







在回归问题中,需要解决下面的最优化问题:
θ ∗ = arg min θ L ( θ ) \theta^∗= \underset{ \theta }{\operatorname{arg\ min}} L(\theta) θ∗=θarg minL(θ)
- L L L :lossfunction(损失函数)
- θ \theta θ :parameters(参数)
L指损失函数,评判预测模型的性能,比如均方误差MSE,平方误差SE
θ \theta θ 指代损失函数中的参数,比如线性回归中的 w w w 和 b b b 。
目的是要找一组参数 θ \theta θ ,让损失函数(在training data上的值)越小越好,这个问题可以用梯度下降法解决:
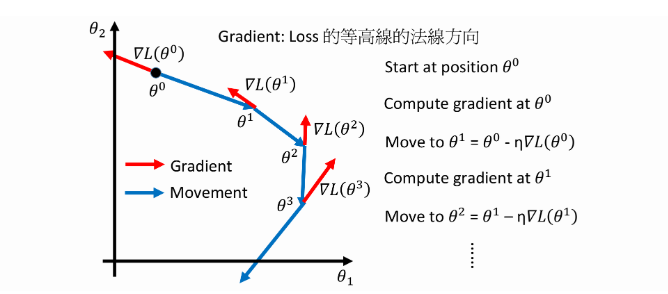
假设 θ \theta θ是参数的集合:Suppose that θ \theta θ has two variables { θ 1 , θ 2 } \left\{\theta_{1}, \theta_{2}\right\} {θ1,θ2}
随机选取一组起始的参数:Randomly start at θ 0 = [ θ 1 0 θ 2 0 ] \theta^{0}=\left[\begin{array}{l}{\theta_{1}^{0}} \\ {\theta_{2}^{0}}\end{array}\right] \quad θ0=[θ10θ20]
计算 θ \theta θ处的梯度gradient: ∇ L ( θ ) = [ ∂ L ( θ 1 ) / ∂ θ 1 ∂ L ( θ 2 ) / ∂ θ 2 ] \nabla L(\theta)=\left[\begin{array}{l}{\partial L\left(\theta_{1}\right) / \partial \theta_{1}} \\ {\partial L\left(\theta_{2}\right) / \partial \theta_{2}}\end{array}\right] ∇L(θ)=[∂L(θ1)/∂θ1∂L(θ2)/∂θ2]
[ θ 1 1 θ 2 1 ] = [ θ 1 0 θ 2 0 ] − η [ ∂ L ( θ 1 0 ) / ∂ θ 1 ∂ L ( θ 2 0 ) / ∂ θ 2 ] ⇒ θ 1 = θ 0 − η ∇ L ( θ 0 ) \left[\begin{array}{l}{\theta_{1}^{1}} \\ {\theta_{2}^{1}}\end{array}\right]=\left[\begin{array}{l}{\theta_{1}^{0}} \\ {\theta_{2}^{0}}\end{array}\right]-\eta\left[\begin{array}{l}{\partial L\left(\theta_{1}^{0}\right) / \partial \theta_{1}} \\ {\partial L\left(\theta_{2}^{0}\right) / \partial \theta_{2}}\end{array}\right] \Rightarrow \theta^{1}=\theta^{0}-\eta \nabla L\left(\theta^{0}\right) [θ11θ21]=[θ10θ20]−η[∂L(θ10)/∂θ1∂L(θ20)/∂θ2]⇒θ1=θ0−η∇L(θ0)
