



CLAM :在整个幻灯片图像上有效的数据有效且弱监督的计算病理学
github:https://github.com/mahmoodlab/CLAM
1 摘要
| 维度 | 要点 |
|---|---|
| Background | 全切片图像(WSI)十亿像素,人工标注几乎不可行。 |
| Challenge | ① 仅 slide-level 标签;② 需多类亚型;③ 数据量小;④ 可解释 & 跨域。 |
| Method | CLAM = 多分支 Attention-MIL + 在线实例聚类正则(instance-level clustering)。 |
| Contribution | 1. 首次让弱监督 MIL 支持多类互斥任务;2. 小样本(≈100 张)即可收敛;3. 生成 pixel-level 可解释 heat-map;4. 零微调适配活检、手机显微镜图像。 |
2 引言
- 背景:数字病理 + AI → 客观诊断、预后预测。
- 挑战:ROI 标注昂贵;max-pooling MIL 仅二分类;大公开数据集往往 <2k 张。
- 研究现状(脉络级):
- 2018 Ilse → Attention 替代 max-pooling,但仍二分类;
- 2019 Campanella → 千张级数据,临床级性能,但仅肿瘤/正常;
- 2020 CLAM → 多分支 Attention + 聚类正则,打通多类 & 小样本任督二脉。
- 提出新方法:CLAM 框架(下一节公式级展开)。
3 相关工作
| 研究问题 | 代表方法 | 不足 |
|---|---|---|
| 二分类弱监督 | max-MIL | 仅单类,梯度信号=1 patch |
| Attention-MIL | Ilse et al. | 仍二分类,无 patch 级监督 |
| 多类 & 小样本 | CLAM(本文) | —— |
4 预定义:输入 vs 输出
- 输入:一张 WSI + slide-level 标签
y ∈ {0,1,…,n-1},零 patch 标注。 - 输出:
① slide 预测分布p(y|slide);
② 每 patch 对每类 attention 分数a_{k,m}(用于 heat-map);
③ patch 级聚类伪标签(训练阶段自用)。
5 方法
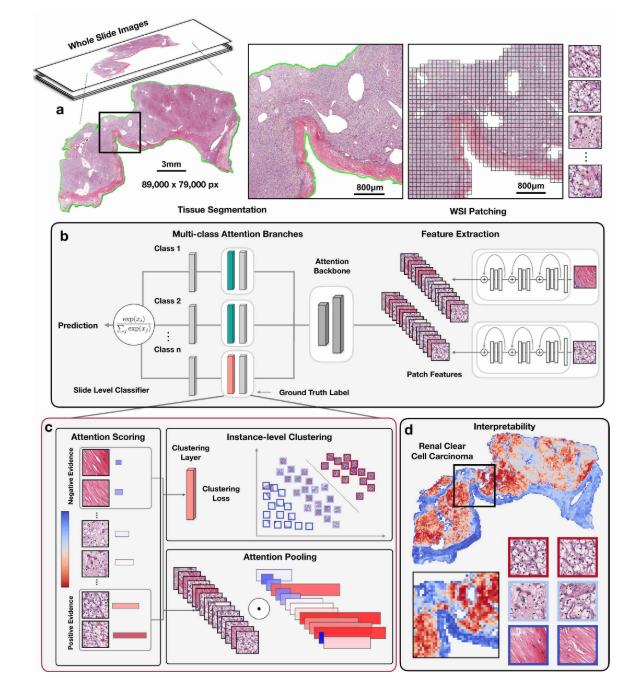
5.1 总览流程
WSI → 分割 → 256×256 patch → ResNet50 → 1024-d 特征 h_k
↓
CLAM 模型
├─ 多分支 Attention → slide 表示 h_slide,m
├─ 分类层 → slide 预测 s_slide,m
└─ 聚类层 → 伪标签 + smooth SVM 损失
5.2 多分支 Attention 池化(默认即 multi-branch)
对类别 m 单独学习一条子网:
a_{k,m} = exp( w_{a,m}^T ( tanh(V_a h_k) ⊙ σ(U_a h_k) ) )
/ Σ_{j=1}^N exp( w_{a,m}^T ( tanh(V_a h_j) ⊙ σ(U_a h_j) ) )
| 符号 | 维度 | 物理含义 |
|---|---|---|
a_{k,m} | 1×1 scalar | 第 k 个 patch 对类别 m 的 attention 权重(归一化后) |
k | 整数索引 | patch 序号,k = 1 … N |
m | 整数索引 | 类别序号,m = 0 … n-1 |
N | 整数 | 当前 WSI 的 patch 总数 |
n | 整数 | 分类任务类别数(RCC 3 类,NSCLC 2 类) |
h_k | 512×1 vector | 第 k 个 patch 的压缩特征(由 ResNet50 → FC 得到) |
V_a | 256×512 matrix | 共享 attention backbone,负责提取“候选激活” |
U_a | 256×512 matrix | 共享 attention backbone,负责提取“门控信号” |
tanh | 元素级 | 双曲正切,输出 (-1,1) |
σ | 元素级 | Sigmoid,输出 (0,1) |
⊙ | 元素级 | Hadamard 乘,完成自门控(self-gating) |
w_{a,m} | 1×256 vector | 类别 m 专用 的 attention 向量,决定“看哪里” |
| 分母求和 | 标量 | 整张切片所有 patch 的指数和,完成 softmax 归一化 |
slide 级表示:
h_slide,m = Σ_{k=1}^N a_{k,m} h_k
| 符号 | 维度 | 物理含义 |
|---|---|---|
h_{slide,m} | 512×1 vector | 类别 m 的 slide 级特征,后续送入分类器 |
a_{k,m} | 1×1 scalar | 公式 ① 输出的权重,非负且 Σ=1 |
h_k | 512×1 vector | 同上,单 patch 特征 |
logit:
s_slide,m = w_{c,m}^T h_slide,m
| 符号 | 维度 | 物理含义 |
|---|---|---|
s_{slide,m} | 1×1 scalar | 类别 m 的未归一化 logit,后续送 softmax |
w_{c,m} | 512×1 vector | 类别 m 专用 的分类权重,与 attention 向量一一对应 |
✅ 注 1:slide 表示是全部 patch 的加权平均,非 top-K 采样;权重即
