






U-net
图1
首先U-net第一次为了解决医学影像问题提出的。
它的具体结构如下图:
他也是一个encoder-decoder结构,其中encoder是U形左边的部分,decoder是U形右边的部分。左边的叫做contracting path,右边的叫做expansive path。
在这个U形中,每一个长条的矩阵都是一个特征层,每一个箭头都代表一种操作。
最初的U-net操作,它在进行卷积操作时,它的卷积核是3x3的,并且它没有进行padding操作。(因为当时BN操作并没有火起来,所以最初的论文也就没有进行padding操作,所以越操作它的长和宽也就越小)
一开始我们输入572x572,通道数为1的图像,然后经过两次卷积操作,他变成了568x568x64的特征向量。然后经过一个2x2的最差池化,他变成了284x284的特征向量,通道数为64,然后在经过两次卷积变成280x280,通道数为128的输出,在经过最大池化变成140x140x128的向量再经过两次卷积编程136x136x256的结果。再经过最大池化编程68x68x256的输入再经过两次卷积变成了64x64x512的输出结果,最后再去最大池化变成了32x32x512,再经过两次卷积变成28x28x512的编码结果。
解码过程就是28x28x1024的输出结果经过上采样得到转秩卷积,得到56x56x512的输出结果,然后把这个输出结果与它对应的编码结果去进行一个拼接(编码结果是64x64x512的,需要进行一个中拼裁剪转化为56x56x512)两个结果拼接起来也就是我们