



前言:
因为课程作业的缘故,接触到kaggle大赛(注:之前只是用kaggle跑过深度学习相关的代码,未接触过大赛)因此在这里,做一个基础的学习记录
参考链接:https://www.kaggle.com/code/gusthema/identifying-age-related-conditions-w-tfdf
主要参考上述链接进行相关学习
kaggle平台链接:https://www.kaggle.com/
赛题介绍:
赛题背景
1-随着年龄的增长会带来一大堆健康问题。从心脏病和痴呆到听力损失和关节炎,衰老是许多疾病和并发症的危险因素。
2-不断发展的生物信息学领域,也越来越关注与年龄相关的疾病,对其干预措施有着浓厚的研究兴趣。
3-即使数据样本数量很少,数据科学也可以开发新方法来解决各种数据问题。
赛题其他信息

包括赛题类型、赛题模型要求、赛题任务、比赛主办方、赛题评价指标
赛题分析:
数据集分析
数据集介绍
1-train.csv - 训练集
Id:唯一标识符。
AB-GL:56 个匿名健康特征。
Class:1表示已被诊断出患有三种情况之一,0表示没有。
2-test.csv - 测试集
目标是预测这个集合中的每个对象属于两个类别的概率。
3-greeks.csv - 补充元数据,仅适用于训练集
Alpha :标识是否存在与年龄相关的情况
Beta Gamma Delta:三个实验特征
Epsilon :收集此受试者数据的日期。请注意,测试集中所有数据均在训练集收集之后收集。
4-sample_submission.csv - 格式正确的示例提交文件
针对train数据集进行分析
1-分别使用Pandas库函数:
dataset_df.head() :这个函数返回对象的前5行(默认情况下)。它可以帮助快速查看数据集中的样本数据,以了解数据的大致结构和内容
dataset_df.describe() :生成数据集中数值列的统计摘要信息。对于每一列,它会计算并返回计数、平均值、标准差、最小值、四分位数(25%、50%或中位数、75%)以及最大值

为了更加直观的观察,将特征属性数值可视化(这里只展示前两个特征)

2-进一步分析
因为此次比赛数据量较少,且为二元(0/1)分类比赛,因此训练数据中的class列0与1的分布需要格外进行关注,判断是否存在样本极度不均衡的问题,因此将class这一列单独可视化,进行观察:
而从饼图中我们可以看到数据集严重不平衡,正样本(1)的比例与负样本(0)相比非常小
3-划分训练数据集
介于上述分析的数据特性,在这里选择KFold交叉验证来将train里面的数据进行划分,用于后续模型的训练和测试验证。

4-模型选择
基于前述分析,本次实验选择了树类模型
树模型包含很多种类
具体选择:基于TensorFlow Decision Forests (TF-DF) 的使用Keras 接口实现的 RandomForestModel、GradientBoostedTreesModel、CartModel三类模型(易于集成到 TensorFlow 生态系统中,具备较好的可解释性)
分别进行实验

