






Towards Robust Multimodal Sentiment Analysis with Incomplete Data![]() https://arxiv.org/pdf/2409.20012
https://arxiv.org/pdf/2409.20012
Abstract: 多模态情感分析(MSA)领域最近见证了一个新兴的方向,寻求解决数据不完整的问题。认识到语言模态通常包含密集的情感信息,我们将其视为主导模态,并提出了一种创新的语言主导抗噪声学习网络(LNLN)来实现鲁棒的MSA。所提出的LNLN具有主导模态校正(DMC)模块和基于主导模态的多模态学习(DMML)模块,通过保证主导模态表示的质量,增强了模型在各种噪声场景下的鲁棒性。
一、关键点
1.鲁棒的MSA
鲁棒的多模态情感分析(MSA)指的是在处理多种数据模态(如视频、音频和文本)时,能够有效应对数据不完整或噪声干扰的情感分析方法。鲁棒性在多模态情感分析中至关重要,因为实际应用中常常会遇到传感器故障、数据缺失或自动语音识别(ASR)问题,导致数据不一致。
2.主导抗噪声学习网络(LNLN)
主导抗噪声学习网络(Language-dominated Noise-resistant Learning Network, LNLN)是一种用于增强多模态情感分析(MSA)鲁棒性的模型。该网络的设计旨在处理数据不完整和噪声干扰的问题,特别是在多种模态(如文本、音频和视觉)中,语言模态被视为主导模态,因为它提供了更丰富的情感线索。
LNLN的关键组件包括:
-
主导模态校正(DMC)模块:该模块利用对抗学习和动态加权增强策略来提升主导模态(语言模态)的特征质量,从而减轻噪声的影响。
-
基于主导模态的多模态学习(DMML)模块:在该模块中,经过校正的主导模态特征与辅助模态(如视觉和音频)进行融合,以实现有效的多模态融合和分类。
-
重构器:用于重构缺失的数据,进一步增强系统的鲁棒性。
3.主导模态校正(DMC)
主导模态校正(Dominant Modality Correction, DMC)模块是多模态情感分析(MSA)中的一个关键组件,旨在增强主导模态(通常是语言模态)的特征质量,从而提高模型在面对数据缺失和噪声干扰时的鲁棒性。
DMC模块的主要功能和特点包括:
-
特征校正:DMC模块通过对主导模态的特征进行校正,确保即使在数据缺失的情况下,主导模态的特征仍然能够保持有效性和准确性。这是通过对抗学习和动态加权策略来实现的。
-
代理主导特征生成:DMC模块生成一个代理主导特征(Proxy Dominant Feature),该特征用于替代缺失或受损的主导模态特征。这使得模型能够在缺失数据的情况下仍然进行有效的学习和推理。
-
融合其他模态:在校正主导模态特征时,DMC模块还考虑了其他模态(如视觉和音频)的信息,以增强主导模态的表达能力。这种融合有助于模型在多模态环境中更好地理解和分析情感。
-
提高模型鲁棒性:通过确保主导模态特征的完整性和有效性,DMC模块显著提高了多模态情感分析模型在面对噪声和不完整数据时的鲁棒性。
4.对抗学习
对抗学习是一种训练方法,旨在通过引入对抗样本(即经过精心设计以误导模型的样本)来增强模型的学习能力。在DMC模块中,对抗学习的主要作用包括:
-
增强特征学习:通过对抗样本的引入,模型被迫学习更具鲁棒性的特征,从而能够更好地抵御噪声和数据缺失的影响。
-
提升模型的泛化能力:对抗学习促使模型在面对不同类型的输入时保持性能,增强了模型在真实世界应用中的适应性。