这一步的输入,我们把输入结果经过两次卷积变成52x52x512,再把这个结果,去进行上采样变成104x104x512,然后再把这个输出结果和它对应的卷积结果拼接起来作为一个输入。如此循环,知道得到最后的结果。
最后我们得到的结果是338x338x2的输出结果。(2是因为我们这个是实验是二分类)
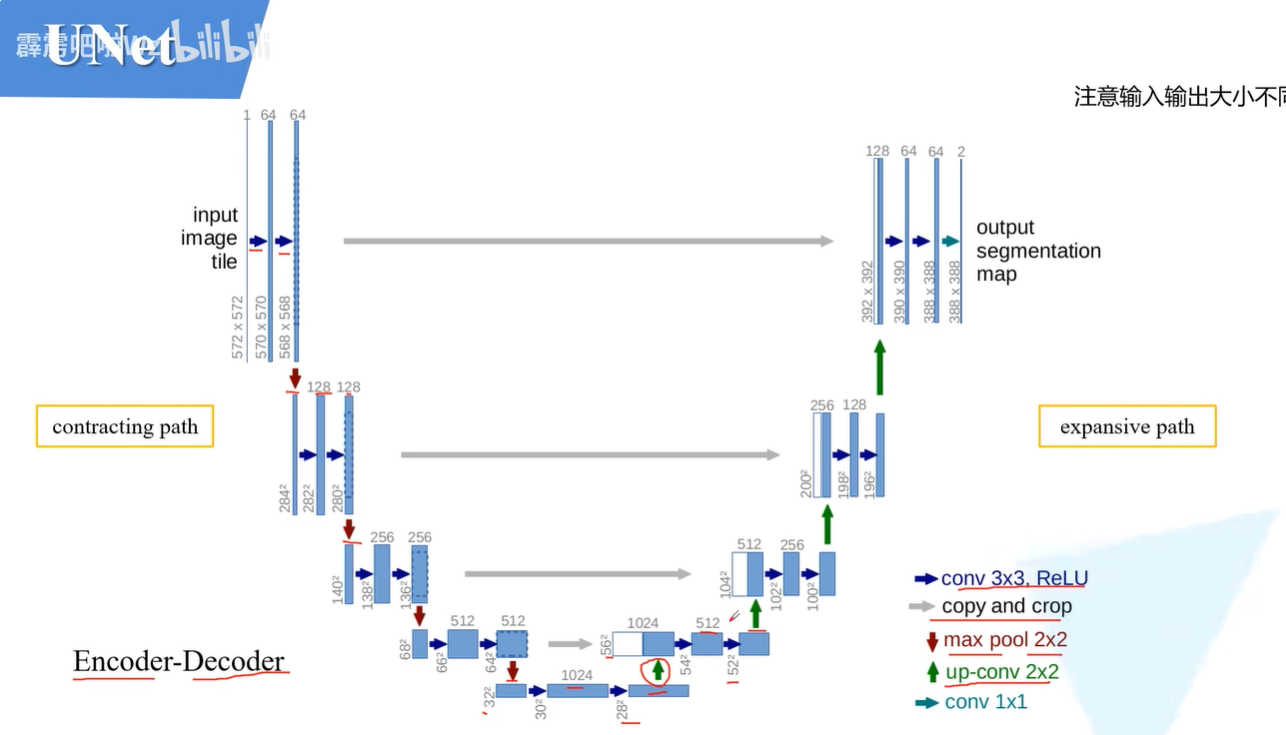
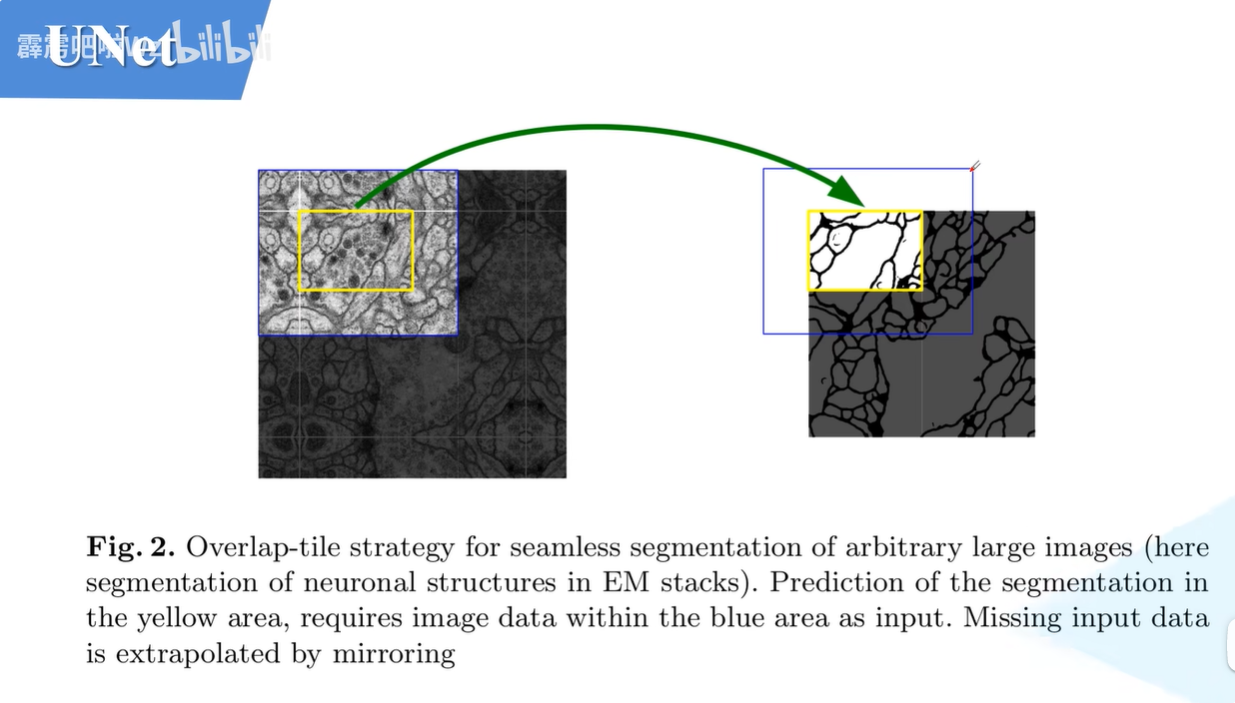
图2
论文中又给了一个图2,论文的意思是,我们要输入更大的信息之后才能能到更小位置的信息。我们输入的是蓝色大小的区域,我们得到的分割之后的区域只能为黄色大小的区域。
