







 本文介绍了概率模型在分类问题中的应用,通过盒子抽球问题阐述了贝叶斯公式计算后验概率的方法。讨论了先验概率和条件概率的概念,并详细解释了高斯分布和极大似然估计法在估计模型参数中的作用。文章还提到了朴素贝叶斯分类器和伯努利分布,并探讨了模型优化以及不同概率分布的选择对分类性能的影响。
本文介绍了概率模型在分类问题中的应用,通过盒子抽球问题阐述了贝叶斯公式计算后验概率的方法。讨论了先验概率和条件概率的概念,并详细解释了高斯分布和极大似然估计法在估计模型参数中的作用。文章还提到了朴素贝叶斯分类器和伯努利分布,并探讨了模型优化以及不同概率分布的选择对分类性能的影响。
文章目录
概率模型实现原理
盒子抽球后验概率问题
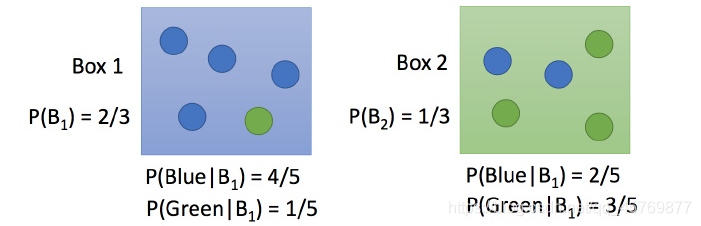
假设两个盒子,各装了5个球,
- 抽到盒子1中球的概率是 2 / 3 2/3 2/3,是盒子2中球的概率是 1 / 3 1/3 1/3。
- 在盒子1中随机抽一个球,是蓝色的概率为 4 / 5 4/5 4/5,绿的的概率为 1 / 5 1/5 1/5
- 在盒子2中随机抽一个球,是蓝色的概率为 2 / 5 2/5 2/5,绿的的概率为 3 / 5 3/5 3/5
问:随机从两个盒子中抽一个球,抽到蓝色球属于盒子1的概率是多少?
P ( B 1 ∣ B l u e ) = P ( B l u e ∣ B 1 ) P ( B 1 ) P ( B l u e ∣ B 1 ) P ( B 1 ) + P ( B l u e ∣ B 2 ) P ( B 2 ) ( 贝 叶 斯 公 式 ) = 4 5 ∗ 2 3 4 5 ∗ 2 3 + 2 5 ∗ 1 3 = 4 5 \begin{aligned} P(B_1|Blue) &= \frac{P(Blue|B_1)P(B_1)}{P(Blue|B_1)P(B_1)+P(Blue|B_2)P(B_2) } (贝叶斯公式)\\ & = \frac{\frac{4}{5}*\frac{2}{3}}{\frac{4}{5} * \frac{2}{3}+\frac{2}{5}*\frac{1}{3}} \\ & = \frac{4}{5} \end{aligned} P(B1∣Blue)=P(Blue∣B1)P(B1)+P(Blue∣B2)P(B2)P(Blue∣B1)P(B1)(贝叶斯公式)=54∗32+52∗3154∗32=54
概率与分类的关系
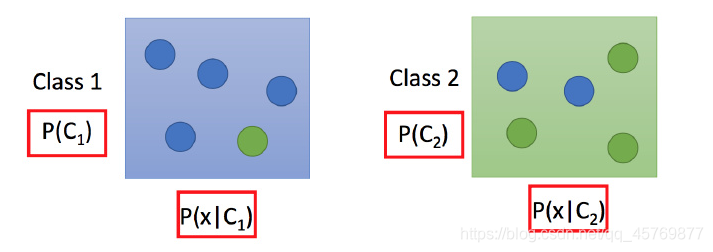
将上面得到盒子问题转变成二元分类问题(输入一个attribute vector,输出其为class 1和class 2的概率)
将两个盒子类比为两个class,那么问题转变为随机从数据集中抽取一个数据,抽到的某个数据,它属于class1的概率是多
少?