-
优化主导模态特征:在DMC模块中,对抗学习用于优化主导模态的特征,使其在多模态融合中具有更高的质量和有效性
5.动态加权
动态加权是一种机制,通过根据输入数据的特性动态调整各个模态的权重,以实现更有效的特征融合。在DMC模块中,动态加权的主要作用包括:
-
自适应特征融合:根据不同模态的信噪比或重要性,动态调整各模态的权重,确保主导模态(通常是语言模态)在情感分析中占据主导地位。
-
提高鲁棒性:在数据缺失或噪声较大的情况下,动态加权可以降低受损模态的影响,增强主导模态的贡献,从而提高整体模型的鲁棒性。
-
优化学习过程:通过动态调整权重,模型能够更有效地利用可用的信息,优化学习过程,提升情感分析的准确性。
6.基于主导模态的多模态学习(DMML)
DMML(Dominant Modality based Multimodal Learning)是多模态情感分析(MSA)中的一个重要模块,旨在通过利用主导模态的信息来增强模型在多模态环境中的学习和推理能力。DMML的主要功能和特点包括:
1. 主导模态的识别:DMML模块首先识别出主导模态,通常被认为是包含最丰富情感信息的模态(如语言模态)。通过聚焦于主导模态,DMML能够确保模型在情感分析中使用最有效的信息。
2. 融合其他模态:在DMML中,主导模态的特征与其他模态(如视觉和音频模态)的特征进行融合。通过这种融合,DMML能够利用其他模态的信息来补充主导模态,从而提高情感分析的准确性。
3. 自适应注意力机制:DMML通常采用自适应注意力机制,通过计算各模态的相关性和重要性,为不同模态分配不同的权重。这种机制确保了主导模态在情感分析中的主导地位,同时也考虑了其他模态的贡献。
4. 提高鲁棒性:通过强调主导模态并有效融合其他模态,DMML模块增强了模型在面对数据缺失和噪声时的鲁棒性。这使得模型能够在不完整的输入情况下仍然保持良好的性能。
5. 多模态特征表示:DMML模块生成的多模态特征表示能够更全面地捕捉情感信息,结合了主导模态的深层特征和其他模态的补充信息,从而提升了情感分析的效果。
一、引言
1.多模态情感分析的背景
多模态情感分析(MSA)是通过整合不同类型的数据(如视频、音频和文本)来识别和分析人类情感的重要领域。它在医疗保健和人机交互等多个领域具有广泛的应用。
2.研究现状
近年来,MSA的研究趋势逐渐从实验室条件转向自然场景,这为实际应用提供了更广阔的空间。然而,现实环境中的数据往往存在不完整性和噪声问题,例如传感器故障和自动语音识别(ASR)问题,导致情感分析的准确性受到影响。针对多模态情感分析中数据不完整这一主要问题,已经提出了许多有效的解决方案。Yuan等人(2021)引入了一种基于transformer的特征重建机制TFR-Net,旨在通过重建缺 失数据来增强模型处理未对齐多模态序列中随机缺失的鲁棒性。此外,Yuan等人(2024)提出了基于噪声暗示的对抗训练NIAT模型,该模型利用注意机制和对抗学习优势学习原始噪声实例对之间的统一联合表示。最后,Li等人(2024)设计了一个统一的多模态缺失模态自蒸馏框架(UMDF),它利用单个网络从一致的多模态数据分布中学习鲁棒的固有表征。然而,尽管有这些发展,这些模型的评估量度是不一致的,并且评估设置不够全面。这种不一致限制了有效的比较,并阻碍了该领域知识的传播。
3.挑战与需求
由于数据不完整和噪声的影响,传统的MSA方法在处理这些问题时表现不佳。因此,开发鲁棒的MSA方法以提高情感分析的准确性和稳定性显得尤为重要。
