







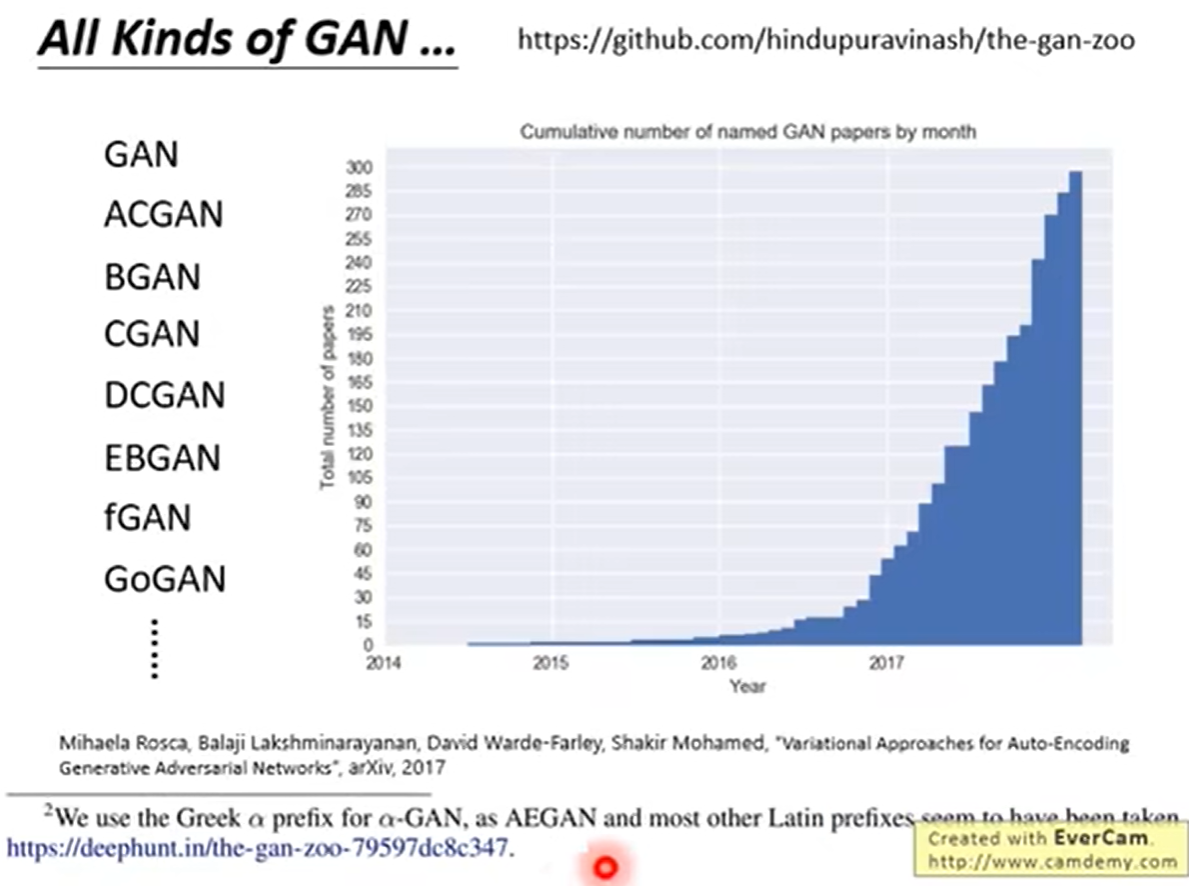
gan的种类有很多,到目前(2018年)已经有接近三百种GAN网络。
1. GAN网络的基础思想
1.1GAN网络基础架构
1.1.1 Genator生成器
在影像领域,我们使用GAN来产生图片,在语言领域,我们通过GAN来产生干扰句子。
在图像领域,我们传入不同的语句,把信息传入到生成器中(Generator)中,让GAN产生不同的图片/句子。
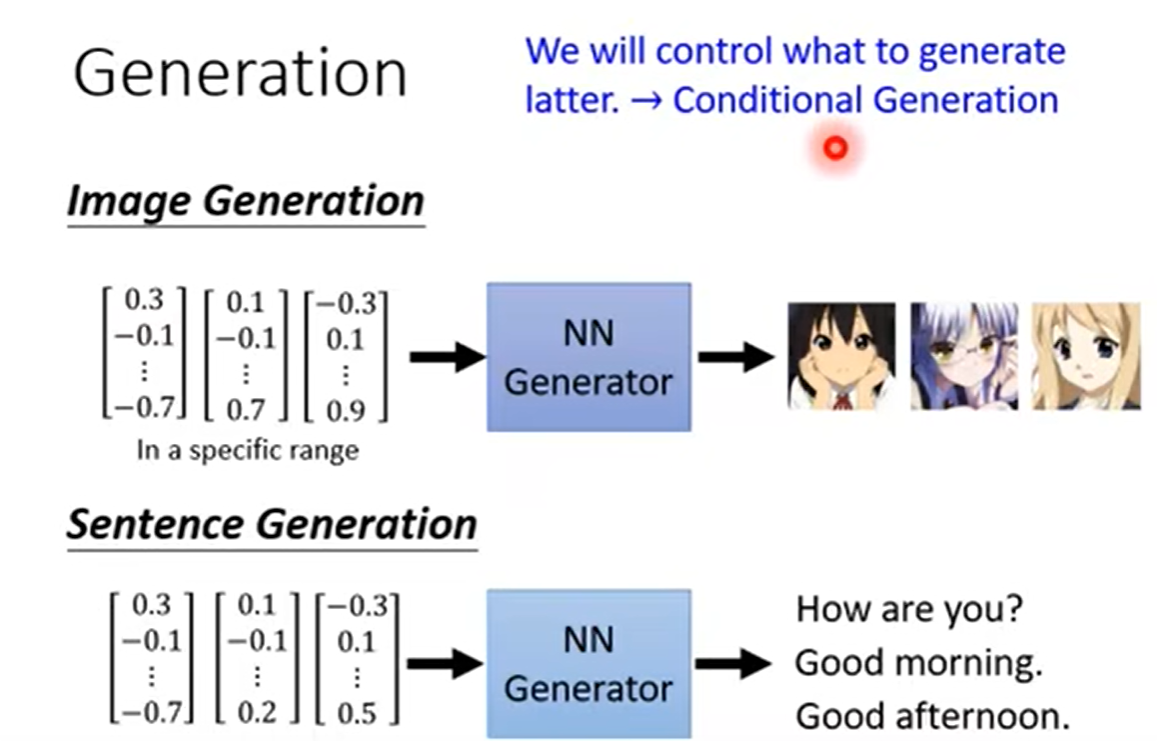
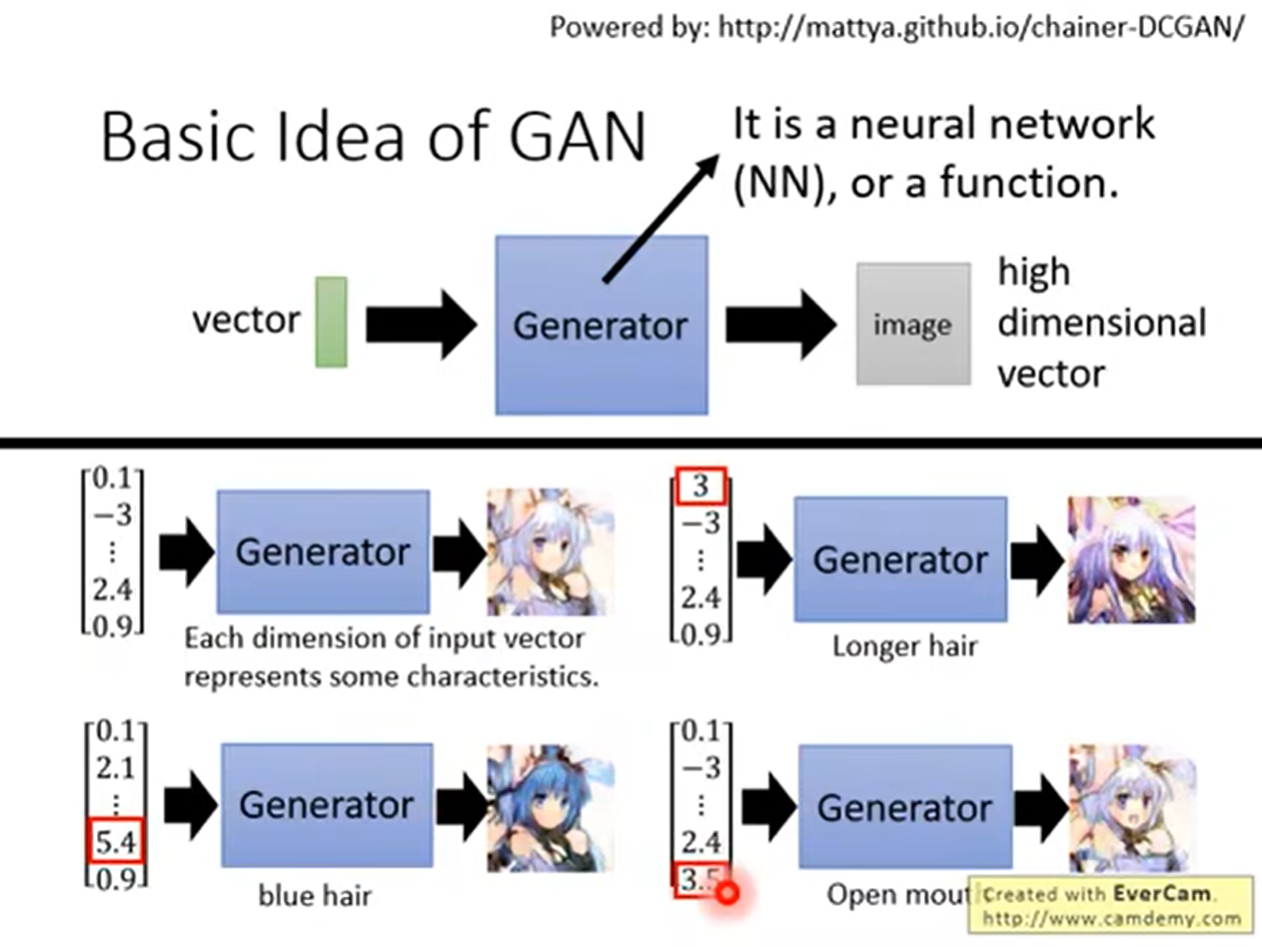
我们输入的是一个容器,里面包含向量,我们通过生成器输出的是一个高纬容器(也就是一张图片)。