公式:
P ( C 1 ∣ x ) = P ( C 1 ) P ( x ∣ C 1 ) P ( C 1 ) P ( x ∣ C 1 ) + P ( C 2 ) P ( x ∣ C 2 ) P(C_1|x)=\frac{P(C_1)P(x|C_1)}{P(C_1)P(x|C_1)+P(C_2)P(x|C_2)} P(C1∣x)=P(C1)P(x∣C1)+P(C2)P(x∣C2)P(C1)P(x∣C1)
从Training data中估测出四个值: P ( C 1 ) , P ( x ∣ C 1 ) , P ( C 2 ) , P ( x ∣ C 2 ) P(C_1),P(x|C_1),P(C_2),P(x|C_2) P(C1),P(x∣C1),P(C2),P(x∣C2),即可利用贝叶斯公式得出数据x属于C1的概率。
先验概率
对于某一数据集,class1和class2各自的数量是一定的,即 P ( C 1 ) P(C1) P(C1)和 P ( C 2 ) P(C2) P(C2)作为prior probability已知。
假如训练数据集中共有140条数据,其中有class1数据79个,class2数据61个,那么
- P ( C 1 ) = 79 / ( 79 + 61 ) = 0.56 P(C_1)=79/(79+61)=0.56 P(C1)=79/(79+61)=0.56
- P ( C 2 ) = 61 / ( 79 + 61 ) = 0.44 P(C_2)=61/(79+61)=0.44 P(C2)=61/(79+61)=0.44
条件概率
我们的训练数据通常采样而来,只能看做是总体的一个样本,对于分类问题,我们如何通过已有样本个体,估测总体中每个
个体出现的概率,即 P ( x ∣ C 1 ) 和 P ( x ∣ C 2 ) P(x|C_1)和P(x|C_2) P(x∣C1)和P(x∣C2),假设总体数据分布呈高斯分布,那么问题转化为如何通过已有样本数据找出总
体数据的高斯分布。换句话说就是,以高斯分布为Model,尽可能去拟合已有的样本数据分布。
高斯分布
以二元高斯分布为例
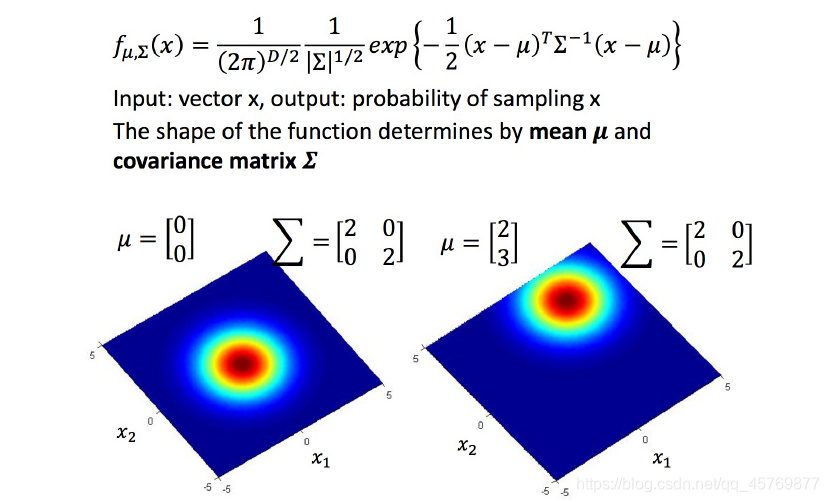
高斯分布由期望
μ
\mu
μ 和协方差矩阵
∑
\sum
∑ 决定。
μ
\mu
μ 决定概率分布的最高点的位置,
∑
\sum
∑决定概率分布在各个方向上的离散程度。
极大似然估计法
利用已有样本数据,以极大似然估计法估测Gaussian distribution的期望
μ
\mu
μ 和协方差矩阵
∑
\sum
∑
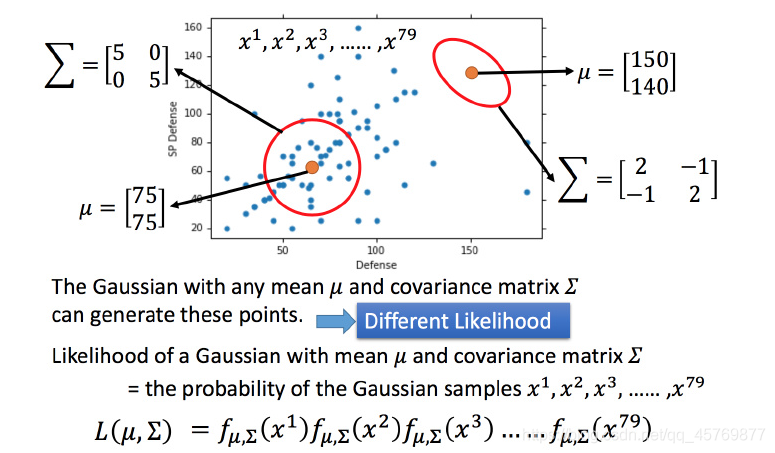
