



opencv箱底记录
opencv箱底记录
一.图像处理及图像基本操作
1.颜色通道提取及合并
2.边界填充
3.图像融合
4.
二.直方图与模板匹配
1.直方图
1.1直方图
1.2直方图均衡化
1.3自适应直方图均衡化
2.模板匹配
2.1模板匹配
2.2多个匹配
三.图像特征
1.特征识别
三级目录
实战内容
银行卡卡号识别
文件OCR
特征匹配
图像拼接
停车场车位识别
一.图像处理及图像基本操作
1.颜色通道提取及合并
提取函数(将图像分为三个通道,可通过索引获取对应通道的图像):cv2.split(img)
合并函数:cv2.merge((b,g,r))
获取矩阵/数组维数:.shape()
2.边界填充
当图片四周边界有空白(或者扩充边界),可以用边界填充方式进行填充。
- BORDER_REPLICATE:复制法,也就是复制最边缘像素。
- BORDER_REFLECT:反射法,对感兴趣的图像中的像素在两边进行复制例如:fedcba|abcdefgh|hgfedcb
- BORDER_REFLECT_101:反射法,也就是以最边缘像素为轴,对称,gfedcb|abcdefgh|gfedcba
- BORDER_WRAP:外包装法cdefgh|abcdefgh|abcdefg
- BORDER_CONSTANT:常量法,常数值填充,value=0,设定填充的像素值。
传入原图,定义好整个图像的大小(四个大小),选定填充方法。
replicate = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, borderType=cv2.BORDER_REPLICATE)
如图,图一为原图,其余是不同填充方式得到的结果。
居中的图片: 
3.图像融合
进行图像融合时一定要将两张图片大小调整一致。
通过.shape()函数获其中一个图像的大小,另一张图像用resize函数调整大小,addWeighted()函数进行图像融合。
关键代码:
img_cat.shape
img_dog = cv2.resize(img_dog, (500, 414))
res = cv2.addWeighted(img_cat, 0.4, img_dog, 0.6, 0)
效果展示:


融合结果:

4.形态学操作
基础:膨胀、腐蚀操作。
开运算:腐蚀后膨胀;闭运算:膨胀后腐蚀。
当图片中有细小毛躁,可用腐蚀操作去掉,此时图片会有损毁,再用膨胀操作尽力恢复。
礼帽:原始输入-开运算;黑帽:闭运算-原始输入。
梯度:膨胀-腐蚀。Sobel算子、scharr算子。
Scharr算子对差异更敏感,噪音点更容易被保留。
原图:

开运算:
#创建一个五行五列无符号整数类型的数组,kernel的大小形状决定腐蚀或膨胀操作的强度
kernel=np.ones((5,5),np.uint8)
#kernel的大小形状决定腐蚀或膨胀操作的强度
opening=cv2.morphologyEx(img,cv2.MORPH_OPEN,kernel)

闭运算:
kernel=np.ones((5,5),np.uint8)
closing=cv2.morphologyEx(img,cv2.MORPH_CLOSE,kernel)

礼帽:
tophat=cv2.morphologyEx(img,cv2.MORPH_TOPHAT,kernel)
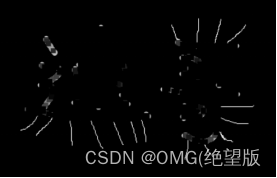
黑帽:
blackhat=cv2.morphologyEx(img,cv2.MORPH_BLACKHAT,kernel)

梯度:膨胀操作-腐蚀操作,梯度
kernel = np.ones((7,7),np.uint8)
gradient = cv2.morphologyEx(pie, cv2.MORPH_GRADIENT, kernel)


Sobel算子:经过绝对值操作,否则两边只能保存一边(正数部分),负数部分会被截断。
sobelx = cv2.Sobel(img,cv2.CV_64F,1,0,ksize=3)
sobelx = cv2.convertScaleAbs(sobelx)

Sobel算子和scharr算子对比:
#图像梯度-sobel算子
#计算图像的梯度(相当于检测边缘)
#分为x,y方向轴,最后整合
#给出的都是关键代码(省略读取、显示)
# ...,图像深度,1,0代表对水平方向进行处理,sobel算子大小
#x
sobelx=cv2.Sobel(img,cv2.CV_64F,1,0,ksize=3)
#y
sobely=cv2.Sobel(img,cv2.CV_64F,0,1,ksize=3)
##上面两个结果为什么会显示一半?因为在进行运算的时候,
##关于水平方向右边是黑减白,得到的值是负数;关于竖直方向下边也是黑减白,得负数。
##负数都会被截断成0,,为了解决这个问题,我们要取绝对值
##ps:1.中间部分逐渐趋向黑色就是趋近于0;2.不建议直接将水平+竖直两个方向一块计算,会更模糊
#x水平方向为例
sobelx = cv2.Sobel(img,cv2.CV_64F,1,0,ksize=3)
sobelx = cv2.convertScaleAbs(sobelx)
##求和(将水平、竖直两个方向相加)
sobelxy=cv2.addWeighted(sobelx,0.5,sobely,0.5,0)
cv_show(sobelxy,'sobelsy')
##图像梯度--scharr算子(结果差异更明,对差异更敏感)
##图像梯度--laplacian算子(二阶导:体现一阶导的变换,更敏感,对噪音点敏感,
##!但噪音点不一定是边界)
#三种方法对比
#sobel算子
img=cv2.imread('lena.jpg',cv2.IMREAD_GRAYSCALE)
sobelx=cv2.Sobel(img,cv2.CV_64F,1,0,ksize=3)
sobely=cv2.Sobel(img,cv2.CV_64F,0,1,ksize=3)
sobelx=cv2.convertScaleAbs(sobelx)
sobely=cv2.convertScaleAbs(sobely)
sobelxy=cv2.addWeighted(sobelx,0.5,sobely,0.5,0)
#scharr算子
scharrx=cv2.Scharr(img,cv2.CV_64F,1,0)
scharry=cv2.Scharr(img,cv2.CV_64F,0,1)
scharrx=cv2.convertScaleAbs(scharrx)
scharry=cv2.convertScaleAbs(scharry)
scharrxy=cv2.addWeighted(scharrx,0.5,scharry,0.5,0)
##laplacian
laplacian=cv2.Laplacian(img,cv2.CV_64F)
laplacian=cv2.convertScaleAbs(laplacian)
res=np.hstack((sobelxy,scharrxy,laplacian))
cv_show(res,'res')

