



作者B站视频讲解链接 MAPPO的代码框架解析_哔哩哔哩_bilibili
入口程序是train,我把train复制了一下。
train中的关键代码分为三部分:
(1)参数配置 get_config() 需要我们改成自己需要的参数。
(2)环境配置 make_train_env(训练环境),make_eval_env(评估环境),可以配置线程的并行数。我用的是离散环境,因此选择DiscreteActionEnv(),链接进去,EnvCore(),就是我们需要替换的环境。里面有reset和step两个方法,step方法我们自己改写。
(3)run训练模型。
0.模型训练 中的一些函数及意义:
| np.concatenate | (按设定)合并数组 |
| np.split | 将一个数组拆分为多个子数组 |
| x.detach().cpu().numpy() | 将张量(Tensor)从GPU(如果有的话)转移到CPU上,并且从计算图中分离出来,最后转换成NumPy数组 |
1.此代码中,actor和critic网络用的都是RNN。强化学习模型中,比如AC网络,是否可以用RNN/CNN做Actor和Critic网络?
答:是可以的,如果输入的数据是时序相关的,可以用RNN提取时序特征,但训练会变复杂,可能出现梯度爆炸和梯度消失的问题。CNN可以用于提取具有空间特征的输入。因此,网络不一定是DNN。
RNN中的RNN_State:为了将时序影响考虑进入模型,将前一时刻的RNN网络状态同时作为输入,就是前一时刻网络的状态。
RNN:【循环神经网络】5分钟搞懂RNN,3D动画深入浅出_哔哩哔哩_bilibili
2.什么是梯度爆炸和梯度消失?