我们如果一次把整张图片输入进去,它的显存就会爆炸。为了解决这个问题,我们可以每次只分割一小块区域,然后再去取相邻的一块区域。(相邻的两块区域之间会有重叠的部分)这样做可以更好地分割边界区域的信息。
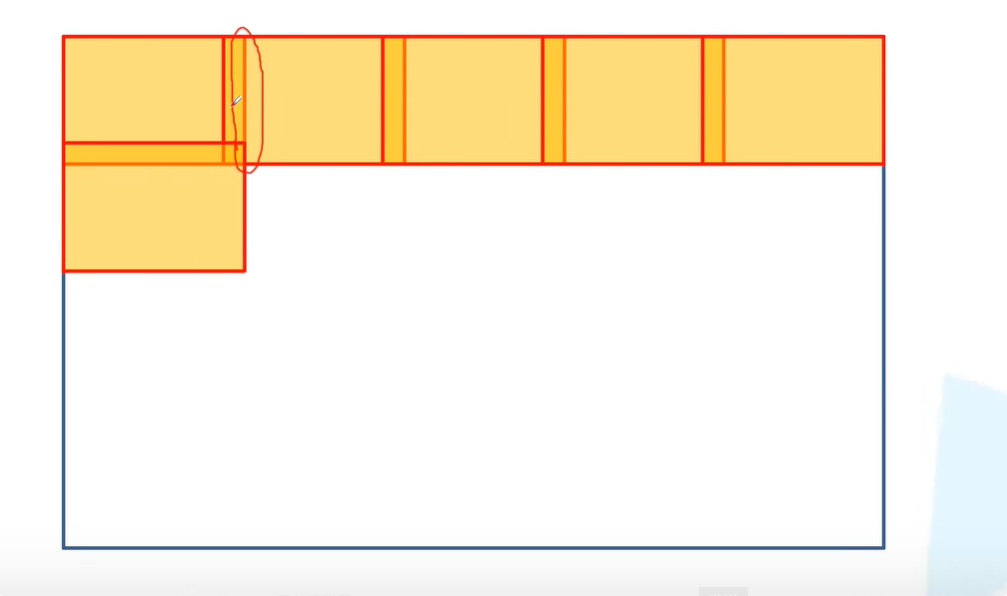
就是我们想要预测中间的图片内容时(黄色部分),我们可以考虑缺失图片的周围区域进行预测。但是对于那些边缘区域来说,边缘区域的周围区域比较少。作者使用的是一个镜像的策略。(这是因为作者没有使用padding填充,所以才导致的图像缺失,但是如果加上padding的话,他就不需要考虑怎么计算了)

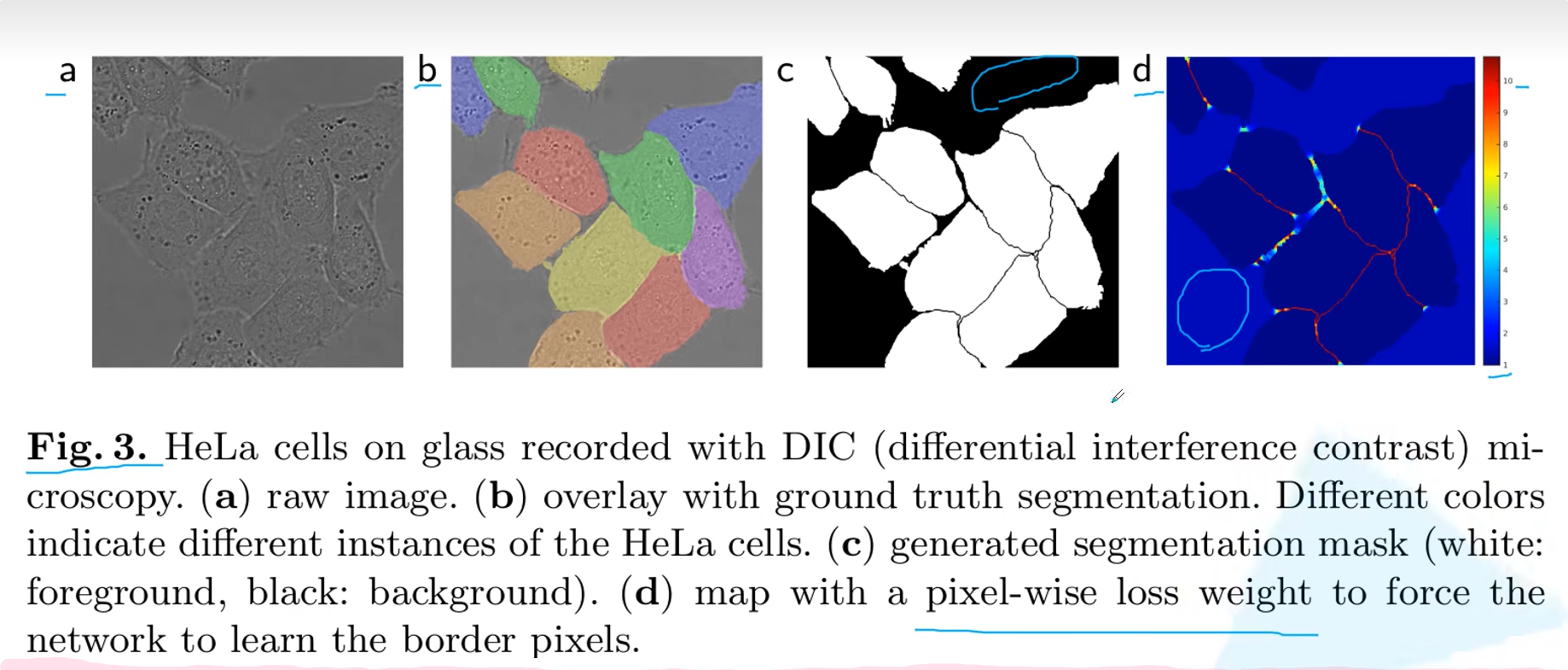
图3