4.创新解决方案
本文提出了一种新的模型,即语言主导的抗噪声学习网络(LNLN),以增强MSA对不完整数据的鲁棒性。LNLN的目的是在其他辅助情态的支持下,增强语言情态特征的完整性,该情态因其更丰富的情感线索而被视为主导情态。LNLN对不同程度的数据不完整性的鲁棒性是通过一个用于主导模态构建的主导模态校正(DMC)模块、一个用于多模态融合和分类的基于主导模态的多模态学习(DMML)模块和一个用于重建缺失信息以屏蔽主导模态免受噪声干扰的重构器来实现的。
二、Related Work
1.多模态情感分析的分类
MSA方法可以分为基于上下文的MSA和噪声感知的MSA。大多数现有研究属于基于上下文的MSA,重点在于通过分析模态之间或模态内部的上下文关系来学习统一的多模态表示。
2.基于上下文的MSA的研究
许多研究(如Zadeh等,2017;Tsai等,2019;Yu等,2021等)探索了不同模态之间的关系,Zadeh等人(2017)探索了使用笛卡尔积计算不同模态之间的关系。Tsai等人(2019)利用变压器对来模拟不同模态之间的长期依赖关系。Yu等(2021)提出为每个模态生成伪标签,以进一步挖掘不同模态之间的一致性和差异信息。
3.噪声感知的MSA的研究
近年来,针对数据缺失和噪声影响的问题,提出了一些新方法(如Mittal等,2020;Yuan等,2021, 2024)。这些研究强调了在多模态情感分析中提高鲁棒性的重要性。例如,Mittal等(2020)引入了模态检查步骤,以区分有效和无效的模态。
4.现有方法的局限性
尽管已有研究在多模态情感分析方面取得了一定的进展,但基于上下文的方法在面对不同程度的噪声时通常表现不佳。这为未来的研究提供了改进的方向。
5.我们提出的方法
在这项工作中,LNLN属于噪声感知的MSA类别。受Zhang等人(2023)的启发,我们探索了语言引导机制抵抗噪声的能力,旨在为噪声场景下的MSA研究提供新的视角。
三、方法
1.模型框架
在鲁棒多模态情感分析中,所提出的语言主导的抗噪声学习网络(LNLN)的整体流程如图所示:
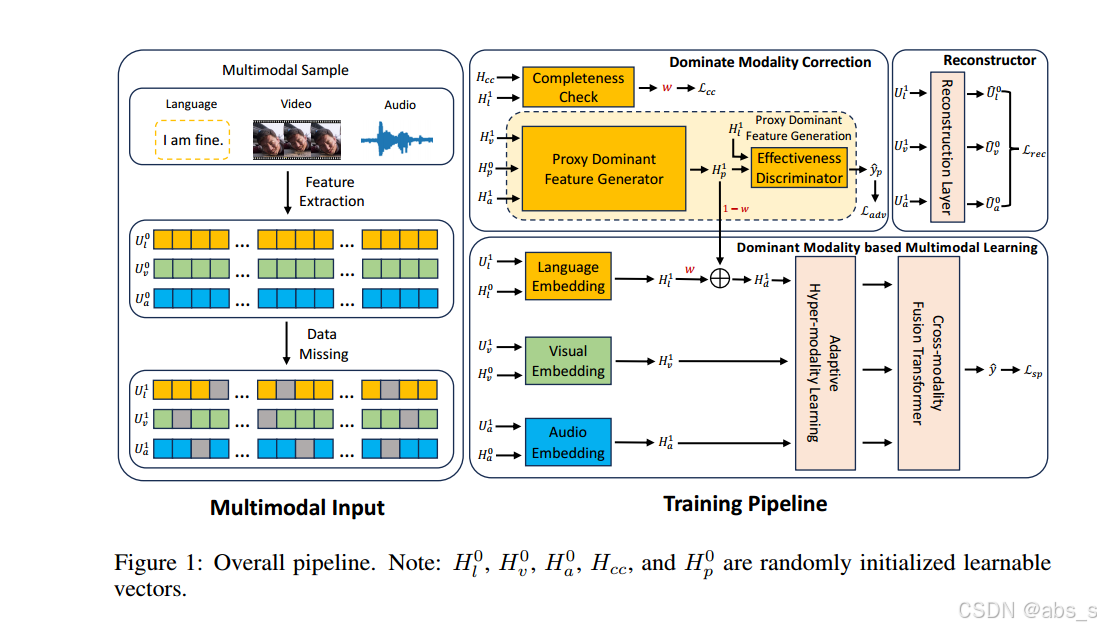
如上所述,关键的初始步骤包括形成随机数据缺失的多模态输入,这为LNLN训练奠定了基础。一旦准备好输入,LNLN首先利用嵌入层来标准化每个模态的维度,以确保均匀性。认识到语言是MSA中的主导模态,专门设计的主导模态校正(DMC)模块采用对抗学习和动态加权增强策略来减轻噪声影响。
该模块首先提高从语言模态中计算出的主导特征的质量,然后将其与辅助模态(视觉和音频)集成到基于主导模态的多模态学习(DMML)模块中,实现有效的多模态融合和分类。这一过程显著增强了LNLN对各种噪声水平的稳健性。此外,为了完善网络的细粒度情感分析能力,实现了一个简单的重构器来重建缺失数据,进一步增强了系统的鲁棒性。
2.输入结构和多模态输入
1. 输入构建
随机数据缺失:为了应对随机数据缺失的挑战,研究者基于MOSI、MOSEI和SIMS数据集构建了模拟数据集。具体方法是对每种模态随机擦除不同比例的信息(从0%到100%),以模拟缺失数据的情况。
信息填充:对于视觉和音频模态,擦除的信息用零填充;而对于语言模态,则用[UNK](表示未知词)填充,以适应BERT模型的需求。
2. 多模态输入
模态整合:每个样本包含三种模态的数据:语言、音频和视觉数据。与之前的研究一致,采用了广泛使用的工具进行处理:语言数据使用BERT编码,音频特征通过Librosa提取,视觉特征则使用OpenFace获取。