我们向量中,每一个参数都代表着图片的一个属性,例如第一个代表头发长度,倒数第二个代表头发颜色,最后一个代表表情,我们可以根据对应参数的大小来修改生成图片的结果。
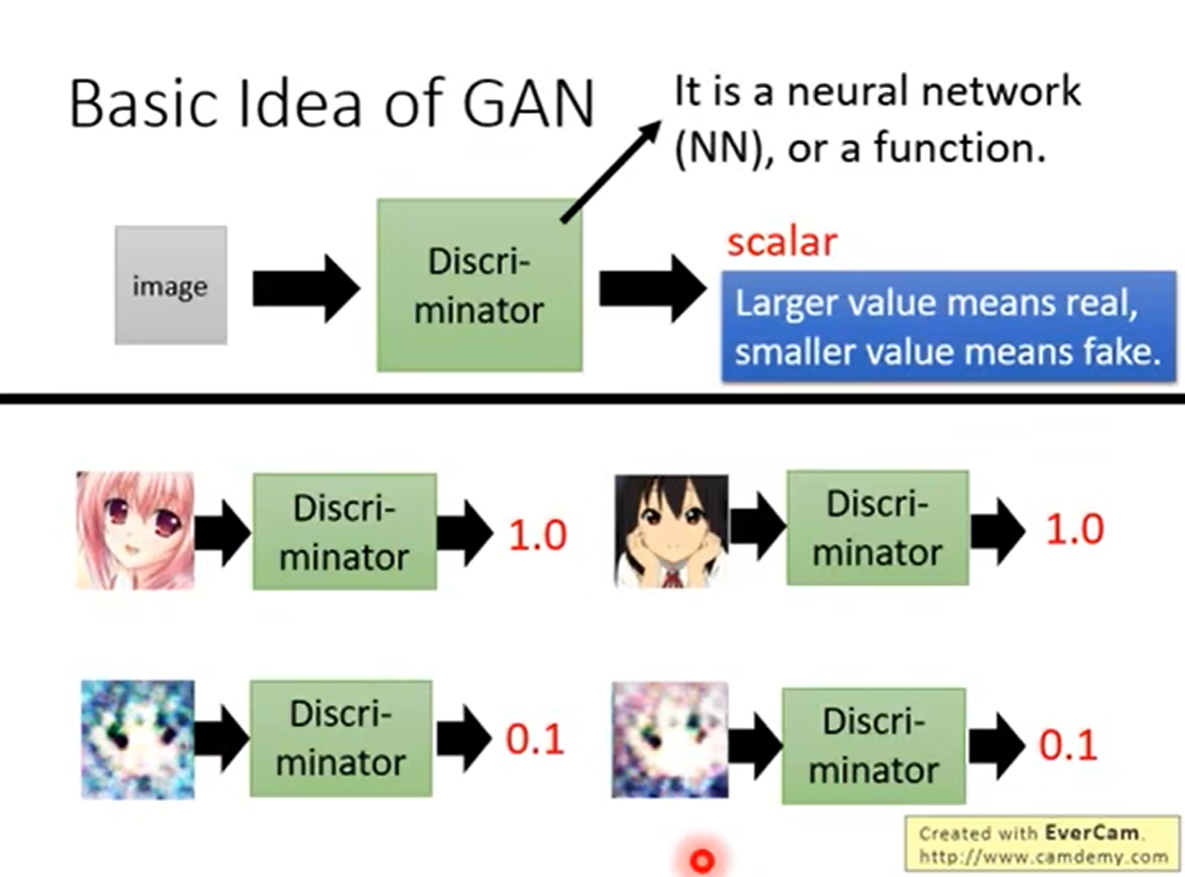
1.1.2 Discriminator辨别器
他是一个功能/神经网络,他通过吃掉一张图片/句子,来产生一个参数。(下图根据图片的美观程度生成得分)
1.1.3生成器与辨别器关系
就是生成器与辨别器就是类似捕食者与猎物之间的关系,一开始生成器生成图片,然后辨别器通过辨别来让自己的性能提升,而生成器在被辨别器识别之后,他自己也会不断更新,两者相互竞争,不断提高自己的性能。
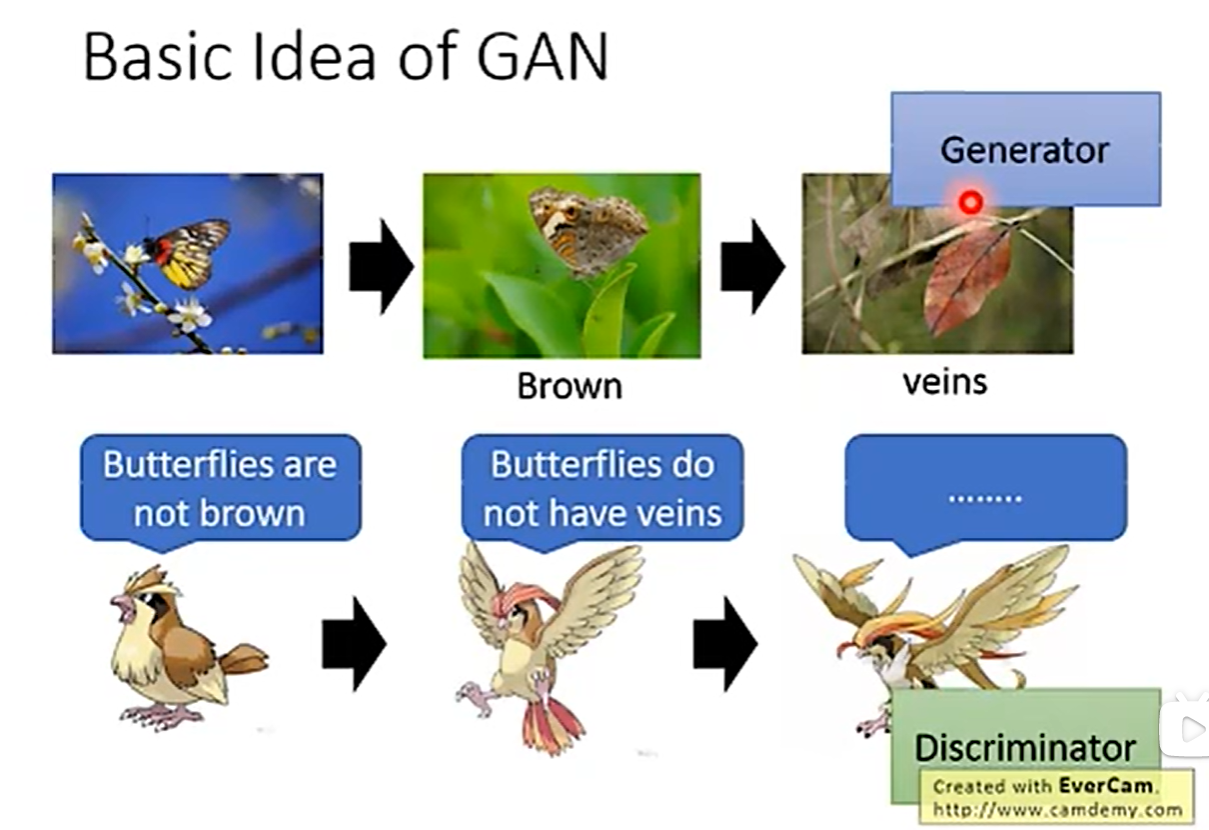