将高斯分布作为Model,期望 μ \mu μ 和协方差矩阵 ∑ \sum ∑作为参数,找出使所有样本点概率之积最大的一个funcation。
极大似然函数
L ( u , Σ ) = f u , Σ ( x 1 ) ⋅ f u , Σ ( x 2 ) . . . f u , Σ ( x 79 ) L(u,\Sigma)=f_{u,\Sigma}(x^1)\cdot f_{u,\Sigma}(x^2)...f_{u,\Sigma}(x^{79}) L(u,Σ)=fu,Σ(x1)⋅fu,Σ(x2)...fu,Σ(x79)
通过微分得到的高斯函数的
u
u
u和
Σ
\Sigma
Σ的最优解公式如下:
u
∗
,
Σ
∗
=
arg
max
u
,
Σ
L
(
u
,
Σ
)
u
∗
=
1
79
∑
n
=
1
79
x
n
Σ
∗
=
1
79
∑
n
=
1
79
(
x
n
−
u
∗
)
(
x
n
−
u
∗
)
T
u^*,\Sigma^*=\arg \max\limits_{u,\Sigma} L(u,\Sigma) \\ u^*=\frac{1}{79}\sum\limits_{n=1}^{79}x^n \ \ \ \ \Sigma^*=\frac{1}{79}\sum\limits_{n=1}^{79}(x^n-u^*)(x^n-u^*)^T
u∗,Σ∗=argu,ΣmaxL(u,Σ)u∗=791n=1∑79xn Σ∗=791n=1∑79(xn−u∗)(xn−u∗)T
做分类 😄
对于两个属性的分类问题来说,利用先验概率和估计出的C1和C2高斯分布,代入贝叶斯公式,求出分类。
- x x x为分类个体,输入attribute(feature) vector
- 高斯分布期望
u
u
u和协方差矩阵
Σ
\Sigma
Σ的维度取决于特征量,假设n个属性,则
u
u
u = (n,1),
Σ
\Sigma
Σ = (n,n)

模型优化
协方差矩阵 Σ \Sigma Σ的规模和输入的feature size的平方成正比的,当feature的数量很大的时候, Σ \Sigma Σ增长非常快的,而对于每一种
class,赋予相应的Gaussian distribution以不同协方差矩阵 Σ \Sigma Σ,使得参数太多,可能导致overfitting。
不同的class共享同一个协方差矩阵
Σ
\Sigma
Σ
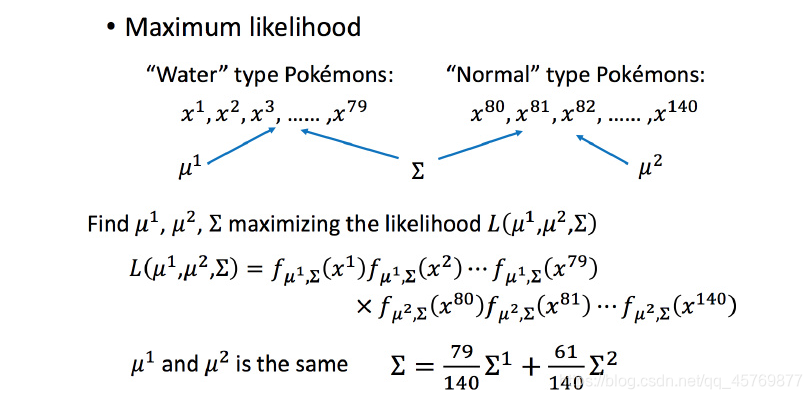
那使用极大似然估计
L
(
μ
1
,
μ
2
,
Σ
)
L(\mu_1,\mu_2,\Sigma)
L(μ1,μ2,Σ)时,虽然对于不同的class有不同的期望
μ
\mu
μ,但采用同一个协方差
Σ
\Sigma
Σ计算。
优化后的结果