首先图a是我们的具体细胞的图片,图b是我们经过人工标注之后的图片(每一个细胞都用不同的颜色)图c是我们的语义分析,也就是图片有底层和表层,表层就是白色,也就是细胞区域。最后图d是因为我们的图c它细胞之间的距离具体很难去进行一个分割。图d就是在计算细胞之间的距离时,所以作者使用了pixel*wise loss weight权重。来进行计算。在面对那种大片的黑色区域时,得到的权重结果很大,在面对很小的黑色区域时,作者给出的结果很小。
U2-net
首先U2-net是针对SOD任务(salient object detection)提出的,它只有前景和背景两个类别。
第一列是输入的原图 第二列是人工标注的,第三列是U2-NET标准版对应的图片,第四列是轻量级的U2-net,第五列之后是当年比较主流的U2-net模型目标检测。最后发现当时的U2-net效果比较好。

SOD任务是什么?
SOD任务是把一张图片中最吸引人的区域去进行分割出来。它是一个二分类问题,把一张图片分为背景和前景。
类似下图:

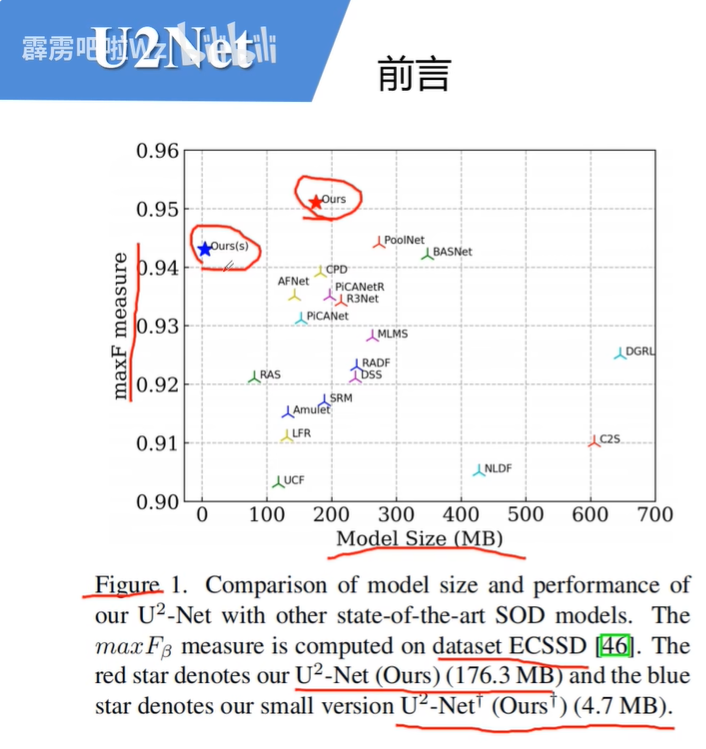
作者用U2-net与其他类型的网络结构去进行了对比,作者对比了模型的大小以及maxF measure对比结果。
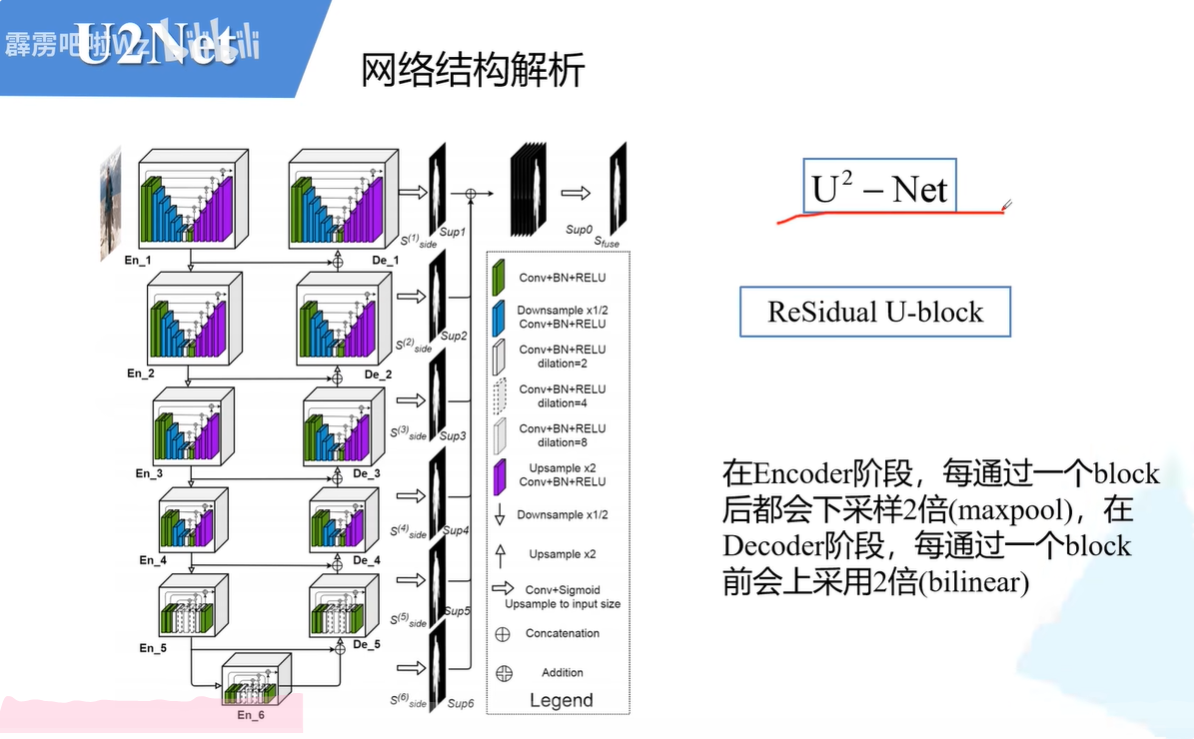
U2-net网络结构
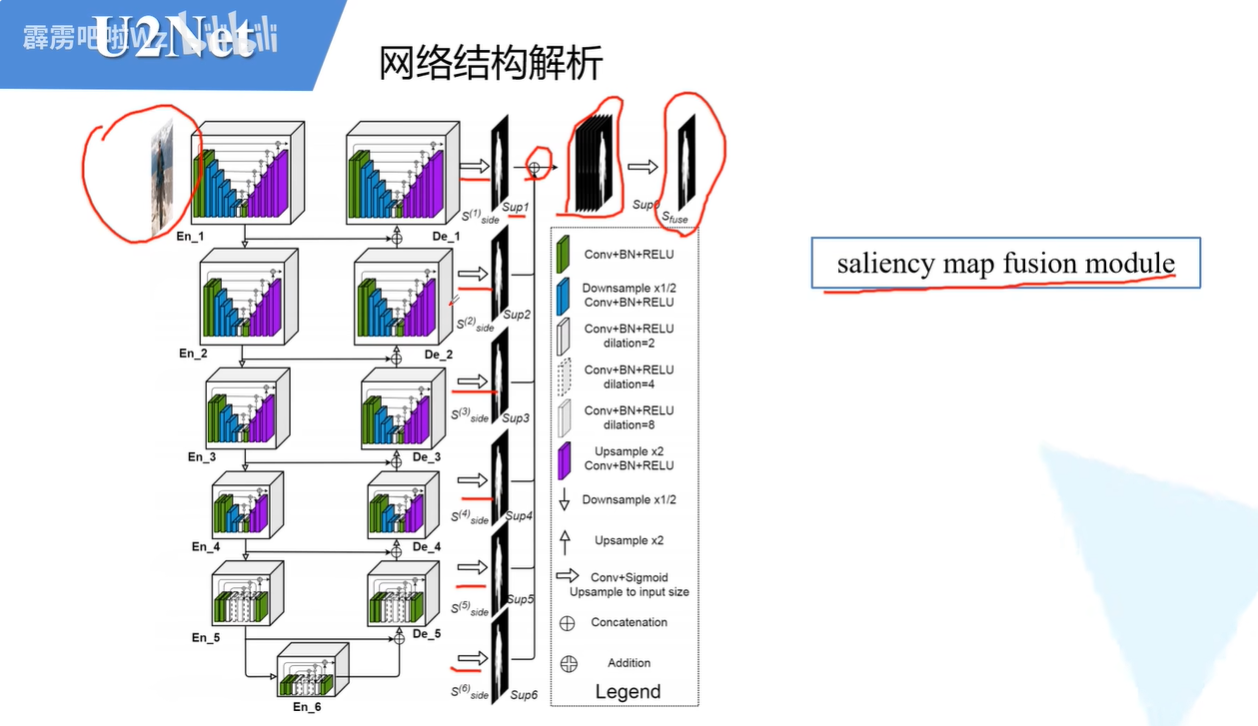
它就是在一个大的Unet结构中,每一个结构都换成了一个小的ReSidual U-block模块,并且每一个小的模块里面都嵌套了一个小的Unet。