[ θ 1 2 θ 2 2 ] = [ θ 1 1 θ 2 1 ] − η [ ∂ L ( θ 1 1 ) / ∂ θ 1 ∂ L ( θ 2 1 ) / ∂ θ 2 ] ⇒ θ 2 = θ 1 − η ∇ L ( θ 1 ) \left[\begin{array}{c}{\theta_{1}^{2}} \\ {\theta_{2}^{2}}\end{array}\right]=\left[\begin{array}{c}{\theta_{1}^{1}} \\ {\theta_{2}^{1}}\end{array}\right]-\eta\left[\begin{array}{c}{\partial L\left(\theta_{1}^{1}\right) / \partial \theta_{1}} \\ {\partial L\left(\theta_{2}^{1}\right) / \partial \theta_{2}}\end{array}\right] \Rightarrow \theta^{2}=\theta^{1}-\eta \nabla L\left(\theta^{1}\right) [θ12θ22]=[θ11θ21]−η[∂L(θ11)/∂θ1∂L(θ21)/∂θ2]⇒θ2=θ1−η∇L(θ1)
梯度和学习率
参数
θ
\theta
θ的变化:
θ
n
+
1
=
θ
n
−
η
∇
L
(
θ
n
)
\theta^{n+1} = \theta^{n}-\eta \nabla L( \theta^{n})
θn+1=θn−η∇L(θn)由两个因素组成一个是学习率
η
\eta
η一个是梯度
∇
L
(
θ
n
)
\nabla L( \theta^{n})
∇L(θn);梯度主要决定梯度下降的方向,学习率决定在下降方向上走多长的路。
梯度
学习率
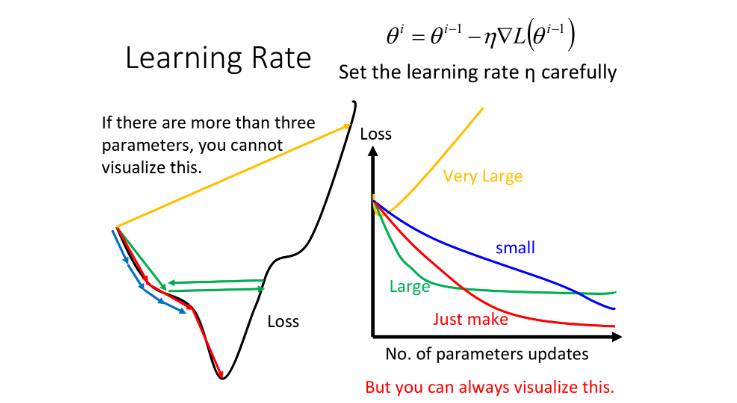
若学习率适合,会比较顺利地到达到损失函数的局部最小值,若学习率太小;虽然最后能够走到局部最小的地方,但是它可能会走得非常慢;若学习率太大,可能会在“山谷”的上振荡;若学习率非常大,使得loss穿过“山谷”到达太远的地方。
数学依据
泰勒表达式
h ( x ) = ∑ k = 0 ∞ h ( k ) ( x 0 ) k ! ( x − x 0 ) k = h ( x 0 ) + h ′ ( x 0 ) ( x − x 0 ) + h ′ ′ ( x 0 ) 2 ! ( x − x 0 ) 2 + . . . h(x)=\sum\limits_{k=0}^\infty \frac{h^{(k)}(x_0)}{k!}(x-x_0)^k=h(x_0)+h'(x_0)(x-x_0)+\frac{h''(x_0)}{2!}(x-x_0)^2+... h(x)=k=0∑∞k!h(k)(x0)(x−x0)k=h(x0)+h′(x0)(x−x0)+2!h′′(x0)(x−x0)2+...
h ( x 0 + Δ x ) = ∑ k = 0 ∞ h ( k ) ( x 0 ) k ! ( Δ x ) k = h ( x 0 ) + h ′ ( x 0 ) ( Δ x ) + h ′ ′ ( x 0 ) 2 ! ( Δ x ) 2 + . . . h(x_0+\Delta x)=\sum\limits_{k=0}^\infty \frac{h^{(k)}(x_0)}{k!}(\Delta x)^k=h(x_0)+h'(x_0)(\Delta x)+\frac{h''(x_0)}{2!}(\Delta x)^2+... h(x0+Δx)=k=0∑∞k!h(k)(x0)(Δx)k=h(x0)+h′(x0)(Δx)+2!h′′(x0)(Δx)2+...
