






一、引言
在多模态情感分析(MSA)中,模型通常需要整合来自不同模态(如文本、视觉和音频)的信息,以更好地理解和预测情感。然而,现实中的多模态数据往往存在冗余和冲突的情况,尤其是视觉和音频模态,它们可能包含与情感分析无关的信息,导致情感预测的性能下降。为了克服这些挑战,本文提出了一种新的方法,称为自适应语言引导的多模态变换器(ALMT)。ALMT的核心思想是通过自适应超模态学习(AHL)模块,利用语言特征的不同尺度来引导视觉和音频模态,生成一个互补的超模态表示,从而减少无关信息的干扰。该方法不仅能够处理多模态数据中的冗余信息,还能提高情感分析的鲁棒性和准确性。
二、关键点
一、语言主导
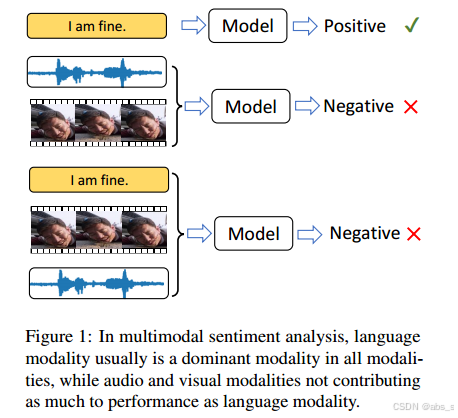
在多模态情绪分析中,语言模态通常是所有模态中的主导模态,而音频和视觉模态对表现的贡献不如语言模态。
二、解决问题
尽管现有的MSA方法取得了较好进展,仍存在一定挑战。具体而言,不同模态的数据贡献是不同的,其中语言模态通常占据主导地位,而视觉和音频模态在情感识别中的作用相对较小。此外,不同模态间的无关信息(如视频中的背景噪声或音频中的环境干扰)可能会影响情感分析的效果,尤其是在视觉和音频模态中,非主导信息的干扰可能会显著降低模型的性能。
基于上述问题,我们提出了一种新的自适应语言引导多模态变换器(ALMT),通过解决视觉和音频模态中破坏性信息的不利影响来提高MSA的性能。
三、本文贡献
我们提出了一种新颖的自适应语言引导的多模态变换器(ALMT),旨在通过解决视觉和音频模态中干扰信息的负面影响,提升多模态情感分析(MSA)的性能。在ALMT中,每种模态首先通过使用带有初始化标记的变换器转化为统一的形式。此操作不仅抑制了模态间的冗余信息,还压缩了长序列的长度,从而便于模型计算。接着,我们引入了一个自适应超模态学习(AHL)模块,该模块利用具有主导性的不同尺度的语言特征,指导视觉和音频模态生成中间超模态标记,该标记包含更少的与情感无关的信息。最后,我们应用了一个跨模态融合变换器,其中语言特征作为查询,超模态特征作为键和值。通过这种方式,语言与视觉和音频模态之间的互补关系被隐式推理,从而实现了鲁棒且准确的情感预测。
-
提出了自适应语言引导的多模态变换器(ALMT):这是一种新的多模态情感分析方法,首次显式地处理了辅助模态(即视觉和音频模态)中冗余和冲突信息的负面影响,从而提高了情感理解的鲁棒性和准确性。
-
引入自适应超模态学习(AHL)模块:AHL模块通过使用不同尺度的语言特征来引导视觉和音频模态,生成一个互补的超模态表示。该表示包含更少的情感无关信息,从而提升了情感分析模型的性能。
-