每一个解码器的block都会输出一个图片结果,而我们最后的输出结果他需要考虑到每一个Block的输出结果,并且把所有结果进行综合考虑之后再输出最终结果。
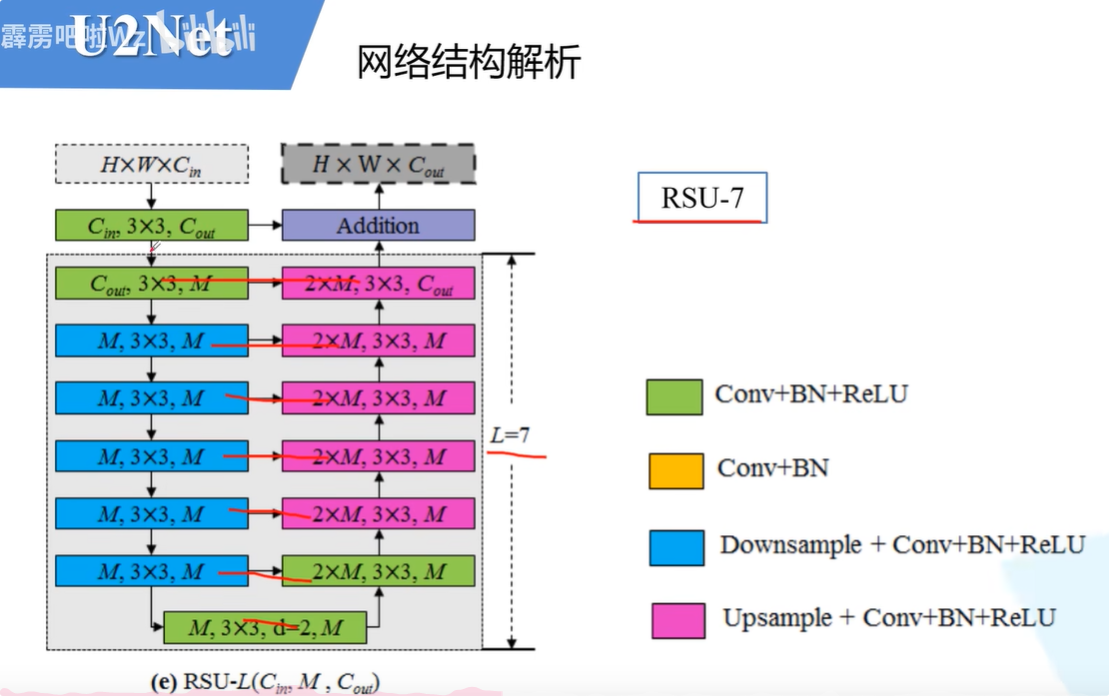
在原论文中,作者给出了一个这样的结构。一共有七层。
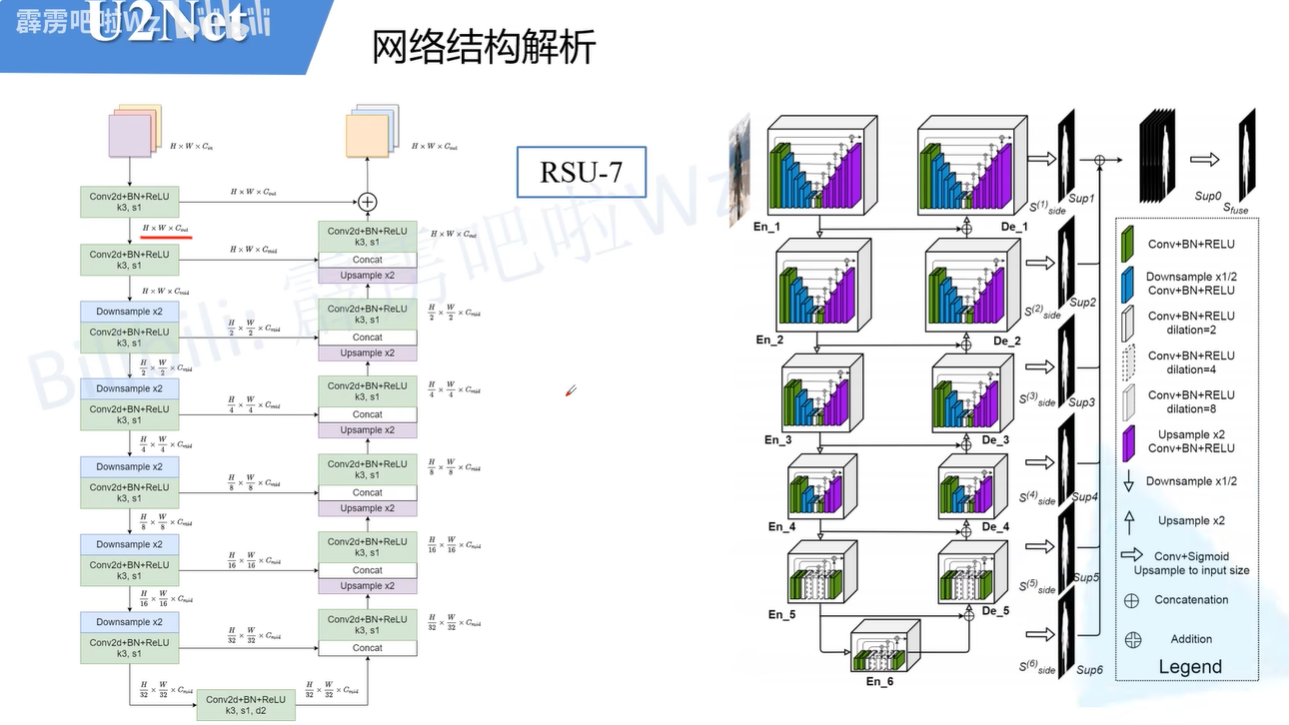
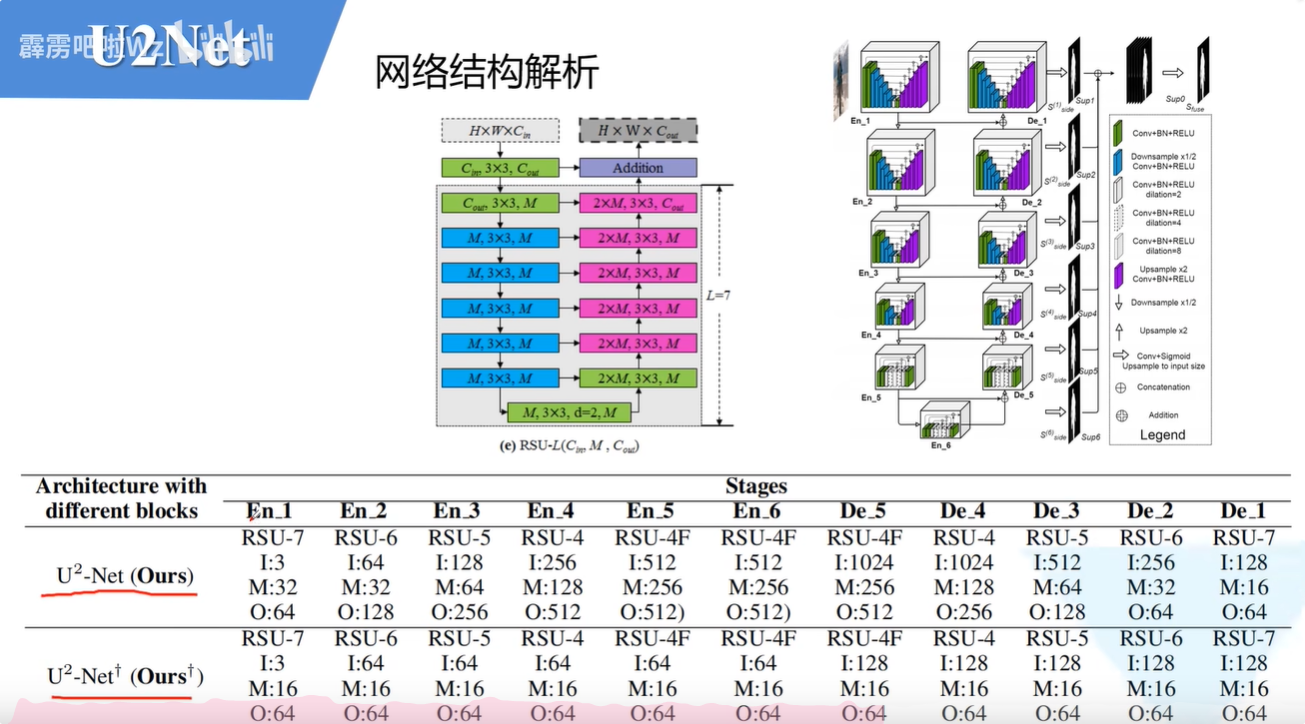
这是第七层的结构重新绘制的结果。这里的encoder-decoder-1使用的RSU-7的结构,encoder-decoder-2使用的RSU-6的结构,它和RSU-7相比少了一个下采样的操作。Encoder-decoder-3使用的是RSU-5操作,Encoder-decoder-4使用的是RSU-4操作。