5.图像平滑
为解决噪音点问题。
原图:

常用滤波:均值滤波、方框滤波、高斯滤波、中值滤波。
均值滤波:顾名思义就是取像素点求和取平均值。
blur=cv2.blur(img,(3,3))

方框滤波:当参数normallize为TRUE时,结果和均值一样;为False时,超过255的部分当作255处理,显示白色。
box = cv2.boxFilter(img,-1,(3,3), normalize=True)

高斯滤波:高斯模糊的卷积核里的数值满足高斯分布,相当于更重视中间的(矩阵)xy方向标准差都是1。
aussian=cv2.GaussianBlur(img,(5,5),1)

中值滤波:相当于用中值代替(更加平滑了甚至有点模糊)。
median=cv2.medianBlur(img,5)

6.图像阈值
给图像找一个上下边界,边界内称为阈值,根据type对图像处理。
ret, dst = cv2.threshold(src, thresh, maxval, type)
-
src: 输入图,只能输入单通道图像,通常来说为灰度图
-
dst: 输出图
-
thresh: 阈值
-
maxval: 当像素值超过了阈值(或者小于阈值,根据type来决定),所赋予的值
-
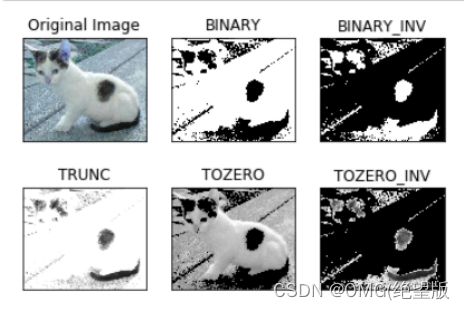
type:二值化操作的类型,包含以下5种类型: cv2.THRESH_BINARY; cv2.THRESH_BINARY_INV; cv2.THRESH_TRUNC; cv2.THRESH_TOZERO;cv2.THRESH_TOZERO_INV
-
cv2.THRESH_BINARY 超过阈值部分取maxval(最大值),否则取0
-
cv2.THRESH_BINARY_INV THRESH_BINARY的反转
-
cv2.THRESH_TRUNC 大于阈值部分设为阈值,否则不变
-
cv2.THRESH_TOZERO 大于阈值部分不改变,否则设为0
-
cv2.THRESH_TOZERO_INV THRESH_TOZERO的反转
结果:
7.图像轮廓
需要先处理为灰度图。
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
ret,thresh=cv2.threshold(gray,127,255,cv2.THRESH_BINARY)
#获取所有轮廓
contours, hierarchy = cv2.findContours(thresh,cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
#通过索引获取其中某个轮廓
contours[0]
#轮廓绘制:
#函数中的参数:传入绘制图像,轮廓,轮廓索引#retr_tree(-1代表所有),颜色模式(三个通道),#线条厚度
res=cv2.drawContours(draw_img,contours,-1,(0,0,255),2)
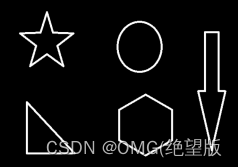
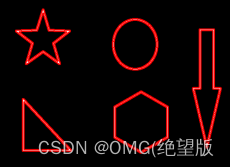
计算轮廓面积、周长
cv2.contourArea(cnt)
cv2.arcLength(cnt,True)
#绘制边界矩形
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
ret,thresh=cv2.threshold(gray,127,255,cv2.THRESH_BINARY)
contours,hierarchy=cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
cnt=contours[0]
x,y,w,h=cv2.boundingRect(cnt)
img=cv2.rectangle(img,(x,y),(x+w,y+h),(0,255,0),2)
以边界矩形为例,结果如图:
8.图像金字塔
高斯金字塔
向下采样,缩小;向上采样,放大。
两个操作先后执行仍然会有精度的缺失。
原图:

向上采样:
up=cv2.pyrUp(img)

向下采样:
down=cv2.pyrDown(img)