就是一开始generator生成图片,然后discriminator去判断,把错误打回去,然后generator再去修改自己的策略,不断往复,循环不止。
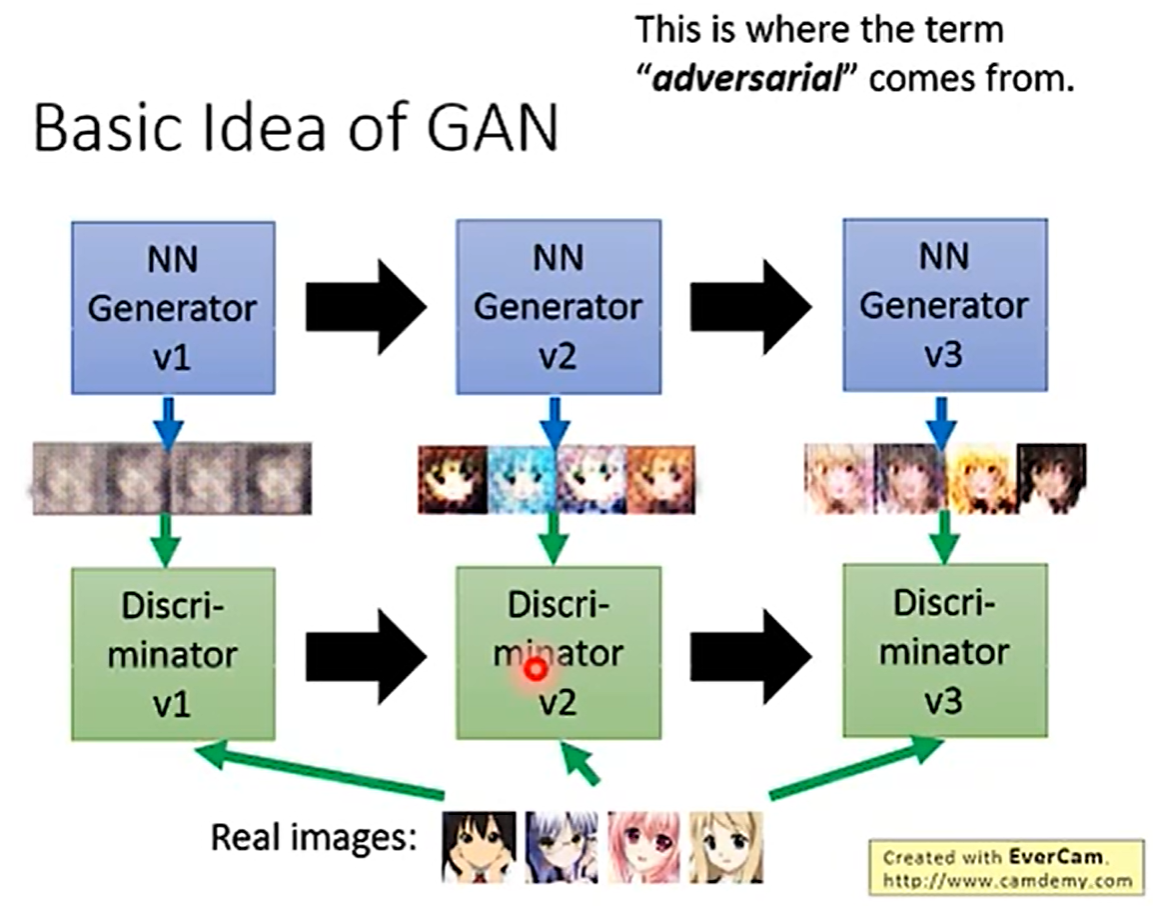
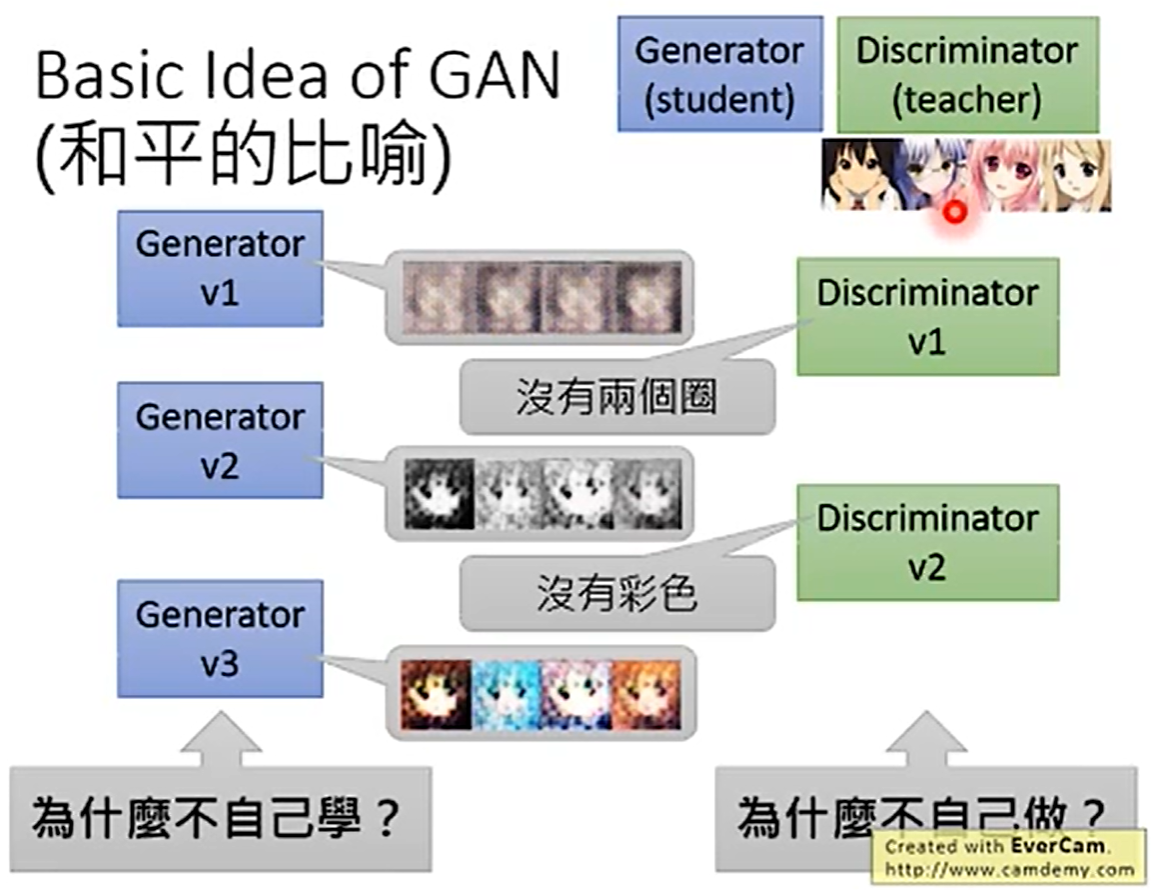
具体运行步骤、
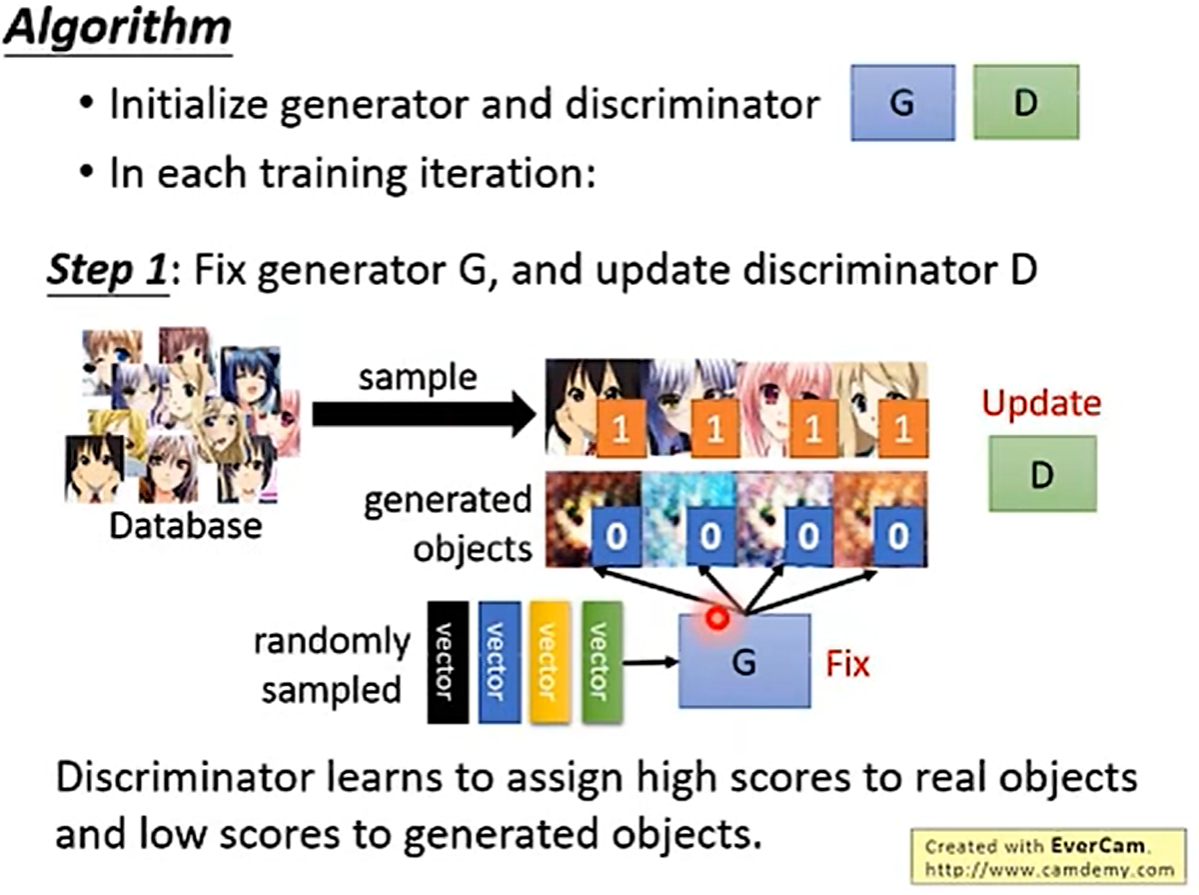
第一步:(固定生成器,更新辨别器)把生成器固定住,让后吧一大堆真实图片丢到生成器中,然后生成器就会产生一大堆图片。然后我们需要使用辨别器训练和挑选生成器生成的图片与真实图片,并给虚假的图片进行打分,并调整辨别器。