创新的跨模态融合框架:本文提出的跨模态融合变换器利用语言特征作为查询,并将超模态特征作为键和值进行融合。通过这种方式,模型能够更好地推理语言与视觉、音频模态之间的互补关系,从而实现更加准确的情感预测。
三、方法
一、总体框架
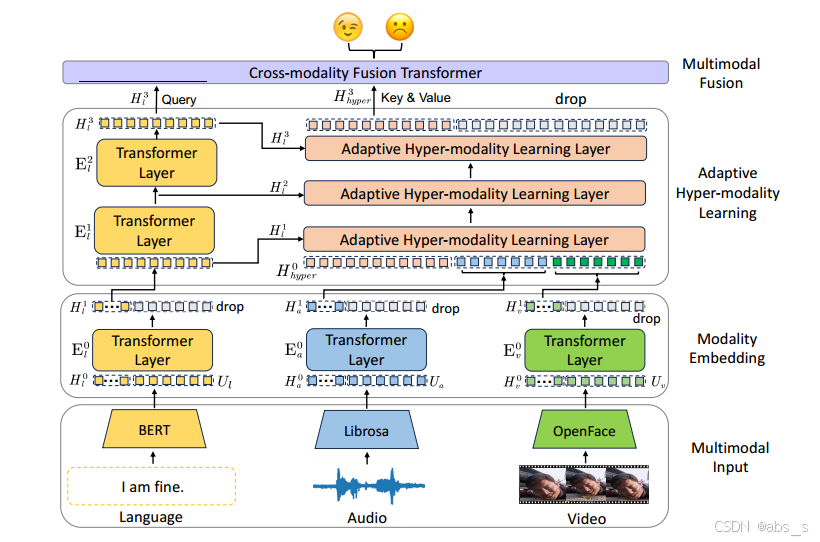
图2:所提出的ALMT用于多模态情感分析(MSA)的处理流程。对于多模态输入,我们首先应用三个变换器层来嵌入具有低冗余的模态特征。然后,我们采用超模态学习(AHL)模块,在不同尺度的语言特征引导下,从视觉和音频模态中学习超模态表示。最后,应用跨模态融合变换器,根据超模态特征与语言特征的关系进行融合,从而获得一个互补的联合表示用于情感分析(MSA)。
二、自适应超模态学习
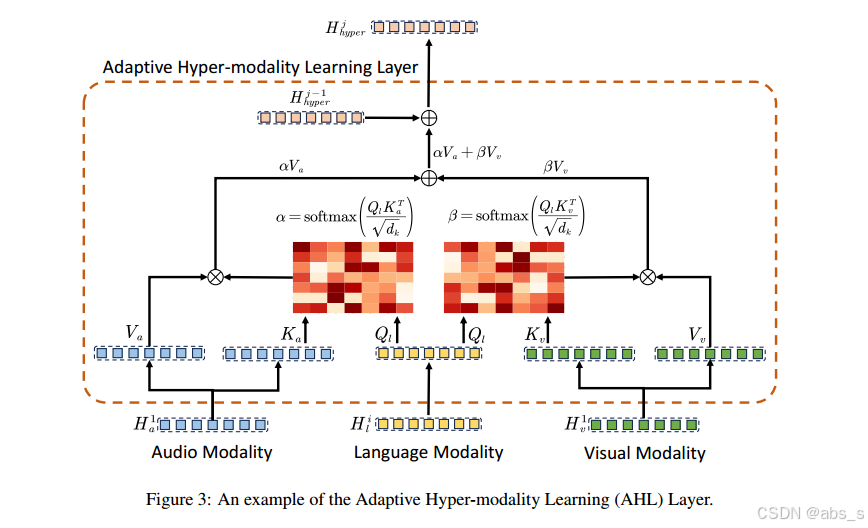
AHL模块通过多尺度的语言特征指导视觉和音频模态的学习,生成精炼的超模态表示。
语言特征的多尺度学习:通过Transformer从不同尺度(低、中、高)获取语言特征表示。
计算相似性矩阵:使用多头注意力机制计算语言特征与音频和视觉特征之间的相似性。
更新超模态特征:根据相似性矩阵 α 和 β,更新超模态特征。
三、跨模态融合变换器
特征融合:通过跨模态融合变换器(CrossTrans)融合语言特征 HlHl 和超模态特征 HhyperHhyper,从而获得一个联合的多模态表示。
跨模态融合:通过CrossTrans(跨模态融合变换器)进行特征融合,得到联合的多模态表示 H。
四、情感分析
分类器:最后,对跨模态融合后的联合表示 H 应用分类器,得到情感分析的最终输出 y^。
四、实验
我们在三个流行的三模态数据集上进行了广泛的实验(即MOSI(Zadeh等人,2016)、MOSEI(Zadech等人,2018)和CHSIMS(Yu等人,2020))。
五、结论
本文提出了自适应语言引导的多模态变换器(ALMT)模型,以提升多模态情感分析(MSA)的性能。ALMT通过有效处理视觉和音频模态中的干扰信息,增强了情感分析的准确性和鲁棒性。模型创新性地通过引入初始化标记的变换器,将每种模态转化为统一形式,抑制冗余信息并缩短序列长度,从而提高计算效率。同时,结合自适应超模态学习(AHL)模块,通过不同尺度的语言特征引导视觉和音频模态,生成更少情感无关的信息。ALMT还采用了跨模态融合变换器,增强了语言与视觉、音频模态之间的互补关系,促进了情感分析的精确推理。实验结果表明,ALMT在多个公开数据集上表现优异,特别是在处理复杂场景下的情感信息提取时,具有显著优势,验证了其有效性和创新性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









