






一、引言
尽管多模态情感分析是一个值得进一步研究的沃土,但目前的方法占用了很高的注释成本,并且存在标签模糊、对高质量标记数据采集不友好的问题。此外,选择正确的相互作用至关重要,因为模态内或模态间相互作用的重要性在不同的样本中可能有所不同。为此,我们提出了Semi-IIN,一种用于多模态情感分析的半监督模态内交互学习网络。Semi-IIN集成了掩蔽注意力和门控机制,在独立捕获模态内和模态间交互信息后实现了有效的动态选择。结合自训练方法,Semi-IIN充分利用了从未标记数据中学习到的知识。
二、方法
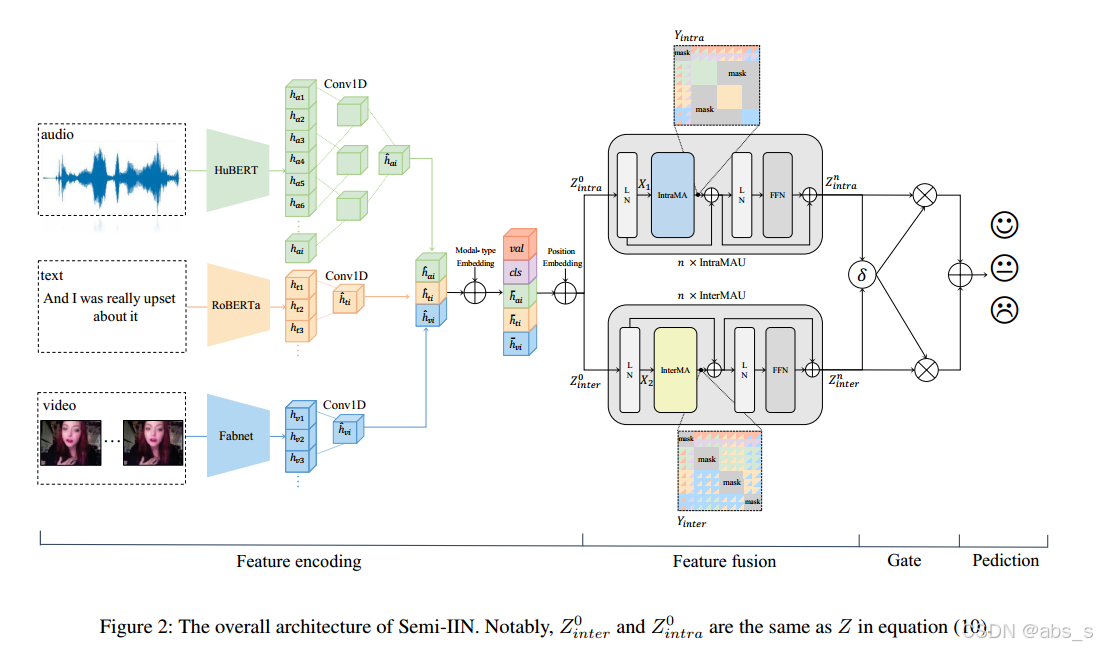
掩蔽注意力机制
掩蔽注意力机制(Masked Attention Mechanism)是多模态情感分析中的关键部分,旨在提高模型对情感信息的提取能力,并减少不相关信息的干扰。该机制分为两种主要类型:Intra-modal Masked Attention(模态内掩蔽注意力)和Inter-modal Masked Attention(模态间掩蔽注意力)。
Intra-modal Masked Attention(模态内掩蔽注意力)主要用于同一模态内部的信息交互。掩蔽同一模态内不相关的信息,以确保模型只关注与当前情感分析任务相关的特征。在此过程中,定义一个掩蔽矩阵 IntraMASK,该矩阵的作用是将输入中不相关的特征进行屏蔽,使得它们对模型的影响为零。
模态间掩蔽注意力(Inter-modal Masked Attention)
Inter-modal Masked Attention(模态间掩蔽注意力)用于不同模态之间的信息交互。由于不同模态(文本、视觉、音频等)之间的特征并不总是完全匹配,因此掩蔽不相关的模态间交互信息是十分必要的。通过模态间掩蔽注意力机制,可以确保不同模态之间只交换有用的情感信息。类似于模态内掩蔽注意力,InterMASK 是用于掩蔽不同模态之间不相关信息的矩阵。
门控机制通过引入动态的“门控”策略来管理不同模态的信息流动,它能够灵活地控制每个模态及模态间信息的传递,优化多模态信息的融合过程。
自训练策略
为了进一步提升模型的性能,本文设计了一种自训练策略,利用未标注的数据进行情感知识的蒸馏。具体步骤如下:
1.使用有标签数据训练模型。
2.用训练好的模型(记为 φφ)对未标注数据进行预测。
3.采用Top-k信心法过滤掉不可靠的样本,以提高训练数据的质量。
三、实验
数据集:
CMU-MOSI:包含来自在线视频的情感数据,主要用于情感分析和情绪识别。
CMU-MOSEI:更大规模的情感分析数据集,涉及更多的情绪标签,包含音频、视频和文本模态。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