a_{k,m}。
补充:
单 patch 特征 h_k(512) ──► Va(256×512) ──► tanh(256) ──►⊙──► w_a,m(1×256) ──► a_k,m(1)
▲
└─── Ua(256×512) ──► σ(256)
所有 a_k,m ──► 加权平均 ──► h_slide,m(512) ──► w_c,m(512) ──► s_slide,m(1)
Va、Ua 是“共享底座”,w_a,m 决定“看哪里”,w_c,m 决定“看完怎么判”;
a_{k,m} 是软权重,h_{slide,m} 是软加权和,s_{slide,m} 是最终打分。
5.3 在线实例聚类(核心创新)
目的:让“高分 patch 确实像该类,低分 patch 确实不像”。
步骤(每轮前向动态完成):
-
对真实类别
Y- 升序排序
a_{k,Y}→ 最低B个 → 伪标签0(负证据) - 最高
B个 → 伪标签1(正证据)
- 升序排序
-
对互斥类别
m≠Y(亚型任务)- 最高
B个 → 全部打0(假阳性证据)
- 最高
-
用 2-神经元聚类网
W_inst,m预测并计算 smooth-top1-SVM 损失:
L_cluster = τ log( 1 + exp( (α + s_neg − s_pos)/τ ) )
总损失:
L_total = c₁ L_cls + c₂ L_cluster
✅ 注 2:slide 标签
Y仅用于
- 分类分支的 cross-entropy;
- 生成聚类伪标签。
attention 分数本身不会被Y直接监管,否则退化为弱监督分割。
✅ 注 3:二分类聚类任务 = patch 级正则器,强制特征空间“正负证据线性可分”,从而
- 提升小样本收敛速度;
- 降低 attention 噪声;
- 使 heat-map 更贴近病理形态。
5.4 clam_sb vs clam_mb
注:自己实际用小规模复现 看到网络上有已有的这两中方法 担心混淆 进行简单整理
| 名称 | 实质 | 是否原论文 |
|---|---|---|
| clam_mb | 默认实现:每类独享一条 attention 分支(即公式上方)。 | ✅ 原论文唯一结构 |
| clam_sb | 后人消融:所有类别共享同一套 attention 权重,只留一个分支。 | ❌ 非原论文,仅用于对比实验 |
因此 CLAM 本身只有 multi-branch,sb 是社区为验证“是否值得每类学一套 attention”而人为砍掉的 baseline。
6 实验(数据集-设置-结果-原因)
| 任务 | 数据 | 类别 | 规模 | AUC(100%) | AUC(25%) |
|---|---|---|---|---|---|
| RCC 亚型 | TCGA-Kidney | 3 | 884 | 0.991 | 0.944 |
| NSCLC 亚型 | TCGA+CPTAC | 2 | 1967 | 0.956 | 0.920 |
| 乳腺转移 | Cam16+17 | 2 | 899 | 0.953 | 0.910 |
跨域:TCGA→BWH 活检/手机图像,零微调 AUC 仍 >0.90。
可视化:attention heat-map 与病理标注重合度 >90%。
7 结论
- 背景:计算病理需要弱监督、多类、小样本、可解释方案。
- 方法:CLAM = 多分支 Attention + 在线聚类正则。
- 效果:数百张 slide 即可取得 >0.95 AUC,且可解释 & 跨域。
- 展望:结合图神经网络、自监督预训练,向预后预测、治疗响应拓展。
8 句子小积累
| 中文 | English |
|---|---|
| 1. CLAM 首次把多分支 Attention-MIL 与在线实例聚类耦合,使弱监督病理图像分类跨入“小样本+多类+可解释”三位一体时代。 | CLAM, for the first time, couples multi-branch Attention-MIL with online instance clustering, ushering weakly-supervised histopathology into an era where “small data, multi-class, and interpretability” are achieved simultaneously. |
| 2. 全部 patch 参与加权平均,而非 top-K 采样——这是 CLAM 数据效率的公式级保证。 | Every patch contributes to the slide-level representation via attention-weighted averaging, not top-K sampling—a formula-level guarantee of CLAM’s data efficiency. |
| 3. 二分类聚类并非额外负担,而是 patch 特征空间的“隐形正则器”,让 attention 高分区真正对齐病理形态。 | The binary clustering task is not an extra burden, but an implicit regularizer in the patch feature space, forcing high-attention regions to align with real pathological morphology. |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