第二步:(固定辨别器,更新生成器)我们把辨别器固定住,根据辨别器的得分,然后去调整生成器。最后通过梯度下降去更新生成器。(为什么需要固定辨别器,因为我们想让最后的得分越高越好,如果我们不固定最后几层,(举个不恰当的例子,我们直接最后一层得分加个0.几,那最后的输出得分肯定是爆炸的,也就不能达到我们想要的效果))
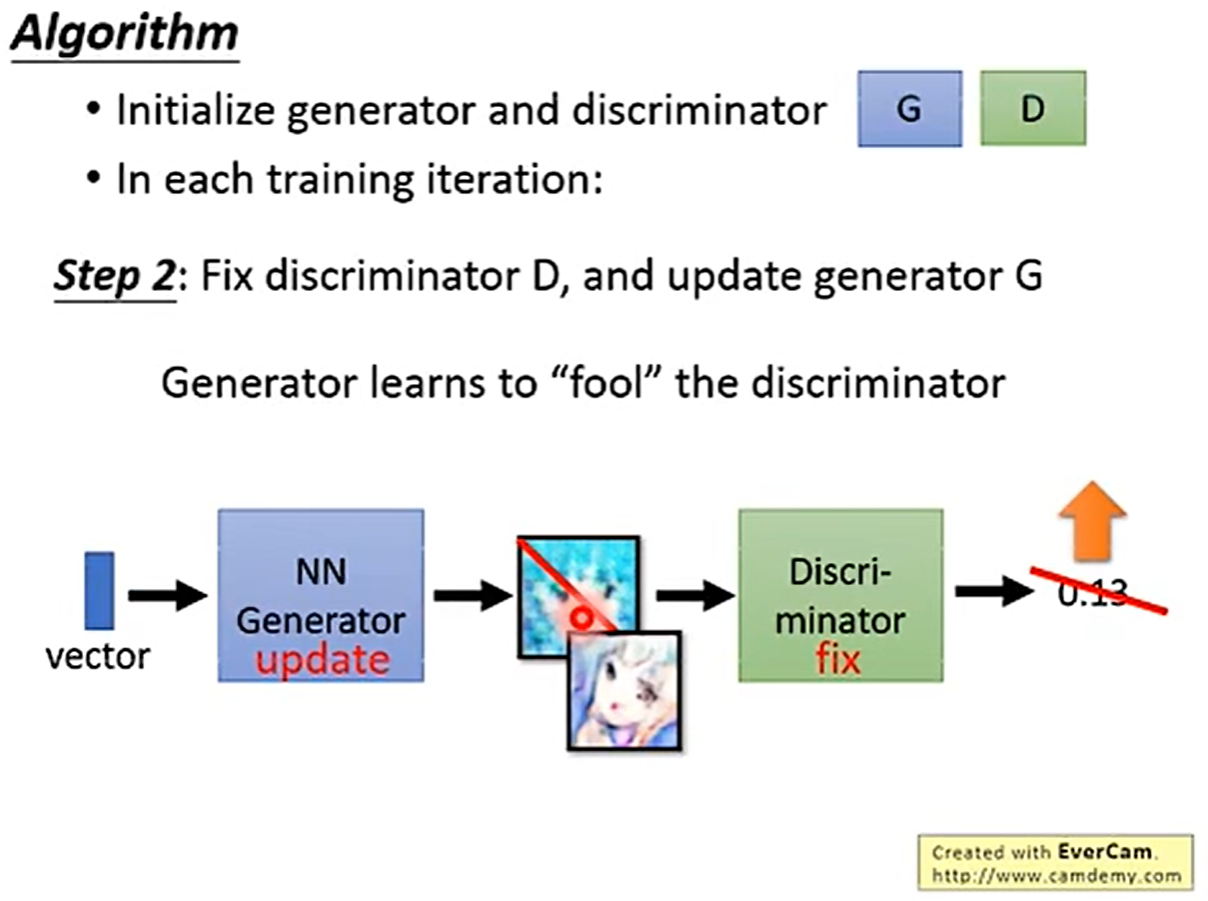
他们的具体计算与更新公式如下:

generation生成结果:
迭代一百次的结果:

迭代以前次的结果:

迭代五千次:

迭代一万次:

迭代五万次:

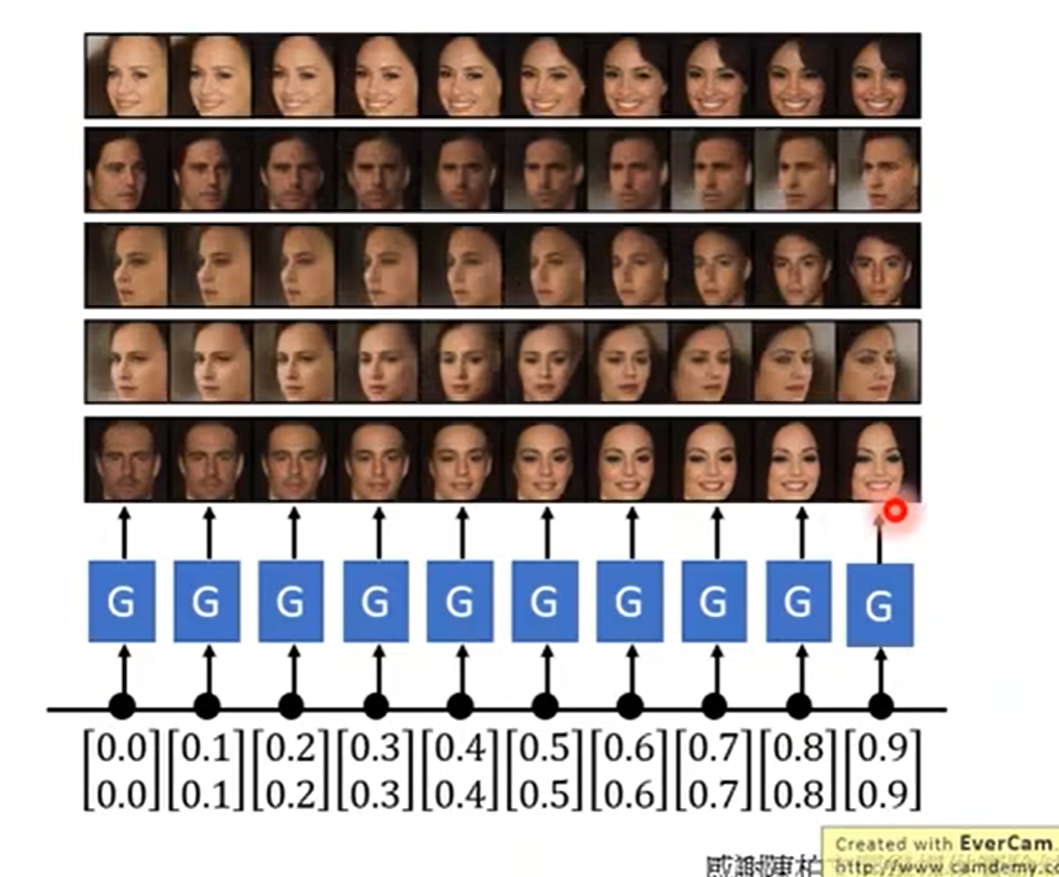
GAN网络也可以应用于三维头像生成,并且可以生成我们从来没有见过的结合。(比如 输入往左看的向量和往右看的向量,机器可以生成正脸照。)