赛题解决流程概述
注:代码实现过程均在kaggle自带的编译环境
赛题实验情况
1-处理不平衡数据

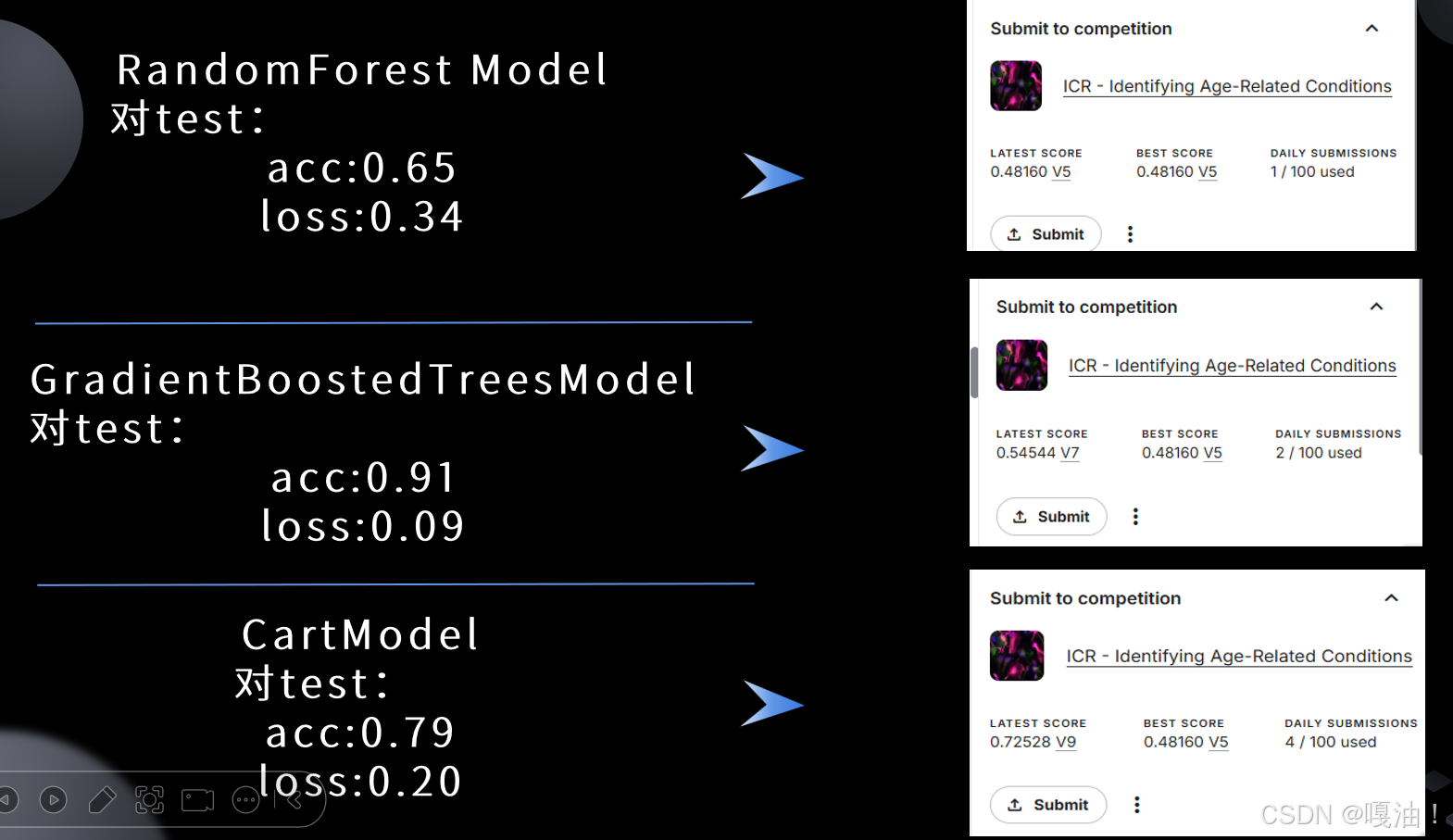
2-选择/定义/训练测试模型
注:这里以RandomForestModel为例

对模型进行可视化(模型的解释性)
1-关于RandomForestModel-fold_1-可视化

2-关于GradientBoostedTreesModel-fold_1-可视化

3-关于CartModel-fold_1-可视化

3-训练完毕后-模型相关指标
注:通过特征对模型贡献量的评估,发现这几个匿名健康特征(DU FL BQ)贡献较高,或许与某类/多类疾病关联性较强。
赛题提交结果
赛题思考与讨论
1-此次实验没有选择使用数据集greek;
但经过学习发现,greek由于它的特殊列,可以灵活的进行数据表的连接以及在验证时数据分割
2-实验使用的都是模型的默认参数,且都是基于参考链接,或许可以更近一步的调参,优化模型;关于树模型的选择还有很多种类型,除过树模型还有其他解法
3-处理数据不平衡类相关问题,还有很多其他方法(如:下采样等)值得实验和学习
补充:金牌方案分享

碎碎念:kaggle是一个很好的关于各类机器学习知识学习的地方,也有较为强大的编译环境与GPU资源,可以将别人开源分享的notebook直接上手进行学习或编辑。也希望这篇博客可以帮助大家对这个比赛有个简单的基础了解。

















 1194
1194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