输入表示:经过预处理的输入被表示为序列,记作
![]()
其中 m代表模态类型(语言、视觉、音频),Tm 表示序列长度,dm 表示每种模态向量的维度。
噪声影响:在获得的Um0上应用随机数据缺失,形成噪声污染的多模态输入 Um1。
3.基于主导模态的多模态学习
我们在设计DMC模块和Reconstructor的基础上改进了ALMT,从而实现了基于主导模态的DMML模块,用于随机数据缺失场景下的情感分析。
特征提取:对于多模态输入U 1 m,我们采用嵌入编码器E 1 m和两个Transformer编码器层来提取和统一特征。每种模态都以随机初始化的低维令牌H0 m∈R T ×dm开始。然后,Transformer编码器层对这些令牌进行处理,嵌入基本的模态信息并产生统一的特征,表示为H1 m∈R T ×d
![]()
自适应超模态学习:AHL模块包含一个Transformer编码器和两个多头注意力(MHA)模块。这些组件共同工作,以学习不同尺度的语言表示和从视觉及音频模态中提取超模态表示。考虑到语言模态可能会因数据缺失而受到严重干扰,AHL模块通过引入主导模态修正(DMC)模块来生成代理主导特征 Hp1并构建修正后的主导特征 Hd1。修正后的主导表示 Hdi 在不同层次的学习过程可以表示为:
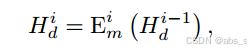
式中,i∈{2,3}表示自适应超模态学习模块的第i层,Eim表示Transformer编码器的第i层,Hi d∈R T ×d表示不同尺度下的校正主导特征。
为了学习超模态表示,使用校正后的主导特征和音频/视觉特征分别计算Query和Key/Value。
![]()
多模态融合与预测:利用得到的H3 d和H3 hyper,利用深度为4层的分类器Transformer编码器进行多模态融合和情绪预测:
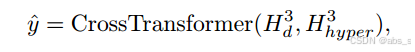
4.主导模态校正
该模块包括两个步骤,即优势模态的完备性检查和使用对抗学习生成代理优势特征。
完备性检查:我们应用了一个编码器Ecc,它由一个深度为两层的Transformer编码器和一个用于完整性检查的分类器组成。
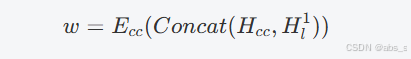
其中,Hcc是用于完整性预测的随机初始化特征,Hl1是语言模态的特征。通过连接这两个特征,网络能够学习到模态的完整性。
为了优化完整性预测,使用以下损失函数:
代理主导特征生成:代理主导特征 Hp1 是通过结合不同模态的特征生成的。具体过程如下:
EDFG 是代理主导特征生成器。
Hp0 是随机初始化的主导特征向量。
Ha1和 Hv1分别是音频和视觉模态的特征。
θDFG是生成器的参数。
生成的代理主导特征 Hp1进一步与语言特征 Hl1 结合,生成修正后的主导特征 Hd1。这一过程通过加权平均实现:
代理主导特征生成器和有效性鉴别器之间采用对抗学习结构。有效性鉴别器的任务是判断输入特征是否源自语言模态,而生成器则试图挑战鉴别器的能力,以提高生成特征的质量。
对抗学习的目标:
5.重构器
重构器由两个Transformer层组成,旨在有效地重建每种模态的缺失信息。其操作方程为:
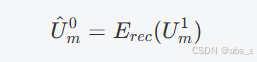
U^m0 是重建的特征,表示与原始特征 Um0 对应的重构结果。
Um1是经过随机数据缺失处理后的输入特征。