拉普拉斯金字塔
为实现高斯金字塔图像重建,将高斯金字塔与其上一层通过采样扩大后的差值图像。
down=cv2.pyrDown(img)
down_up=cv2.pyrUp(down)
l_1=img-down_up

二.直方图与模板匹配
1.直方图
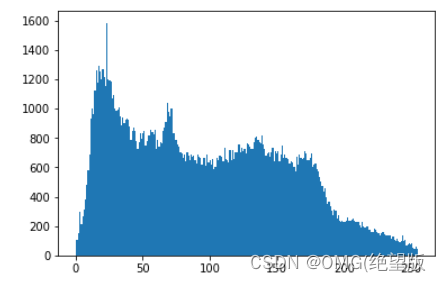
统计不同像素值在一幅图像中的个数,并以直方图的方式显示。
hist = cv2.calcHist([img],[0],None,[256],[0,256])
要处理的图像(需要先灰度处理):

统计所得直方图:
cv2.calcHist(images,channels,mask,histSize,ranges)
- images: 原图像图像格式为 uint8 或 float32。当传入函数时应 用中括号 [] 括来例如[img]
- channels: 同样用中括号括来它会告函数我们统幅图 像的直方图。如果入图像是灰度图它的值就是 [0]如果是彩色图像 的传入的参数可以是 [0][1][2] 它们分别对应着 BGR。
- mask: 掩模图像。统整幅图像的直方图就把它为 None。但是如 果你想统图像某一分的直方图的你就制作一个掩模图像并 使用它。
- histSize:BIN 的数目。也应用中括号括来
- ranges: 像素值范围常为 [0256]
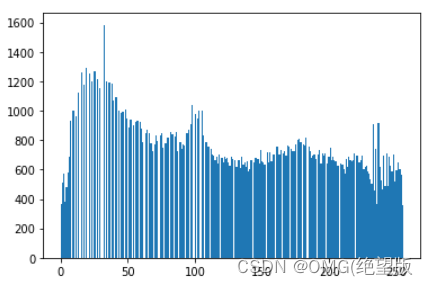
1.1直方图均衡化
可以增强局部的对比度,但不影响整体的对比度。
equ = cv2.equalizeHist(img)
1.2自适应直方图均衡化
第一个参数控制对比度,第二个参数确定被分割的区域,若图像被分割的区域越多,图像就越平滑。Apply方法将图像的对比度进行拉伸。
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8,8))
res_clahe = clahe.apply(img)
结果图:

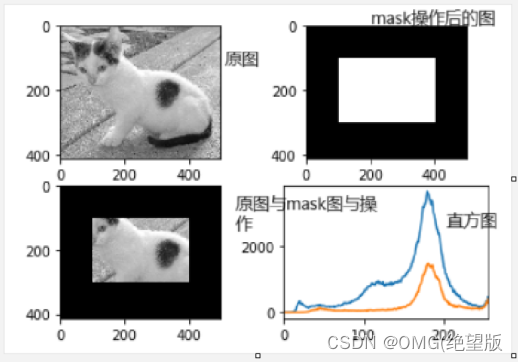
1.3Mask操作
填充选中区域(mask),可以过滤掉不需要的部分(与操作)。
创建mask
#mask填充的图
mask = np.zeros(img.shape[:2], np.uint8)
#与mask图与操作后的图
masked_img = cv2.bitwise_and(img, img, mask=mask)#与操作
2.模板匹配
模板匹配和卷积原理很像,模板在原图像上从原点开始滑动,计算模板与(图像被模板覆盖的地方)的差别程度。
#第二个参数0,表示取为灰度图像
img=cv2.imread('lena.jpg',0)
#五种模板匹配的方法:
#- TM_SQDIFF:计算平方不同,计算出来的值越小,越相关
#- TM_CCORR:计算相关性,计算出来的值越大,越相关
#- TM_CCOEFF:计算相关系数,计算出来的值越大,越相关
#- TM_SQDIFF_NORMED:计算归一化平方不同,计算出来的值越接近0,越相关
#- TM_CCORR_NORMED:计算归一化相关性,计算出来的值越接近1,越相关
#- TM_CCOEFF_NORMED:计算归一化相关系数,计算出来的值越接近1,越相关
#在函数matchTemplate第三个参数中填入所选的参数方法:
res = cv2.matchTemplate(img, template, cv2.TM_SQDIFF)
#通过函数minMaxLoc()获取矩阵中的最大最小值以及它们的位置,后续可以利用得到的位置绘制所匹配到的位置的矩形框。
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
给出两个方法的结果。

匹配多个对象:
res = cv2.matchTemplate(img_gray, template, cv2.TM_CCOEFF_NORMED)
threshold = 0.8
# 取匹配程度大于%80的坐标
loc = np.where(res >= threshold)
for pt in zip(*loc[::-1]): # *号表示可选参数
bottom_right = (pt[0] + w, pt[1] + h)
cv2.rectangle(img_rgb, pt, bottom_right, (0, 0, 255), 2)
结果:要匹配的图像是金币。

三.图像特征
# 实例化,绘制关键点
sift = cv2.xfeatures2d.SIFT_create()
kp = sift.detect(gray, None)
img=cv2.drawKeypoints(gray,kp,img)