然后是把每个阶段的特征图融合得到最终结果的方法:就是他们所有的层的输出结果,经过3x3x卷积(通道数为1)和sigmod结果,可以把所有的图像还原成输入图像的有一个尺寸。然后我们把所有的结果综合融合得到最后的输出结果。
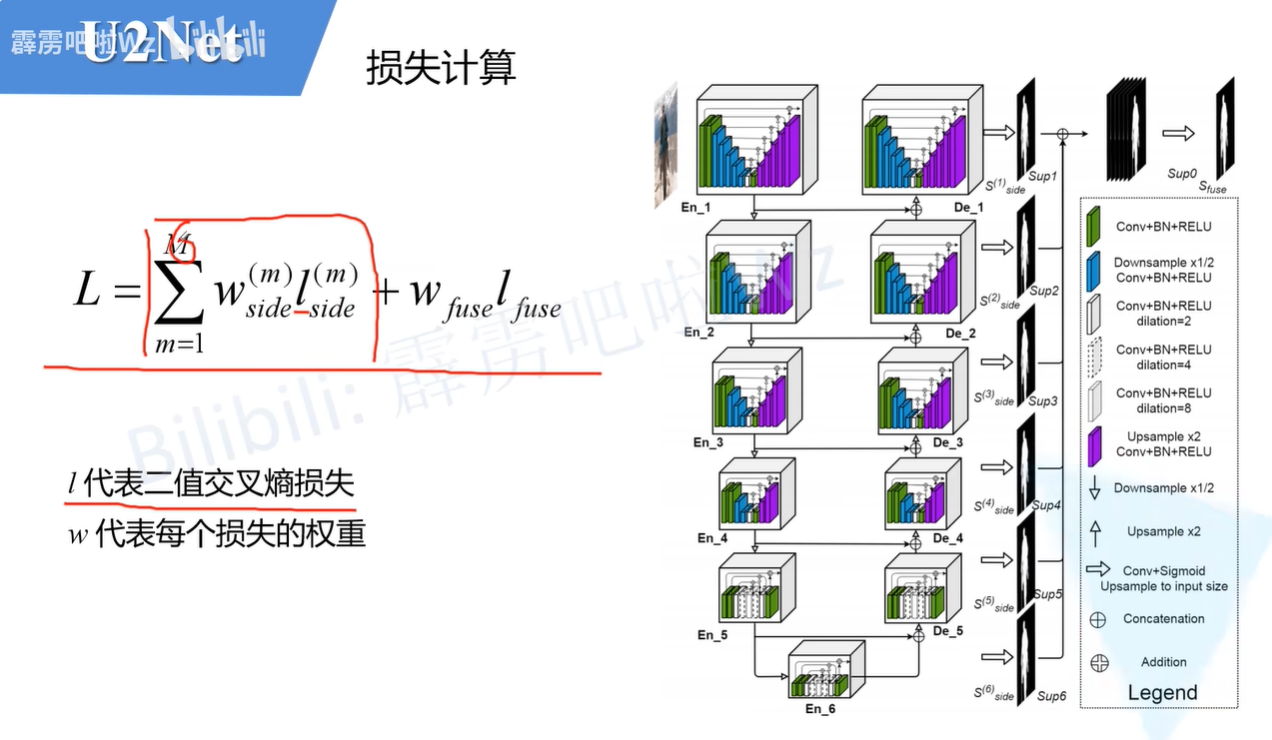
这个是它的损失计算函数。就是所有的权重和二值交叉熵损失的乘积再求和加上最后输出结果的权重和二值交叉熵损失。
它的评价指标如下:

最后是一个DUTS数据的介绍


















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