1.2.GAN的原理
1.2.1Structured Learning(结构化学习)
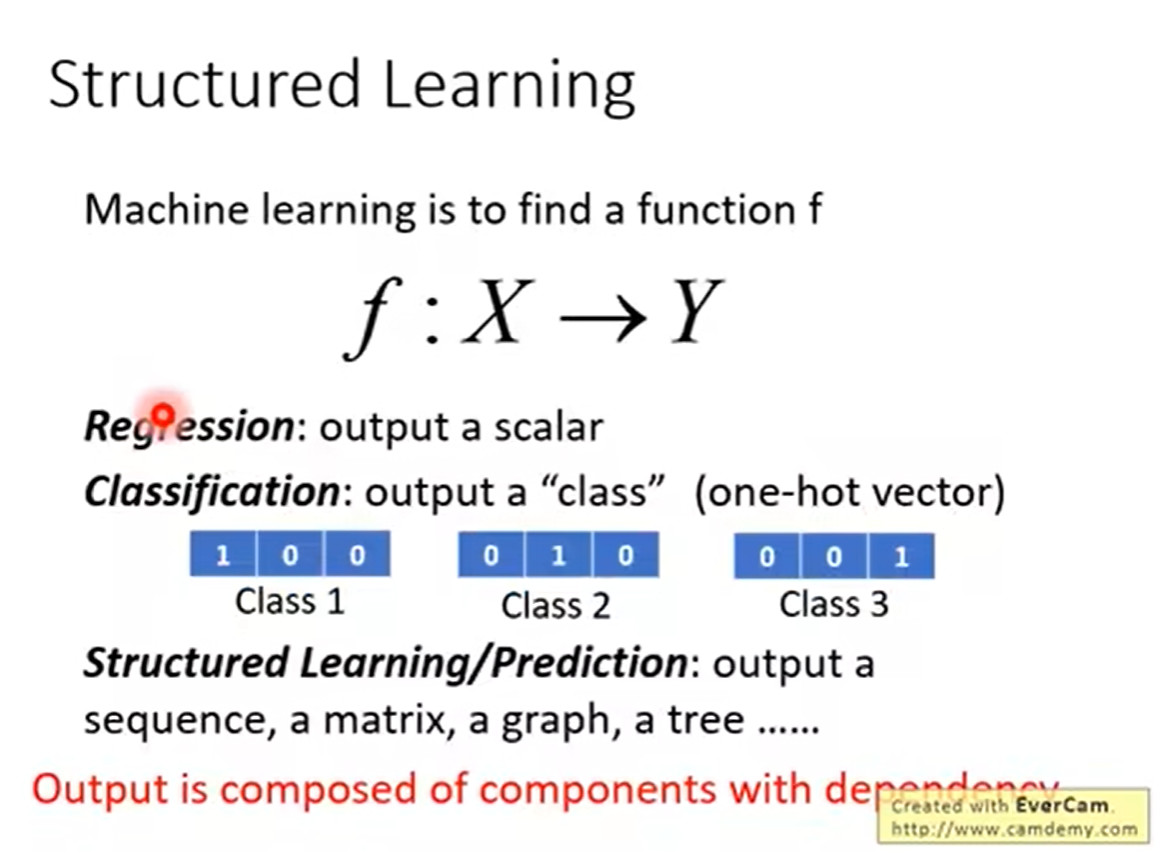
在机器学习中,我们找到一个函数F(x)=Y,我们需要解决的问题有:
回归问题:输出结果为一个数值,类似房价预测。
分类问题:输出结果为一个分类类别,输出是哪一类。
结构化预测问题:它的输出是一个非常复杂的输出,类似输出一个句子,输出一个图,一个矩阵,输出一个树等等。。。这些都叫做结构化预测。
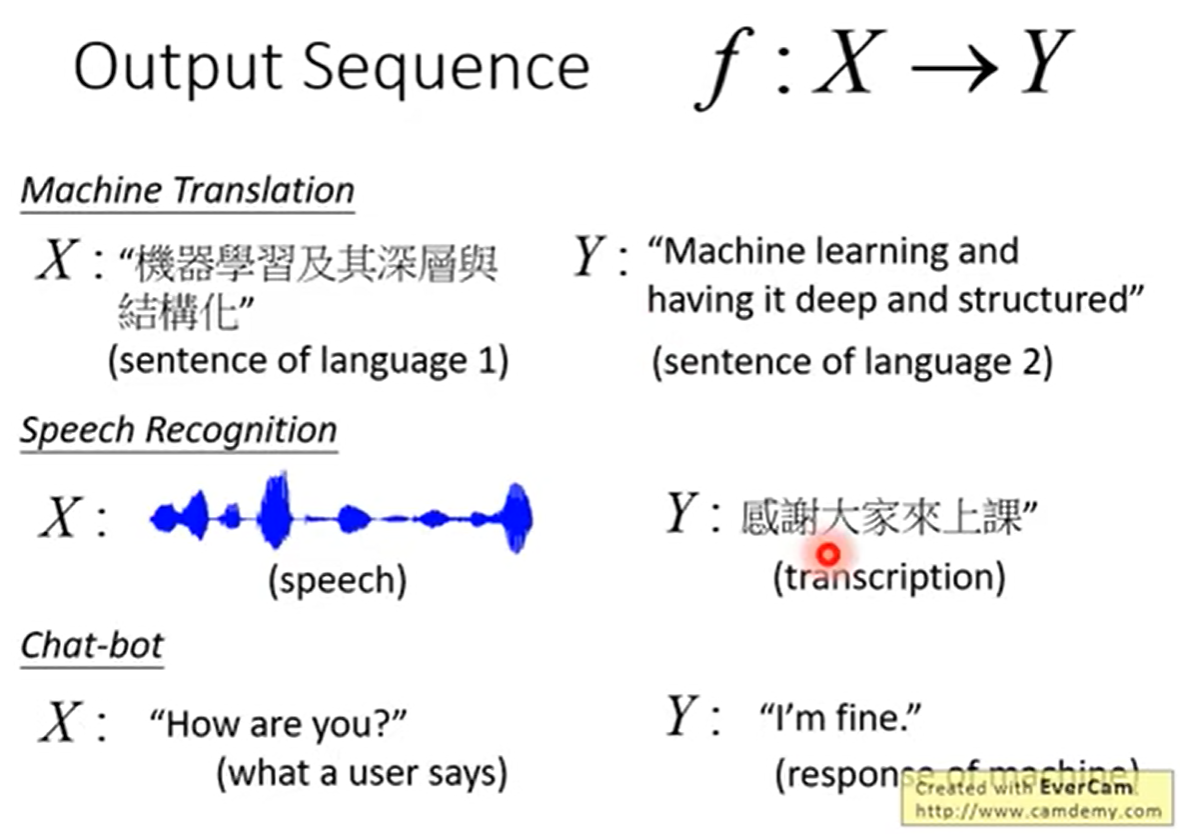
输出为句子:
输出为一个矩阵:(输出一张图)

为什么节后会学习有挑战性?