四.实战部分
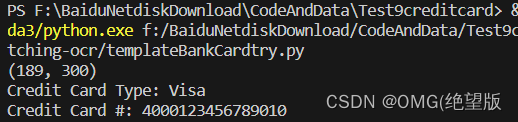
1.银行卡卡号识别
1.读取模板图像
2.将模板图像中的对应数字图像分割对应上表示的数字,通过数据结构元组表示
2.1(2具体)灰度处理–二值图像(边缘明显)(一般情况下,做轮廓检测输入的都是二值图像)–计算轮廓
3.读取银行卡图像
4.将亮的部分处理得更亮,而后得到一组一组(一个长方形条)的四位银行卡号
4.1预处理–灰度处理–礼帽操作–梯度–绝对值+归一化(归一化使图像像素值在一个可控的范围,方便二值操作)
4.2闭运算(先膨胀载腐蚀,将数字连接在一起)–闭运算(填补空缺)–计算轮廓
5.循环处理每一组长方形,将长方形中的四位数字分割开,与模板图像元组对应进行对比,得到相对应的数字
需要识别的银行卡:

结果:
代码:轮廓提取,裁剪每一位卡号,匹配:
# 符合区域大小的留下来
for(i,c) in enumerate(cnts):
(x,y,w,h)=cv2.boundingRect(c)
ar=w/float(h)
if ar>2.5 and ar<4.0:
if(w>40 and w<55) and (h>10 and h<20):
locs.append((x,y,w,h))
locs=sorted(locs,key=lambda x:x[0])
output=[]
for(i,(gX,gY,gW,gH)) in enumerate(locs):
groupOutput=[]
# 随便取,往外扩一点区域
group = gray[gY - 5:gY + gH + 5, gX - 5:gX + gW + 5]
cv_show('group',group)
group = cv2.threshold(group, 0, 255,
cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
cv_show('group',group)
digitCnts,hierarchy = cv2.findContours(group.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
digitCnts = contours.sort_contours(digitCnts,method="left-to-right")[0]
for c in digitCnts:
# 计算点集或轮廓形成的最小外接矩形
(x,y,w,h)=cv2.boundingRect(c)
roi=group[y:y+h,x:x+w]
roi=cv2.resize(roi,(57,88))
cv_show('roi',roi)
scores=[]
# 计算得分,找到数字,匹配
for (digit,digitROI) in digits.items():
result=cv2.matchTemplate(roi,digitROI,cv2.TM_CCOEFF)
(_,score,_,_)=cv2.minMaxLoc(result)
scores.append(score)
groupOutput.append(str(np.argmax(scores)))
cv2.rectangle(image, (gX - 5, gY - 5),
(gX + gW + 5, gY + gH + 5), (0, 0, 255), 1)
cv2.putText(image, "".join(groupOutput), (gX, gY - 15),
cv2.FONT_HERSHEY_SIMPLEX, 0.65, (0, 0, 255), 2)
output.extend(groupOutput)
2.文件OCR
预处理–遍历轮廓–透视变换–二值处理–利用OCR进行文字识别。
难点:
透视变换。
#透视变换
def order_points(pts):
# 一共4个坐标点
rect = np.zeros((4, 2), dtype = "float32")
# 按顺序找到对应坐标0123分别是 左上,右上,右下,左下
# 计算左上,右下
s = pts.sum(axis = 1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
# 计算右上和左下
diff = np.diff(pts, axis = 1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rect
def four_point_transform(image, pts):
# 获取输入坐标点
rect = order_points(pts)
(tl, tr, br, bl) = rect
# 计算输入的w和h值
widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2))
maxWidth = max(int(widthA), int(widthB))
heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2))
heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2))
maxHeight = max(int(heightA), int(heightB))
# 变换后对应坐标位置
dst = np.array([
[0, 0],
[maxWidth - 1, 0],
[maxWidth - 1, maxHeight - 1],
[0, maxHeight - 1]], dtype = "float32")
# 计算变换矩阵
M = cv2.getPerspectiveTransform(rect, dst)
warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight))
# 返回变换后结果
return warped
要处理的图:

图像处理后:

得到的文本结果:
3.特征匹配
预处理–特征点检测–特征点匹配–显示匹配结果
需要匹配的图:


匹配结果:

kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
# crossCheck表示两个特征点要互相匹,例如A中的第i个特征点与B中的第j个特征点最近的,并且B中的第j个特征点到A中的第i个特征点也是
#NORM_L2: 归一化数组的(欧几里德距离),如果其他特征计算方法需要考虑不同的匹配计算方式
bf = cv2.BFMatcher(crossCheck=True)
matches = bf.match(des1, des2)
# 根据距离排序。key定义了排序的依据--distance
matches = sorted(matches, key=lambda x: x.distance)
# 前十个关键点
img3 = cv2.drawMatches(img1, kp1, img2, kp2, matches[:10], None,flags=2)
k对最佳匹配,一个点对应两个最近的点(匹配的点更多了):
bf = cv2.BFMatcher()
# 一个点对应两个最近的
matches = bf.knnMatch(des1, des2, k=2)
#保留距离小于0.75的
good = []
for m, n in matches:
if m.distance < 0.75 * n.distance:
good.append([m])
# good:保留全部关键点(倒数第二个参数决定保存的关键点个数)
img3 = cv2.drawMatchesKnn(img1,kp1,img2,kp2,good,None,flags=2)