一元函数: x → x 0 x\to x_0 x→x0 , h ( x ) = h ( x 0 ) + h ′ ( x 0 ) ( x − x 0 ) + o ( x − x 0 ) h(x)=h(x_0)+h'(x_0)(x-x_0)+o(x-x_0) h(x)=h(x0)+h′(x0)(x−x0)+o(x−x0)
二元函数: x → x 0 x\to x_0 x→x0并且 y → y 0 y\to y_0 y→y0, h ( x , y ) = h ( x 0 , y 0 ) + ∂ h ( x 0 , y 0 ) ∂ x ( x − x 0 ) + ∂ h ( x 0 , y 0 ) ∂ y ( y − y 0 ) + o ( x − x 0 ) + o ( y − y 0 ) h(x,y)=h(x_0,y_0)+\frac{\partial h(x_0,y_0)}{\partial x}(x-x_0)+\frac{\partial h(x_0,y_0)}{\partial y}(y-y_0)+o(x-x_0)+o(y-y_0) h(x,y)=h(x0,y0)+∂x∂h(x0,y0)(x−x0)+∂y∂h(x0,y0)(y−y0)+o(x−x0)+o(y−y0)
证明:梯度下降的参数变化会导致损失值下降
梯度下降的参数变化: θ n + 1 = θ n − η ∇ L ( θ n ) \theta^{n+1} = \theta^{n}-\eta \nabla L( \theta^{n}) θn+1=θn−η∇L(θn)
L ( θ n + 1 ) = L ( θ n − η ∇ L ( θ n ) ) = L ( θ n ) + ∇ L ( θ n ) ( − η ∇ L ( θ n ) ) + o ( − η ∇ L ( θ n ) ) = L ( θ n ) − η ( ∇ L ( θ n ) ) 2 + o ( − η ∇ L ( θ n ) ) L(\theta^{n+1})=L(\theta^{n}-\eta \nabla L( \theta^{n}))\\\quad \quad \quad \quad=L(\theta^{n})+\nabla L( \theta^{n})(-\eta \nabla L( \theta^{n}))+o(-\eta \nabla L( \theta^{n}))\\\quad \quad \quad \quad=L(\theta^{n})-\eta(\nabla L( \theta^{n}))^2+o(-\eta \nabla L( \theta^{n})) L(θn+1)=L(θn−η∇L(θn))=L(θn)+∇L(θn)(−η∇L(θn))+o(−η∇L(θn))=L(θn)−η(∇L(θn))2+o(−η∇L(θn))
在 η ∇ L ( θ n ) ) → 0 \eta \nabla L( \theta^{n}))\to0 η∇L(θn))→0的时候, η ( ∇ L ( θ n ) ) 2 > 0 \eta(\nabla L( \theta^{n}))^2>0 η(∇L(θn))2>0, o ( − η ∇ L ( θ n ) ) o(-\eta \nabla L( \theta^{n})) o(−η∇L(θn))可忽略,最终使得 L ( θ n + 1 ) < L ( θ n ) L(\theta^{n+1})<L(\theta^{n}) L(θn+1)<L(θn)。也就是说,在学习率和梯度的乘积 η ∇ L ( θ n ) \eta \nabla L( \theta^{n}) η∇L(θn)趋于0时,梯度下降法使得损失值下降,更一般的说这个值在一定限度内会保证损失值下降。