如果说有的类别只有很少的范例.我们可能做不起来,(举一个极端的例子,就是每个类只出现一次)。如何才能生成数据集中不存在的图片。机器需要更高的智商。

想要解决数据量少的问题。
机器必须要有归一化概念,要有大局观。他必须要考虑全局结果。
在衡量输出结果的优劣时,我们必须考虑全局变量。也就是我们输出一个点,我们必须考虑输出各个点之间的关系。而不是只考虑一个单个的点。
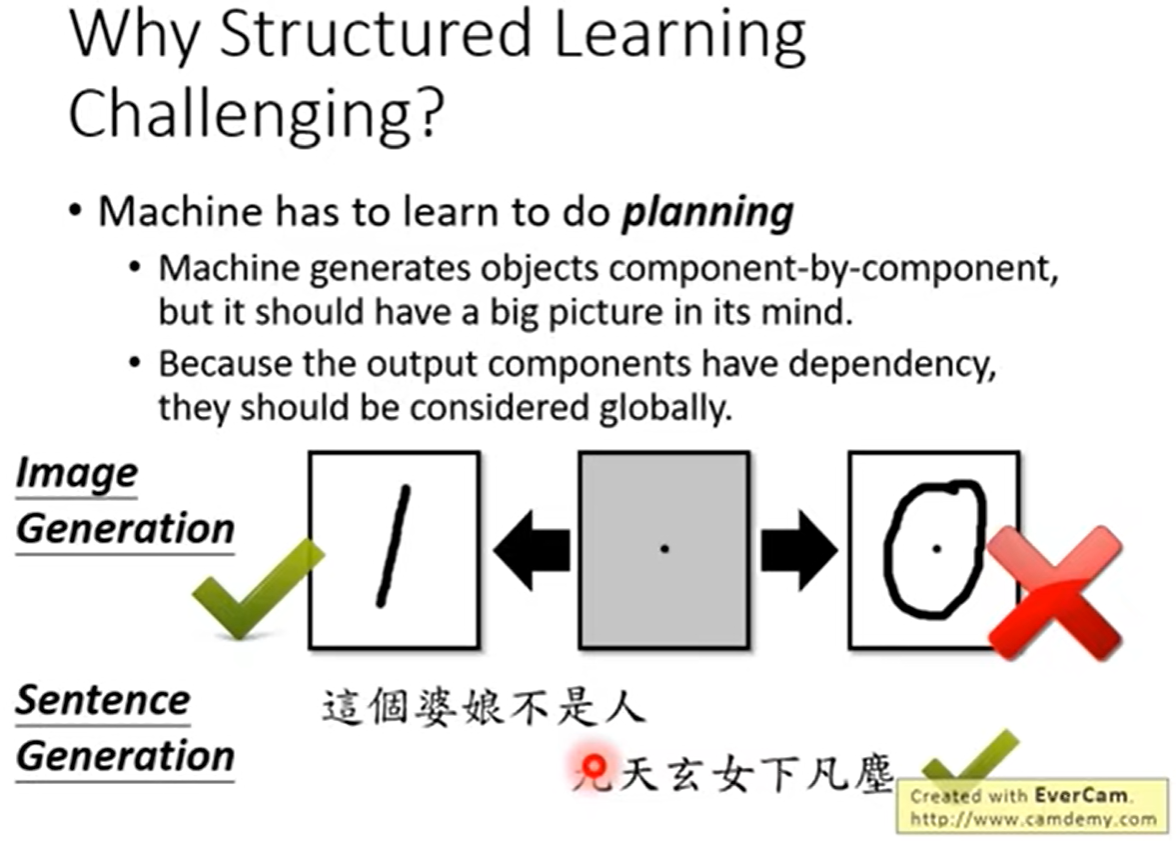
1.2.2传统的Structured Learning方法
传统structured learning包含两种方法,一种是bottom up 另一种是top down
bottom up,我们要产生一个完整的部件,bottom up是一个一个生成,最后的结果。但是这种情况很容易失去大局观。
top down是产生一个完整的部件之后,再来整体看这个全局是否合适。
第一个Bottom up就是Generator,第二个Top down就是Discriminator方法。两个组合起来就是我们所了解的GAN网络。
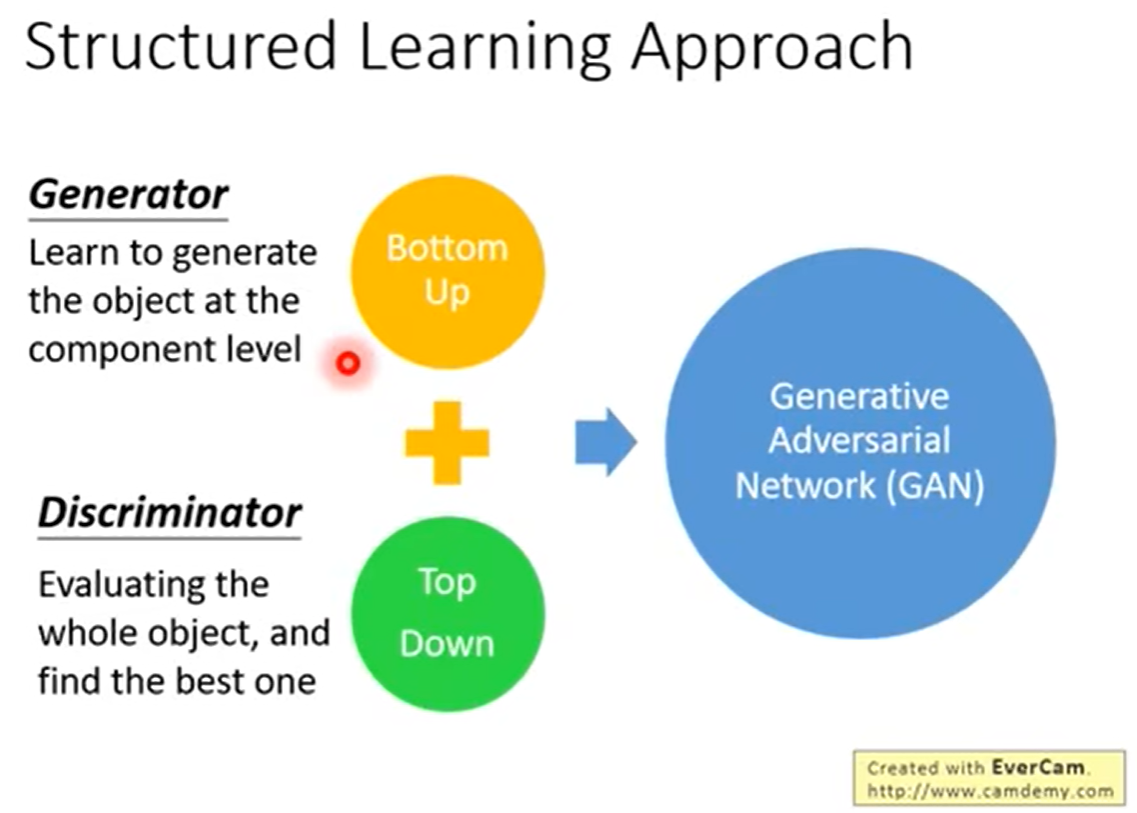
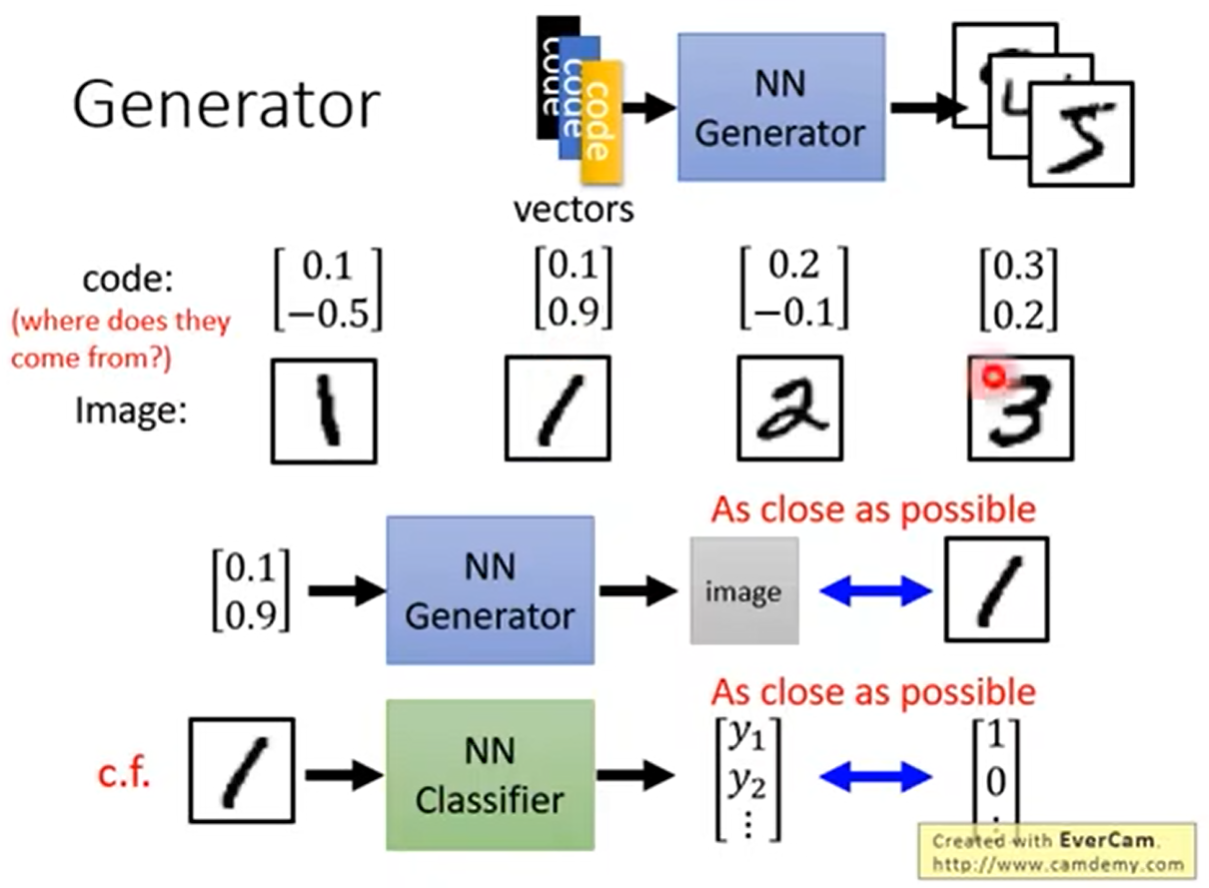
1.3 为什么Generator不能自己学习?
