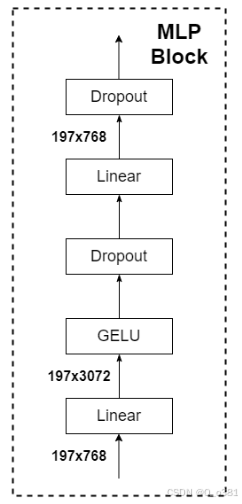
代码:
class Mlp(nn.Module):
"""
MLP as used in Vision Transformer, MLP-Mixer and related networks
"""
def __init__(self,
in_features, #输入特征的维度
hidden_features=None, #隐藏层特征的维度,默认为none
out_features=None, #输出特征的维度,默认为none
act_layer=nn.GELU, #激活函数层,默认使用nn.GELU
drop=0.): #丢弃率,默认值为 0,表示不进行丢弃操作
super().__init__()
out_features = out_features or in_features
#如果输出特征的维度没有指定则默认与输入特征维度相同。
hidden_features = hidden_features or in_features
#如果隐藏层特征的维度没有指定则默认与输入特征维度相同。
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
#默认使用nn.GELU
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
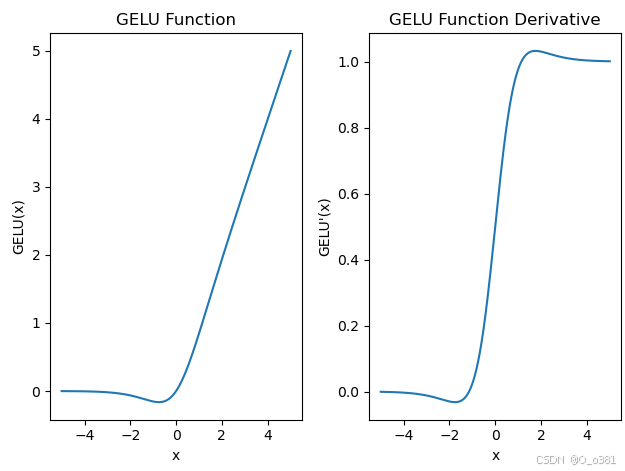
return xGELU函数的优点:
- 平滑性:提供平滑的激活曲线(处处可导且导数平滑),有助于梯度流动,减少梯度消失问题。
- 自适应门控:基于输入自动调整激活量,增强模型对特征的自适应能力。
- 非饱和性:避免梯度消失,保持网络深层的激活和梯度。
- 非单调性:能够捕获更复杂的数据模式,提高模型的表达能力。
- 性能提升:在多种深度学习模型中,GELU已被证明能提升性能和泛化能力。
GELU函数:
公式:
图像:

















 1828
1828

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