适应性学习率
通常的梯度下降形式:
θ
t
+
1
←
θ
t
−
η
g
t
\theta^{t+1} \leftarrow \theta^t -ηg^t
θt+1←θt−ηgt
- g t = ∂ L ( θ t ) ∂ θ g^t =\frac{\partial L(\theta^t)}{\partial \theta} gt=∂θ∂L(θt)
- η \eta η为初始设置的常数
简单的Adaptive Learning rate
简单的方法:随着次数的增加,逐渐降低学习率
η t = η t t + 1 , t 是 迭 代 次 数 \eta^t =\frac{\eta^t}{\sqrt{t+1}},t 是迭代次数 ηt=t+1ηt,t是迭代次数
- 初始,离局部最低点比较远,使用大一点的学习率
- 随着迭代增加,离局部最低点越近,因而减少学习率
AdaGrad
θ t + 1 ← θ t − η t σ t g t \theta^{t+1} \leftarrow \theta^t -\frac{η^t}{\sigma^t}g^t θt+1←θt−σtηtgt
- g t = ∂ L ( θ t ) ∂ θ g^t =\frac{\partial L(\theta^t)}{\partial \theta} gt=∂θ∂L(θt)
- η t = η t t + 1 \eta^t =\frac{\eta^t}{\sqrt{t+1}} ηt=t+1ηt
- σ t = 1 1 + t ∑ i = 0 t ( g i ) 2 \sigma^t=\sqrt{\frac{1}{1+t}\sum\limits_{i=0}^{t}(g^i)^2} σt=1+t1i=0∑t(gi)2,将此前所计算的所有梯度值取均方
化简后
θ
t
+
1
=
θ
t
−
η
∑
i
=
0
t
(
g
i
)
2
g
t
\theta^{t+1}=\theta^t-\frac{\eta}{\sqrt{\sum\limits_{i=0}^t(g^i)^2}} g^t
θt+1=θt−i=0∑t(gi)2ηgt
- g t = ∂ L ( θ t ) ∂ θ g^t =\frac{\partial L(\theta^t)}{\partial \theta} gt=∂θ∂L(θt)
- η \eta η为初始设置的常数
反差效果
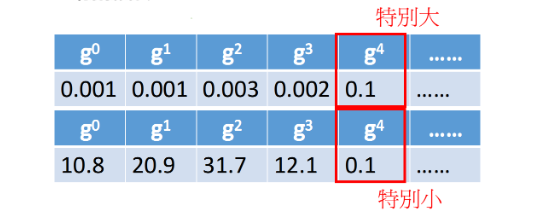
Adagrad考虑的是当迭代越深入,则更新幅度越小,最终趋向于0;并且,使某次变动大的参数更加平滑,造成反差效果。
估测二次微分值,寻找最优参数更新
以二次函数 y = a x 2 + b x + c y=ax^2+bx+c y=ax2+bx+c举例
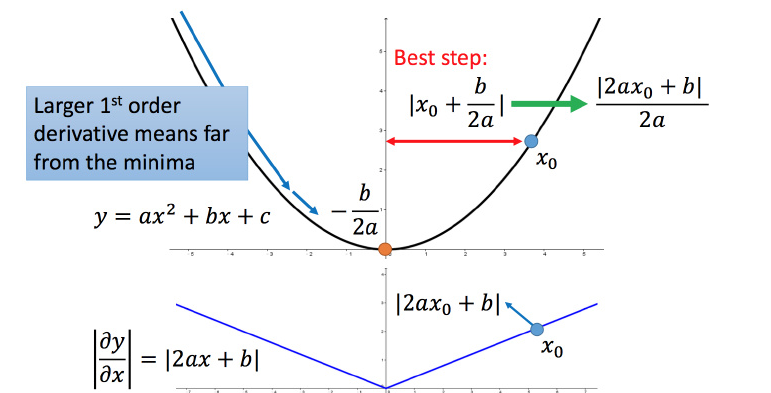