NNGenerator它的输出是一个图片,而标准NNC,它是输出一个向量。
auto-encoder 自动编码器
我们把图片使用auto-encoder编译成向量,然后再使用decoder去进行解码。
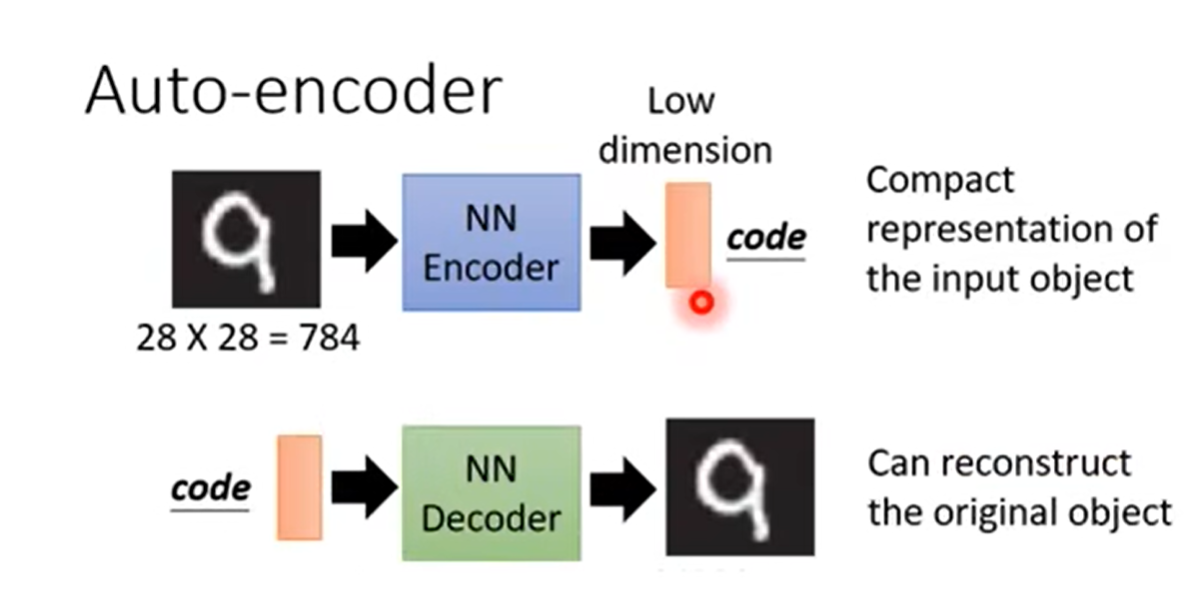
我们希望最后输出的图片与原图越相近越好。
我们在经过训练之后,我们可以输入向量,然后它输出图片。
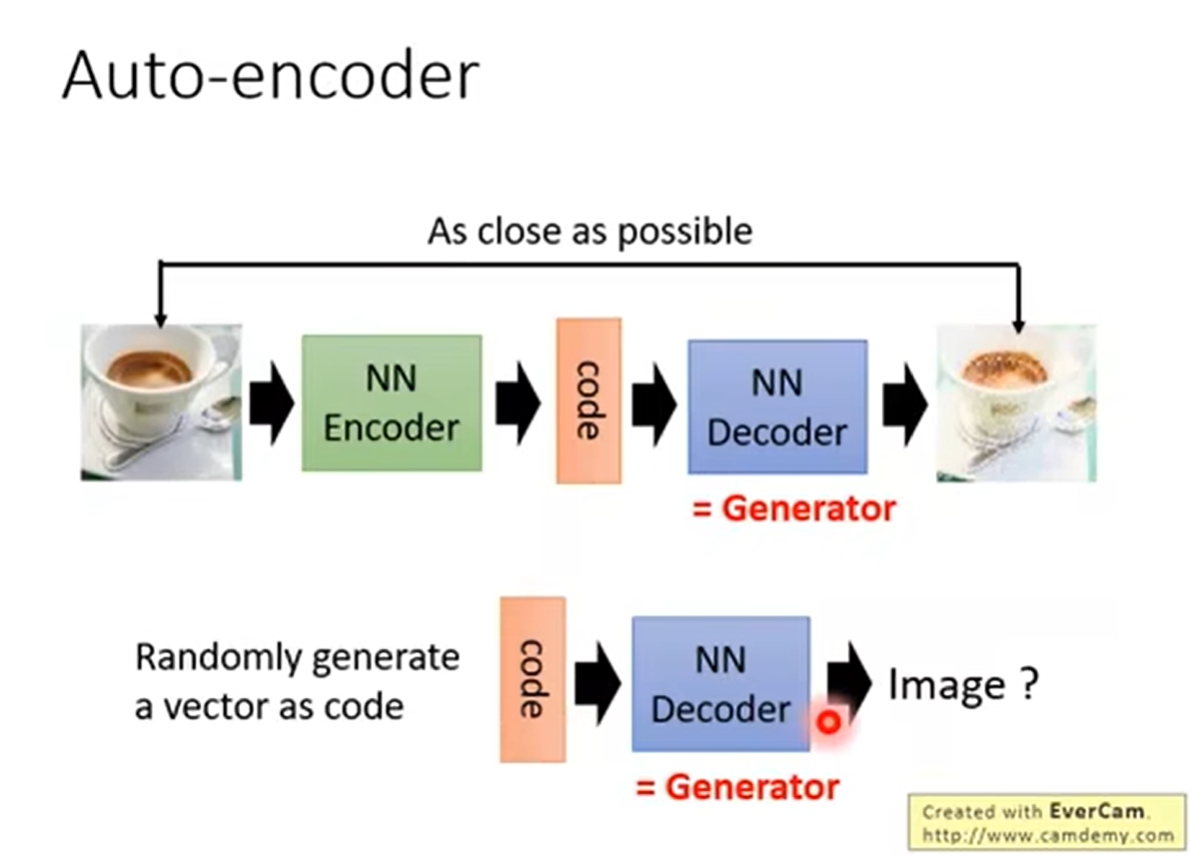
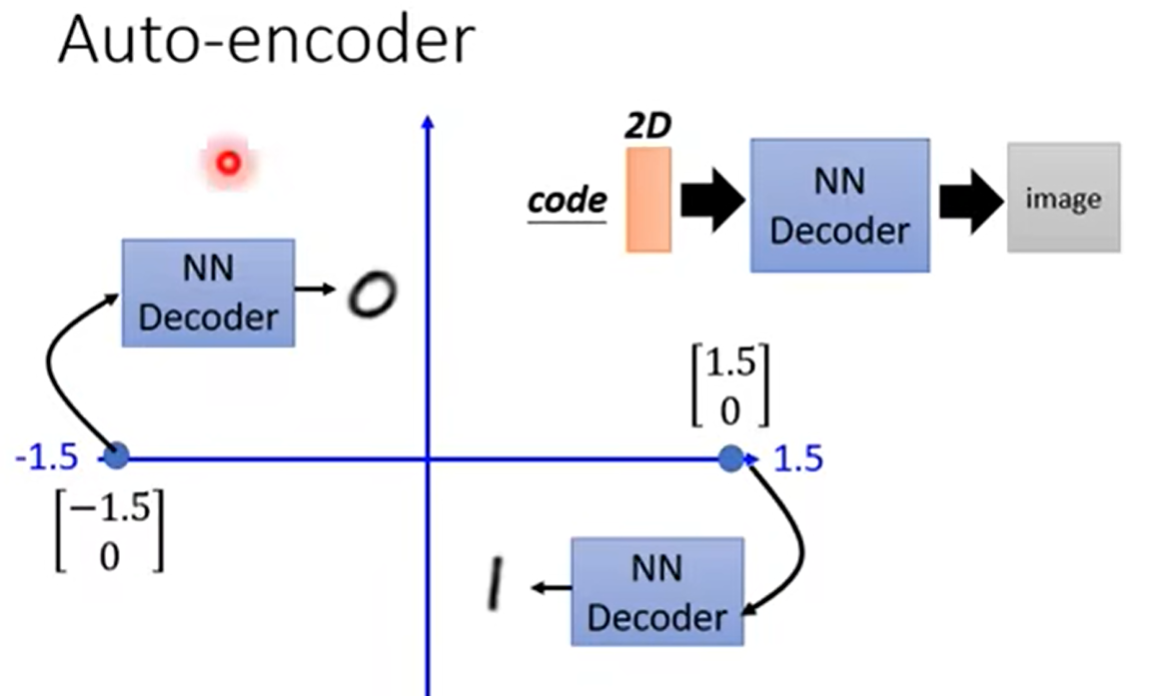
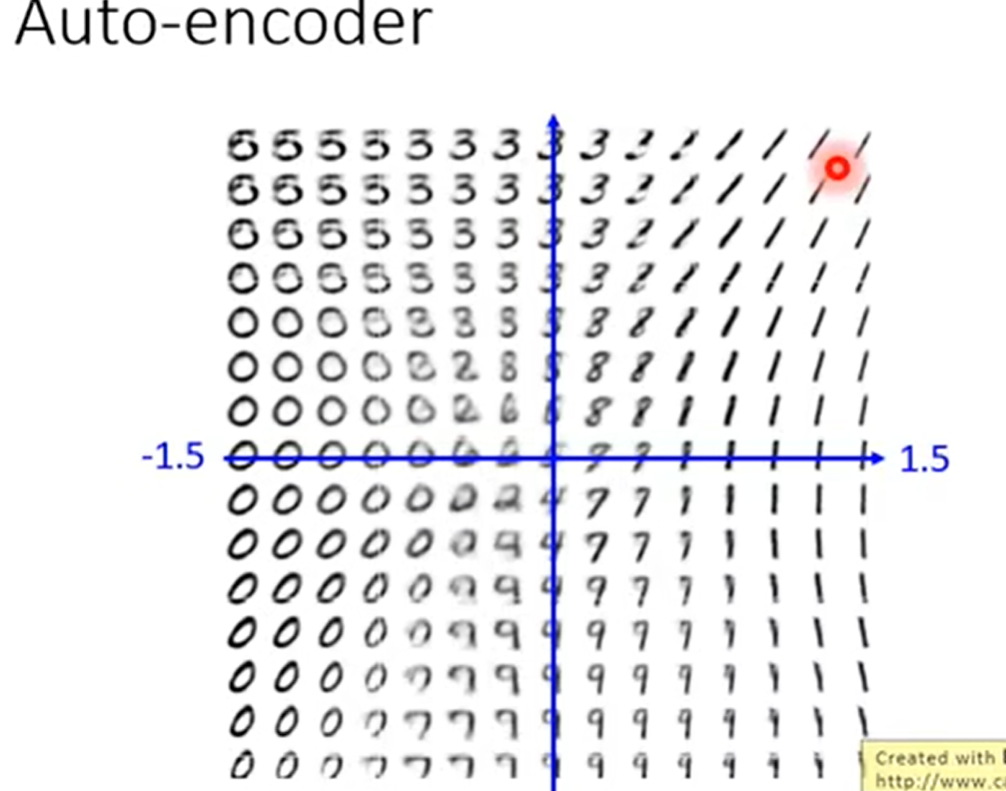
怎么判断图片生成的结果。 制作一个坐标轴,把原图的向量与生成的向量写入,并且计算距离。