4.图像拼接
需要拼接的图像:


结果:

关键代码,图像拼接:stitcher
class Stitcher:
#拼接函数
def stitch(self, images, ratio=0.75, reprojThresh=4.0,showMatches=False):
#获取输入图片
(imageB, imageA) = images
#检测A、B图片的SIFT关键特征点,并计算特征描述子
(kpsA, featuresA) = self.detectAndDescribe(imageA)
(kpsB, featuresB) = self.detectAndDescribe(imageB)
# 匹配两张图片的所有特征点,返回匹配结果
M = self.matchKeypoints(kpsA, kpsB, featuresA, featuresB, ratio, reprojThresh)
# 如果返回结果为空,没有匹配成功的特征点,退出算法
if M is None:
return None
# 否则,提取匹配结果
# H是3x3视角变换矩阵
#只需要知道可以通过一个M矩阵将A图片形状变换为B图片即可,目前不需要知道原理
(matches, H, status) = M
# 将图片A进行视角变换,result是变换后图片
result = cv2.warpPerspective(imageA, H, (imageA.shape[1] + imageB.shape[1], imageA.shape[0]))
self.cv_show('result', result)
# 将图片B传入result图片最左端,采用切片
result[0:imageB.shape[0], 0:imageB.shape[1]] = imageB
self.cv_show('result', result)
# 检测是否需要显示图片匹配
if showMatches:
# 生成匹配图片,特征点连线图
vis = self.drawMatches(imageA, imageB, kpsA, kpsB, matches, status)
# 返回结果
return (result, vis)
# 返回匹配结果
return result
# 建立SIFT生成器
descriptor = cv2.xfeatures2d.SIFT_create()
# 检测SIFT特征点,并计算描述子
(kps, features) = descriptor.detectAndCompute(image, None)
# 将结果转换成NumPy数组
kps = np.float32([kp.pt for kp in kps])
# 返回特征点集,及对应的描述特征
return (kps, features)
def matchKeypoints(self, kpsA, kpsB, featuresA, featuresB, ratio, reprojThresh):
# 建立暴力匹配器
matcher = cv2.BFMatcher()
# 使用KNN检测来自A、B图的SIFT特征匹配对,K=2
rawMatches = matcher.knnMatch(featuresA, featuresB, 2)
matches = []
for m in rawMatches:
# 当最近距离跟次近距离的比值小于ratio值时,保留此匹配对
if len(m) == 2 and m[0].distance < m[1].distance * ratio:
# 存储两个点在featuresA, featuresB中的索引值
matches.append((m[0].trainIdx, m[0].queryIdx))
# 当筛选后的匹配对大于4时,计算视角变换矩阵
if len(matches) > 4:
# 获取匹配对的点坐标
ptsA = np.float32([kpsA[i] for (_, i) in matches])
ptsB = np.float32([kpsB[i] for (i, _) in matches])
# 计算视角变换矩阵
(H, status) = cv2.findHomography(ptsA, ptsB, cv2.RANSAC, reprojThresh)
# 返回结果
return (matches, H, status)
# 如果匹配对小于4时,返回None
return None
def drawMatches(self, imageA, imageB, kpsA, kpsB, matches, status):
# 初始化可视化图片,将A、B图左右连接到一起
(hA, wA) = imageA.shape[:2]
(hB, wB) = imageB.shape[:2]
vis = np.zeros((max(hA, hB), wA + wB, 3), dtype="uint8")
vis[0:hA, 0:wA] = imageA
vis[0:hB, wA:] = imageB
# 联合遍历,画出匹配对
for ((trainIdx, queryIdx), s) in zip(matches, status):
# 当点对匹配成功时,画到可视化图上
if s == 1:
# 画出匹配对
ptA = (int(kpsA[queryIdx][0]), int(kpsA[queryIdx][1]))
ptB = (int(kpsB[trainIdx][0]) + wA, int(kpsB[trainIdx][1]))
cv2.line(vis, ptA, ptB, (0, 255, 0), 1)
# 返回可视化结果
return vis
5.停车场车位识别
大步骤:将图像预处理,选出目标区域–训练训练集,用该算法识别目标区域中的停车场空位。
–读取图像
–得到图像的二值(两种方法,一种canny边缘检测/一种阈值(二值)),也叫背景过滤
–灰度
–边缘(灰度图相对于二值图得到的图像边缘效果更好)
–剔除无用的区域:获取关键点(手动调整标记),将关键点相连(利用边缘点获取的方式吗),mask填充(对选定的图像进行遮挡),剔除像素值不为255的地方。
–获得停车位:霍夫变换,获得横线,调整横线,过滤不符合要求的线(如斜线)。注意特殊列(第一和最后),数字标列(字典表示),调整,将图片分割出来保存(利用xy的坐标及车位之间的距离估计)(难,有关数学)。
–训练集训练得到结果并应用:标记图中的空余车位及计算两种车位的总数。
原图:

车位标识:

class Parking:
def cv_show(self,name,img):
cv2.imshow(name, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
# △
def show_images(self, images, cmap=None):
cols = 2
rows = (len(images)+1)//cols
plt.figure(figsize=(15, 12))
for i, image in enumerate(images):
plt.subplot(rows, cols, i+1)
cmap = 'gray' if len(image.shape)==2 else cmap
plt.imshow(image, cmap=cmap)
plt.xticks([])
plt.yticks([])
plt.tight_layout(pad=0, h_pad=0, w_pad=0)
plt.show()
def select_rgb_white_yellow(self,image):
#过滤掉背景(只是过滤背景,并没有把无关的部分去掉,取边缘)
lower = np.uint8([120, 120, 120])
upper = np.uint8([255, 255, 255])
# lower_red和高于upper_red的部分分别变成0,lower_red~upper_red之间的值变成255,相当于过滤背景
white_mask = cv2.inRange(image, lower, upper)
self.cv_show('white_mask',white_mask)
masked = cv2.bitwise_and(image, image, mask = white_mask)
self.cv_show('masked',masked)
return masked
def convert_gray_scale(self,image):
return cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
def detect_edges(self,image, low_threshold=50, high_threshold=200):
return cv2.Canny(image, low_threshold, high_threshold)
# 剔除操作,只保存像素值为255的地方
def filter_region(self,image, vertices):
"""
剔除掉不需要的地方
"""
mask = np.zeros_like(image)
if len(mask.shape)==2:
cv2.fillPoly(mask, vertices, 255)
self.cv_show('mask', mask)
return cv2.bitwise_and(image, mask)
def select_region(self,image):
"""
手动选择区域
"""
# first, define the polygon by vertices
rows, cols = image.shape[:2]
pt_1 = [cols*0.05, rows*0.90]
pt_2 = [cols*0.05, rows*0.70]
pt_3 = [cols*0.30, rows*0.55]
pt_4 = [cols*0.6, rows*0.15]
pt_5 = [cols*0.90, rows*0.15]
pt_6 = [cols*0.90, rows*0.90]
vertices = np.array([[pt_1, pt_2, pt_3, pt_4, pt_5, pt_6]], dtype=np.int32)
point_img = image.copy()
point_img = cv2.cvtColor(point_img, cv2.COLOR_GRAY2RGB)
for point in vertices[0]:
cv2.circle(point_img, (point[0],point[1]), 10, (0,0,255), 4)
self.cv_show('point_img',point_img)
return self.filter_region(image, vertices)
def hough_lines(self,image):
#输入的图像需要是边缘检测后的结果
#minLineLengh(线的最短长度,比这个短的都被忽略)和MaxLineCap(两条直线之间的最大间隔,小于此值,认为是一条直线)
#rho距离精度,theta角度精度,threshod超过设定阈值才被检测出线段
return cv2.HoughLinesP(image, rho=0.1, theta=np.pi/10, threshold=15, minLineLength=9, maxLineGap=4)
def draw_lines(self,image, lines, color=[255, 0, 0], thickness=2, make_copy=True):
# 过滤霍夫变换检测到直线(通过线与线之间xy坐标的差值,过滤斜线等不符合要求的线)
if make_copy:
image = np.copy(image)
cleaned = []
for line in lines:
for x1,y1,x2,y2 in line:
if abs(y2-y1) <=1 and abs(x2-x1) >=25 and abs(x2-x1) <= 55:
cleaned.append((x1,y1,x2,y2))
cv2.line(image, (x1, y1), (x2, y2), color, thickness)
print(" No lines detected: ", len(cleaned))
return image
def identify_blocks(self,image, lines, make_copy=True):
if make_copy:
new_image = np.copy(image)
#Step 1: 过滤部分直线
cleaned = []
for line in lines:
for x1,y1,x2,y2 in line:
if abs(y2-y1) <=1 and abs(x2-x1) >=25 and abs(x2-x1) <= 55:
cleaned.append((x1,y1,x2,y2))
#Step 2: 对直线按照x1进行排序
import operator
list1 = sorted(cleaned, key=operator.itemgetter(0, 1))
#Step 3: 找到多个列,相当于每列是一排车
# cluster簇,代表一排车,作用为给车位标号
clusters = {}
dIndex = 0
clus_dist = 10
# 距离较近,为一簇,距离较远则不是一簇
for i in range(len(list1) - 1):
distance = abs(list1[i+1][0] - list1[i][0])
if distance <= clus_dist:
if not dIndex in clusters.keys(): clusters[dIndex] = []
clusters[dIndex].append(list1[i])
clusters[dIndex].append(list1[i + 1])
else:
dIndex += 1
#Step 4: 得到坐标
rects = {}
i = 0
for key in clusters:
all_list = clusters[key]
cleaned = list(set(all_list))
if len(cleaned) > 5:
cleaned = sorted(cleaned, key=lambda tup: tup[1])