当网络深度较深时,会有梯度爆炸和梯度消失的现象。
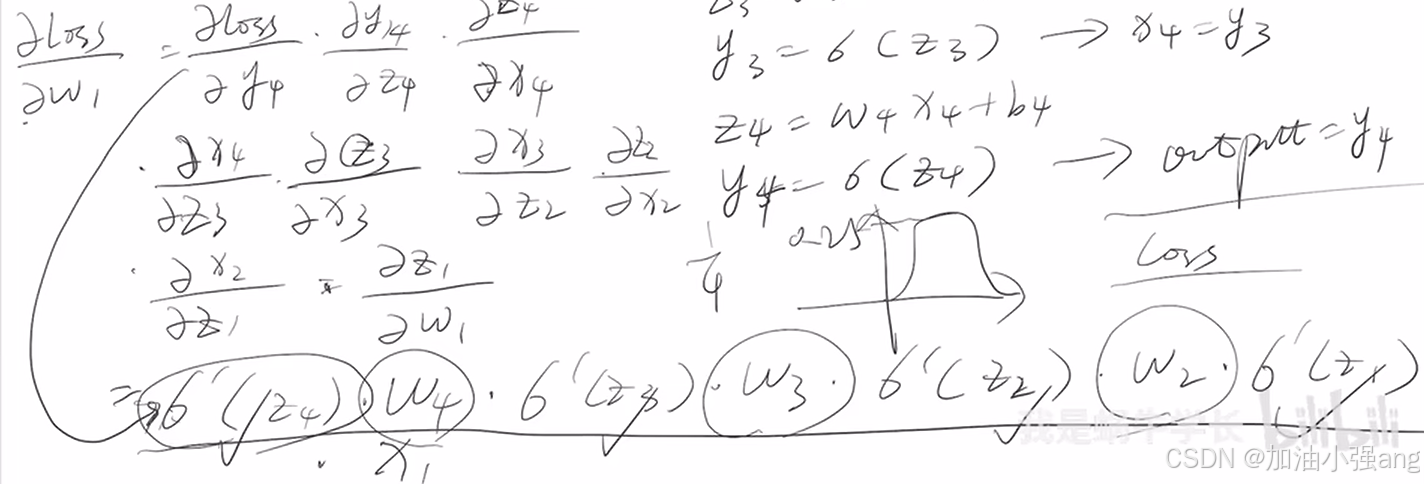
深度神经网络(DNN)的梯度消失和梯度爆炸问题,从理论推导出发深度理解梯度消失和爆炸_哔哩哔哩_bilibili
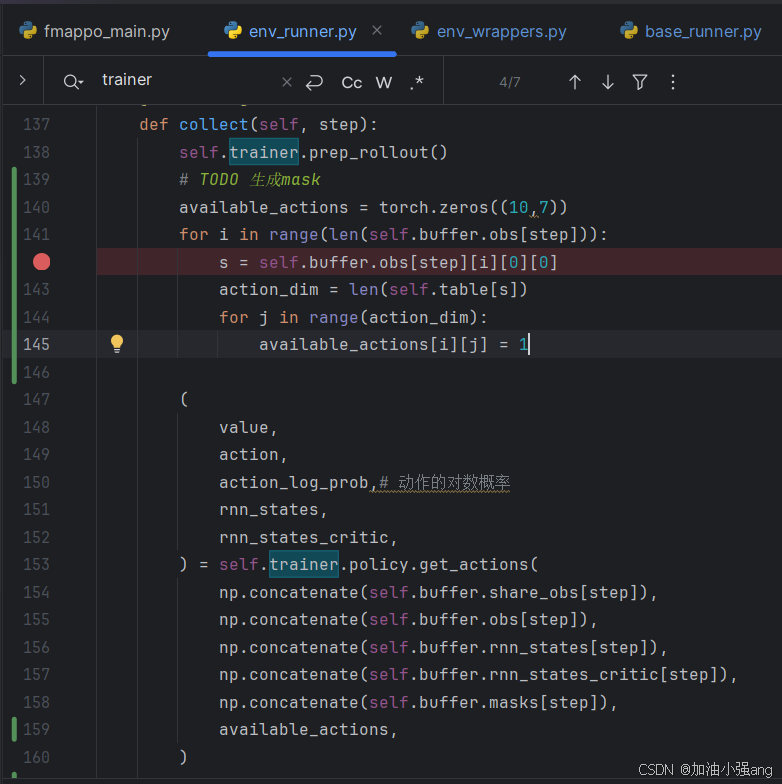
3.在哪里做动作的mask?怎么mask
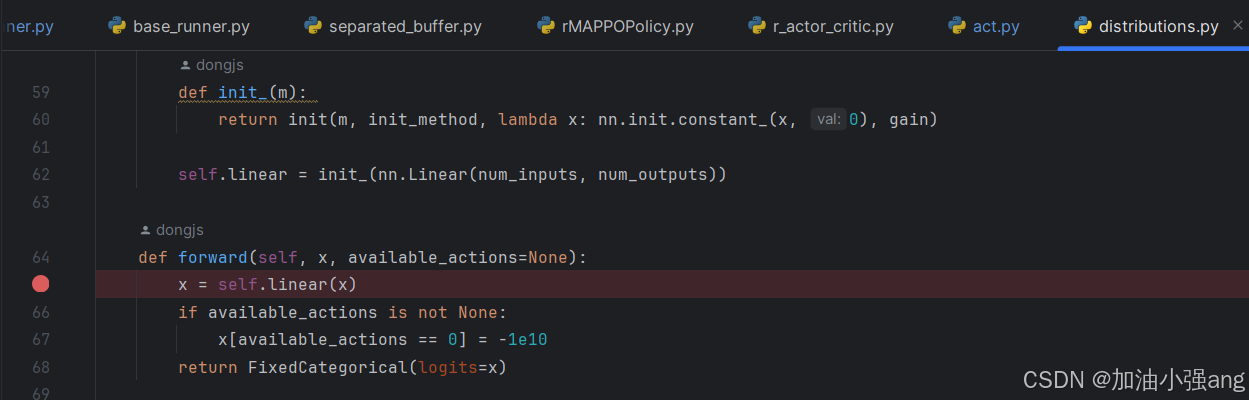
在哪里mask?用available_actions 做mask,值为0的动作被屏蔽掉。 怎么mask? available_actions = torch.tensor([[1, 1, 1, 0], # 第一个样本的最后一个动作不可用 [1, 0, 1, 1], # 第二个样本的第二个动作不可用 [1, 1, 1, 1]]) # 第三个样本的所有动作都可用
可以在runner中把available_actions传入。
4.numpy 和 tensor 的关系与转换。什么是张量。
这是一篇介绍张量的帖子:https://zhuanlan.zhihu.com/p/11468244818
在深度学习中,数据的组织则更进一步,从数据的组织,到模型内部的参数,都是通过一种叫做张量的数据结构进行表示和处理。
张量也可以像numpy一样直接索引调用,但是如果想获取张量的值,需要.item()
今日心得体会:调代码要心平气和。


















 918
918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