但是这种仍然存在一些问题:
比如我们的a代表1向左的方向,b代表1向右的方向,但是我们的a和b各取0.5它的结果会是一个笔直的1么?答案是否定的,由于我们的NNGenerator它的函数是非线性的,所以输出结果并不一定是笔直的1。
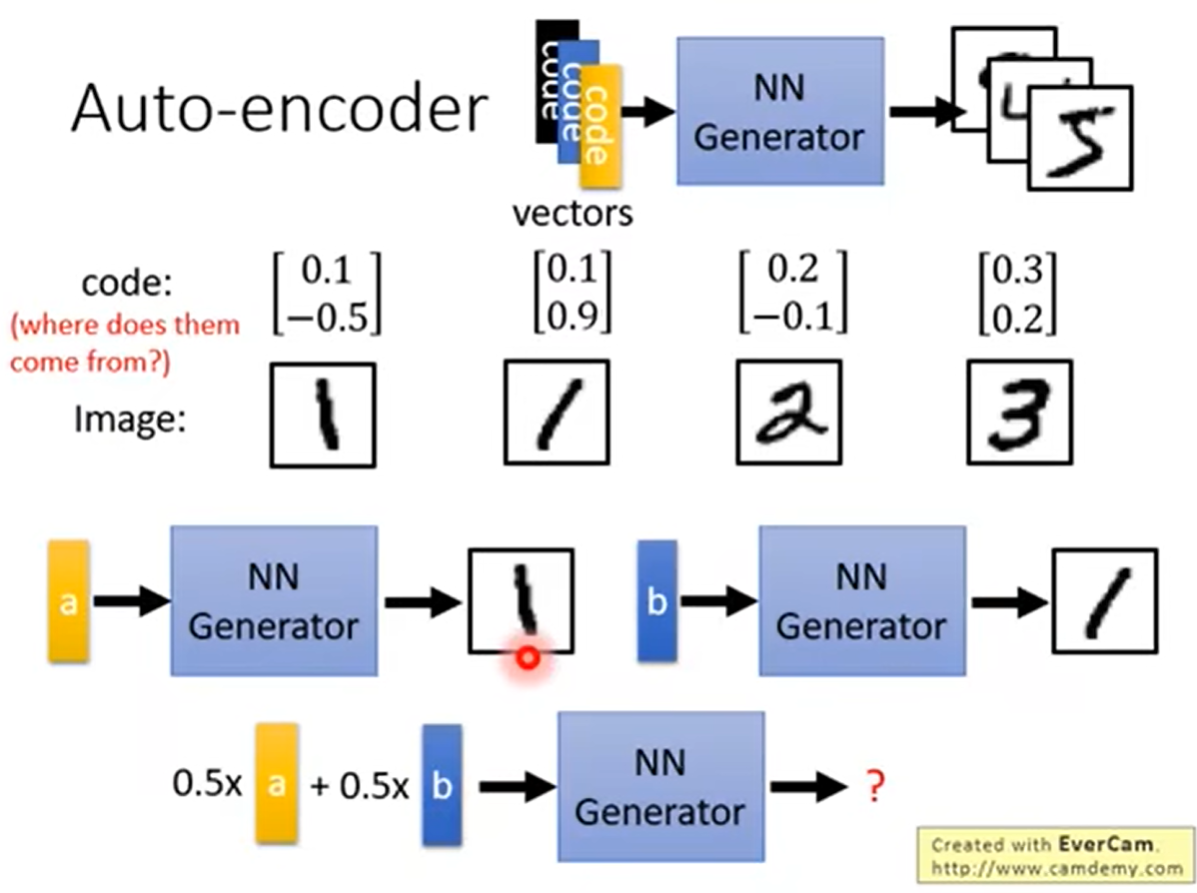
怎么解决这个问题?:使用VAE方法(Variational Auto-encoder(变分自编码器)&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6055
6055

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