avg_y1 = cleaned[0][1]
avg_y2 = cleaned[-1][1]
avg_x1 = 0
avg_x2 = 0
for tup in cleaned:
avg_x1 += tup[0]
avg_x2 += tup[2]
avg_x1 = avg_x1/len(cleaned)
avg_x2 = avg_x2/len(cleaned)
rects[i] = (avg_x1, avg_y1, avg_x2, avg_y2)
i += 1
print("Num Parking Lanes: ", len(rects))
#Step 5: 把列矩形画出来
buff = 7
for key in rects:
tup_topLeft = (int(rects[key][0] - buff), int(rects[key][1]))
tup_botRight = (int(rects[key][2] + buff), int(rects[key][3]))
cv2.rectangle(new_image, tup_topLeft,tup_botRight,(0,255,0),3)
return new_image, rects
def draw_parking(self,image, rects, make_copy = True, color=[255, 0, 0], thickness=2, save = True):
if make_copy:
new_image = np.copy(image)
gap = 15.5
spot_dict = {} # 字典:一个车位对应一个位置
tot_spots = 0
#微调
adj_y1 = {0: 20, 1:-10, 2:0, 3:-11, 4:28, 5:5, 6:-15, 7:-15, 8:-10, 9:-30, 10:9, 11:-32}
adj_y2 = {0: 30, 1: 50, 2:15, 3:10, 4:-15, 5:15, 6:15, 7:-20, 8:15, 9:15, 10:0, 11:30}
adj_x1 = {0: -8, 1:-15, 2:-15, 3:-15, 4:-15, 5:-15, 6:-15, 7:-15, 8:-10, 9:-10, 10:-10, 11:0}
adj_x2 = {0: 0, 1: 15, 2:15, 3:15, 4:15, 5:15, 6:15, 7:15, 8:10, 9:10, 10:10, 11:0}
for key in rects:
tup = rects[key]
x1 = int(tup[0]+ adj_x1[key])
x2 = int(tup[2]+ adj_x2[key])
y1 = int(tup[1] + adj_y1[key])
y2 = int(tup[3] + adj_y2[key])
cv2.rectangle(new_image, (x1, y1),(x2,y2),(0,255,0),2)
num_splits = int(abs(y2-y1)//gap)
for i in range(0, num_splits+1):
y = int(y1 + i*gap)
cv2.line(new_image, (x1, y), (x2, y), color, thickness)
if key > 0 and key < len(rects) -1 :
#竖直线
x = int((x1 + x2)/2)
cv2.line(new_image, (x, y1), (x, y2), color, thickness)
# 计算数量
if key == 0 or key == (len(rects) -1):
tot_spots += num_splits +1
else:
tot_spots += 2*(num_splits +1)
# 字典对应好
if key == 0 or key == (len(rects) -1):
for i in range(0, num_splits+1):
cur_len = len(spot_dict)
y = int(y1 + i*gap)
spot_dict[(x1, y, x2, y+gap)] = cur_len +1
else:
for i in range(0, num_splits+1):
cur_len = len(spot_dict)
y = int(y1 + i*gap)
x = int((x1 + x2)/2)
spot_dict[(x1, y, x, y+gap)] = cur_len +1
spot_dict[(x, y, x2, y+gap)] = cur_len +2
print("total parking spaces: ", tot_spots, cur_len)
if save:
filename = 'with_parking.jpg'
cv2.imwrite(filename, new_image)
return new_image, spot_dict
def assign_spots_map(self,image, spot_dict, make_copy = True, color=[255, 0, 0], thickness=2):
if make_copy:
new_image = np.copy(image)
for spot in spot_dict.keys():
(x1, y1, x2, y2) = spot
cv2.rectangle(new_image, (int(x1),int(y1)), (int(x2),int(y2)), color, thickness)
return new_image
def save_images_for_cnn(self,image, spot_dict, folder_name ='cnn_data'):
for spot in spot_dict.keys():
(x1, y1, x2, y2) = spot
(x1, y1, x2, y2) = (int(x1), int(y1), int(x2), int(y2))
#裁剪
spot_img = image[y1:y2, x1:x2]
spot_img = cv2.resize(spot_img, (0,0), fx=2.0, fy=2.0)
spot_id = spot_dict[spot]
filename = 'spot' + str(spot_id) +'.jpg'
print(spot_img.shape, filename, (x1,x2,y1,y2))
cv2.imwrite(os.path.join(folder_name, filename), spot_img)
def make_prediction(self,image,model,class_dictionary):
#预处理
img = image/255.
#转换成4D tensor
image = np.expand_dims(img, axis=0)
# 用训练好的模型进行训练
class_predicted = model.predict(image)
inID = np.argmax(class_predicted[0])
label = class_dictionary[inID]
return label
def predict_on_image(self,image, spot_dict , model,class_dictionary,make_copy=True, color = [0, 255, 0], alpha=0.5):
if make_copy:
new_image = np.copy(image)
overlay = np.copy(image)
self.cv_show('new_image',new_image)
cnt_empty = 0
all_spots = 0
for spot in spot_dict.keys():