优化后,分类平面变成直线,性能提升。
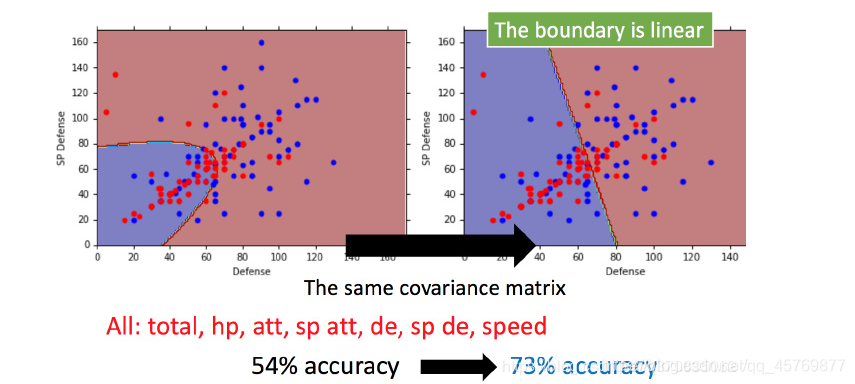
其他的概率分布
也可以选择其他的Probability distribution,简单的分布函数(参数少),bias大,variance小;复杂的分布函数,bias小,
variance大。
Naive Bayes Classifier(朴素贝叶斯分类法)
假设特征向量 x = [ x 1 x 2 x 3 . . . x k . . . ] x=[x_1 \ x_2 \ x_3 \ ... \ x_k \ ... \ ] x=[x1 x2 x3 ... xk ... ],每一个dimension x k x_k xk的分布相互独立的,它们之间的covariance都是0,这样就可
以把x产生的几率拆解成
x
1
,
x
2
,
.
.
.
,
x
k
x_1,x_2,...,x_k
x1,x2,...,xk产生的几率之积。它的covariance matrix变成是对角矩阵。

我们把上述这种方法叫做Naive Bayes Classifier(朴素贝叶斯分类法),前提是明确了所有的feature之间是相互独立的。
Bernoulli distribution(伯努利分布)
对于二元分类来说,采用 Bernoulli distribution(伯努利分布)。
后验概率分析
以sigmoid函数化简

最终化简形式:
P
w
,
b
(
C
1
∣
x
)
=
σ
(
z
)
=
1
1
+
e
−
z
z
=
w
⋅
x
+
b
=
∑
i
w
i
x
i
+
b
P_{w,b}(C_1|x)=\sigma(z)=\frac{1}{1+e^{-z}} \\ z=w\cdot x+b=\sum\limits_i w_ix_i+b \\
Pw,b(C1∣x)=σ(z)=1+e−z1z=w⋅x+b=i∑wixi+b
这就是为什么分类平面为线性的。同时,那在Generative model里面,学得
N
1
,
N
2
,
u
1
,
u
2
,
Σ
N_1,N_2,u_1,u_2,\Sigma
N1,N2,u1,u2,Σ,最终转化为vector
w
w
w和const
b
b
b,把它们代进
P
(
C
1
∣
x
)
=
σ
(
w
⋅
x
+
b
)
P(C_1|x)=\sigma(w\cdot x+b)
P(C1∣x)=σ(w⋅x+b)这个式子,计算概率。如果直接学习
w
w
w和
b
b
b是否更方便呢,这就是逻辑回归的内容了。

















 566
566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