为了优化重构器的性能,采用L2损失函数进行训练:
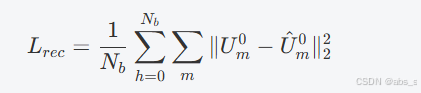
6.整体学习目标
最终情感预测损失Lsp:
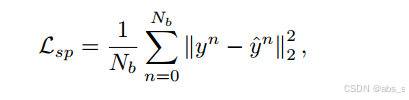
整体损失 L:
![]()
其中 Lcc是完整性检查损失,Ladv是对抗学习损失,Lrec是重构损失,Lsp 是情感预测损失。其中α, β, γ和δ是超参数。
四、实验分析
1.数据集
MOSI 数据集:MOSI(Multimodal Opinion Sentiment Intensity)数据集包含2,199个多模态样本,整合了视觉、音频和语言模态。
MOSEI 数据集:MOSEI(Multimodal Sentiment Analysis in the Wild)数据集由22,856个视频剪辑组成,这些剪辑来自YouTube。
SIMS 数据集:SIMS(Sentiment Intensity in Movies and Series)数据集是一个中文多模态情感数据集,包含2,281个视频剪辑,来源于不同的电影和电视剧。
2.实验设置
缺失率设定:实验设置了10次实验,缺失率从0到0.9,步长为0.1,模拟不同程度的数据缺失。
评估指标:
二分类准确率(Acc-2)
F1分数
平均绝对误差(MAE)
三分类准确率(Acc-3)
七分类准确率(Acc-7)
与人类预测的相关性(Corr)
3.实验实施
使用PyTorch 2.2.1进行模型实现,实验在AMD EPYC 7513 CPU和NVIDIA Tesla A40 GPU上进行。
为确保实验的公平性,使用固定随机种子进行多次实验,并记录不同模型的表现。
4. 实验结果
鲁棒性比较:实验结果表明,LNLN模型在大多数指标上表现出色,特别是在MOSI数据集上,相比于次优结果MMIM,Acc-7的相对提升达到了9.46%。
模型性能:不同模型在不同缺失率下的表现有所不同,随着缺失率的增加,所有模型的预测结果趋向于某些特定类别,表明在高噪声环境下模型的学习能力受到限制。
详细结果请参考论文。
5.实验的局限性
由于缺失率为1.0的实验未进行,可能限制了对极端缺失情况下模型表现的全面理解。
不同模型的超参数设置可能影响实验结果的可比性。
五、结论
1. 研究贡献
多模态情感分析的有效性:本文强调了多模态情感分析在处理情感数据时的优势,特别是在面对不同模态的缺失和噪声时,能够有效提升情感识别的准确性和鲁棒性。
2. 模型表现
模型的鲁棒性:通过实验结果,本文展示了所提出的模型在高缺失率场景下仍能保持较好的性能,表明模型在应对数据缺失时具有较强的适应能力。
不同模态的重要性:研究表明,语言模态在情感分析中通常是最重要的,但其他模态(如视觉和音频)也能提供有价值的信息,特别是在特定情境下。
3. 未来研究方向
对噪声的处理:本文指出,尽管当前模型在一定程度上处理了噪声和缺失数据,但仍有提升空间,未来的研究可以进一步探索更为有效的噪声处理机制。
模型的可扩展性:建议未来的工作可以考虑将模型扩展到更多的模态和更复杂的场景,以提高情感分析的全面性和适用性。
4. 实践应用
实际应用潜力:本文的研究成果为多模态情感分析在实际应用中的推广提供了理论基础,尤其是在社交媒体监测、客户反馈分析等领域。


















 841
841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