all_spots += 1
(x1, y1, x2, y2) = spot
(x1, y1, x2, y2) = (int(x1), int(y1), int(x2), int(y2))
spot_img = image[y1:y2, x1:x2]
spot_img = cv2.resize(spot_img, (48, 48))
label = self.make_prediction(spot_img,model,class_dictionary)
if label == 'empty':
cv2.rectangle(overlay, (int(x1),int(y1)), (int(x2),int(y2)), color, -1)
cnt_empty += 1
cv2.addWeighted(overlay, alpha, new_image, 1 - alpha, 0, new_image)
cv2.putText(new_image, "Available: %d spots" %cnt_empty, (30, 95),
cv2.FONT_HERSHEY_SIMPLEX,
0.7, (255, 255, 255), 2)
cv2.putText(new_image, "Total: %d spots" %all_spots, (30, 125),
cv2.FONT_HERSHEY_SIMPLEX,
0.7, (255, 255, 255), 2)
save = False
if save:
filename = 'with_marking.jpg'
cv2.imwrite(filename, new_image)
self.cv_show('new_image',new_image)
return new_image
def predict_on_video(self,video_name,final_spot_dict, model,class_dictionary,ret=True):
cap = cv2.VideoCapture(video_name)
count = 0
while ret:
ret, image = cap.read()
count += 1
if count == 5:
count = 0
new_image = np.copy(image)
overlay = np.copy(image)
cnt_empty = 0
all_spots = 0
color = [0, 255, 0]
alpha=0.5
for spot in final_spot_dict.keys():
all_spots += 1
(x1, y1, x2, y2) = spot
(x1, y1, x2, y2) = (int(x1), int(y1), int(x2), int(y2))
spot_img = image[y1:y2, x1:x2]
spot_img = cv2.resize(spot_img, (48,48))
label = self.make_prediction(spot_img,model,class_dictionary)
if label == 'empty':
cv2.rectangle(overlay, (int(x1),int(y1)), (int(x2),int(y2)), color, -1)
cnt_empty += 1
cv2.addWeighted(overlay, alpha, new_image, 1 - alpha, 0, new_image)
cv2.putText(new_image, "Available: %d spots" %cnt_empty, (30, 95),
cv2.FONT_HERSHEY_SIMPLEX,
0.7, (255, 255, 255), 2)
cv2.putText(new_image, "Total: %d spots" %all_spots, (30, 125),
cv2.FONT_HERSHEY_SIMPLEX,
0.7, (255, 255, 255), 2)
cv2.imshow('frame', new_image)
if cv2.waitKey(10) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
cap.release()
三.报错记录+知识点
1.Jupyter编辑器代码单元格处为In[*],代表当前单元格失效,代码无法执行。解决:查看右上角Python3状态栏右侧图标,实心圆代表连接忙,线性圆代表正常连接。重启kernel内核/将虚拟环境pyenv安装好。
2.查找(修改)jupyter所在的文件夹:
第一:打开Anaconda Prompt,输入指令jupyter notebook --generate-config
保存生成的文件路径,找到配置文件。
第二:找到.py为后缀的文件,用记事本格式打开。
第三:用ctrl+f查找c.NotebookApp.notebook_dir,在单引号后写入新路径。(需要全英文)
第四:右击jupyter图标-属性-目标,将尾部字符串“%…(省略)”删除-应用-确认。
最后检查:进入jupyter,输入以下代码,可得到所在文件夹。
import os
print(os.path.abspath(‘.’))
3.error: (-215:Assertion failed) size.width>0 && size.height>0 in fun
imshow(‘a’,b)中b的路径不对。可能是此处文件名不对,也可能是上一步imread中的路径不对(必须要用英文斜杠 / ,一个斜杠不行用两个)。
4.知识点:
什么是API?
Application Programming Interface程序之间的接口–程序之间的合约。
5.在Python的matplotlib库中,plt.subplot()函数用于添加子图到当前图形中。函数中的参数231表示一个三位数,每一位数都代表了不同的含义。百位数(2)表示子图的行数,十位数(3)表示子图的列数,个位数(1)表示当前正在创建或激活的子图的索引。因此,plt.subplot(231)意味着在一个2行3列的子图网格中,激活或创建第1个子图。
6.腐蚀操作+膨胀操作:当图片中有细小毛躁,可用腐蚀操作去掉,此时图片会有损毁,再用膨胀操作尽力恢复。
7.not enough values to unpack (expected 3, got 2):
计算轮廓的函数已经有更新,现在只能返回两个结果:
digitCnts,hierarchy = cv2.findContours(group.copy(), cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)
8.在边缘检测之前执行滤波操作主要有以下几个原因:
降噪:边缘检测往往会受到图像中噪声的干扰,通过滤波可以降低图像中的噪声,提高边缘检测的准确性。
平滑图像:滤波操作可以使图像变得更为平滑,这样在进行边缘检测时,不会受到图像本身纹理和细节的影响,提高边缘检测的精度。
改进检测性能:滤波操作可以抑制边缘检测中可能出现的伪峰和毛刺现象,提高边缘检测的稳定性和性能。
滤波操作对于边缘检测来说是重要的前置处理步骤,它可以帮助我们更好地提取出图像中的边缘信息,提高边缘检测的精度和稳定性。
9.读取图像的路径中不要有中文
10.cnts=cv2.findContours(edged.copy(),cv2.RETR_LIST,cv2.CHAIN_APPROX_SIMPLE)[0]
该函数下标索引更新为0:[0]
11.vscode打开新窗口:左上角 Files -> open new window 然后在新的窗口里把工程再打开一次。
12.归一化的目的:为使结果更加均衡。

















 800
800

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