其最小值 x = − b 2 a x=-\frac{b}{2a} x=−2ab,对于任意一点 x 0 x_0 x0,它迈出最好的步伐长度是 ∣ x 0 + b 2 a ∣ = ∣ 2 a x 0 + b 2 a ∣ |x_0+\frac{b}{2a}|=|\frac{2ax_0+b}{2a}| ∣x0+2ab∣=∣2a2ax0+b∣(直接迈到最小值点),而该函数的一阶和二阶导数 y ′ = 2 a x + b y'=2ax+b y′=2ax+b、 y ′ ′ = 2 a y''=2a y′′=2a,可以发现最好的一步是 ∣ y ′ y ′ ′ ∣ |\frac{y'}{y''}| ∣y′′y′∣。
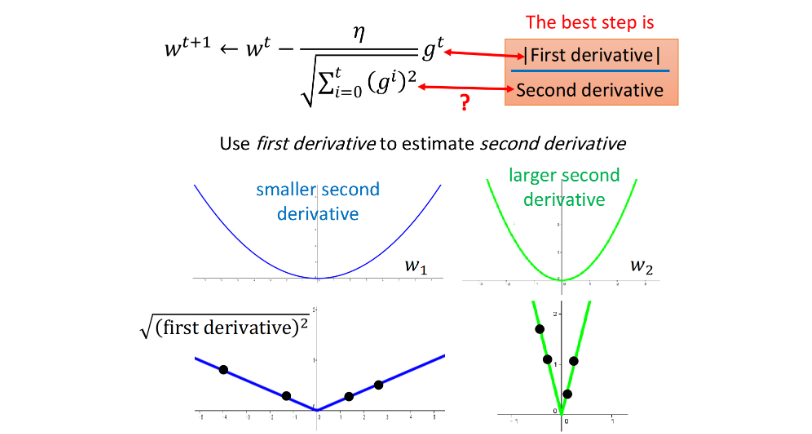
g t g^t gt是一次微分, ∑ i = 0 t ( g i ) 2 \sum\limits_{i=0}^t(g^i)^2 i=0∑t(gi)2近似于二次微分,直接计算二次微分的计算量较大,采用一次微分均方根的形式估测二次微分的值。模拟最优步伐。
Stochastic Gradicent Descent
普通的梯度损失函数:
L = ∑ n ( y ^ n − ( b + ∑ θ i x i n ) ) 2 L=\sum_n(\hat y^n-(b+\sum \theta_ix_i^n))^2 L=n∑(y^n−(b+∑θixin))2
随机梯度下降的损失函数:
L = ( y ^ n − ( b + ∑ θ i x i n ) ) 2 L=(\hat y^n-(b+\sum \theta_ix_i^n))^2 L=(y^n−(b+∑θixin))2
相同的梯度下降公式:
θ i = θ i − 1 − η ▽ L ( θ i − 1 ) \theta^i =\theta^{i-1}- \eta\triangledown L(\theta^{i-1}) θi=θi−1−η▽L(θi−1)
普通梯度下降的损失函数需对所有数据的损失求平方和,后求取梯度,而随机梯度下降,只考虑一个数据,即可进行更新,更新速度跟快。
Feature Scaling
当多个属性的分布相差较大时,建议把他们的范围缩放,使得不同输入的范围是一样的。
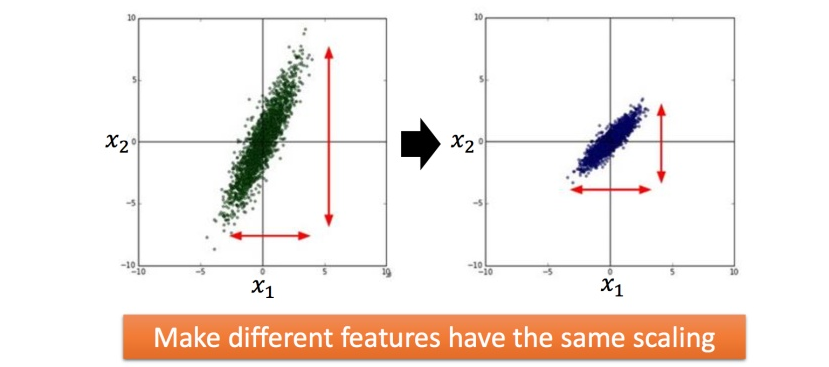
方法
- 对每一个维度(属性),求出平均值 m i m_i mi,标准差 σ i \sigma_i σi;
- 对每一个数据的属性,相应减掉属性均值,除以属性标准差,即 x i r = x i r − m i σ i x_i^r=\frac{x_i^r-m_i}{\sigma_i} xir=σixir−mi。
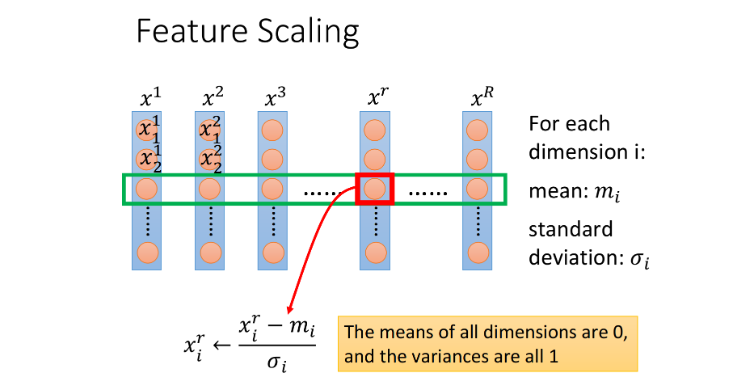
原理
考虑
y
=
θ
0
+
θ
1
x
1
+
θ
2
x
2
y=\theta_0+\theta_1x_1+\theta_2x_2
y=θ0+θ1x1+θ2x2
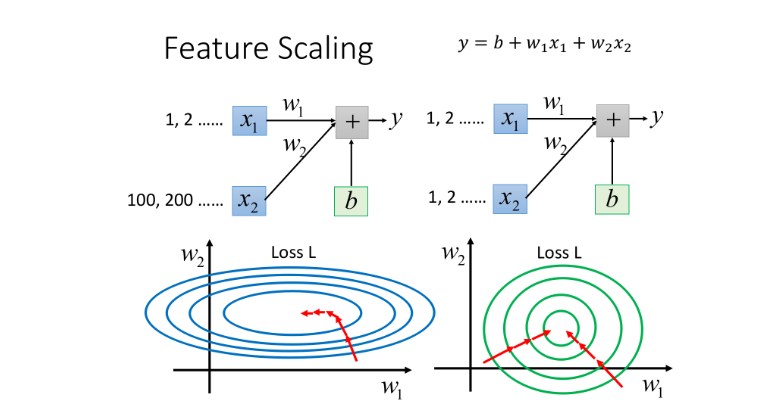
- x 1 x_1 x1的分布为100、200、300…
- x 2 x_2 x2的分布为1、2、3…
当 θ 1 \theta_1 θ1 和 θ 2 \theta_2 θ2 做同样的变化时, θ 1 \theta_1 θ1 对 y y y 的变化影响是比较小的, θ 2 \theta_2 θ2 对 y y y 的变化影响是比较大的;不仅如此,我们的梯度下降可能由于步子大,越过“山谷”。

















 370
370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









