




 本文通过一个具体的案例,详细解析了朴素贝叶斯算法的基本原理。从后验概率的概念出发,介绍了如何利用贝叶斯定理计算样本属于各类别的概率,并探讨了在实际应用中如何构建概率模型。
本文通过一个具体的案例,详细解析了朴素贝叶斯算法的基本原理。从后验概率的概念出发,介绍了如何利用贝叶斯定理计算样本属于各类别的概率,并探讨了在实际应用中如何构建概率模型。
朴素贝叶斯的引入
假设我们有两个盒子,第一个盒子里有大小形状相同的4颗蓝球,1颗绿球;第二个盒子里有大小形状相同的2颗蓝球,3颗绿球。我们从两个盒子里任取一颗球是蓝球,问这颗蓝球从第一个盒子里面取出的概率是多少?
这就是后验概率的问题,根据贝叶斯定理计算如下:
P(B1∣Blue)=P(Blue∣B1)P(B1)P(Blue∣B1)+P(Blue∣B2)P(B2)P(B_1|Blue)=\frac{P(Blue|B_1)P(B_1)}{P(Blue|B_1)+P(Blue|B_2)P(B_2)}P(B1∣Blue)=P(Blue∣B1)+P(Blue∣B2)P(B2)P(Blue∣B1)P(B1)
将上述例子一般化之后就如下图所示:
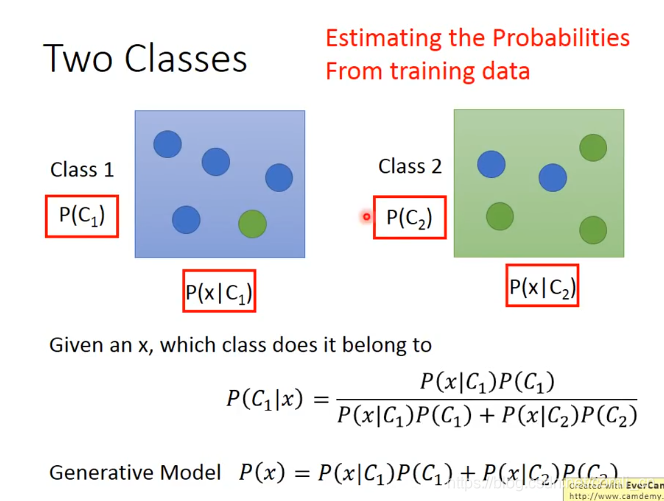
若xxx是蓝色,则P(x∣C1)=45P(x|C_1)=\frac{4}{5}P(x∣C1)=54, P(C1)=510=12P(C_1)=\frac{5}{10}=\frac{1}{2}P(C1)=105=21,P(x∣C2)=25P(x|C_2)=\frac{2}{5}P(x∣C2)=52, P(C2)=510=12P(C_2)=\frac{5}{10}=\frac{1}{2}P(C2)=105=21
通过上面的推论我们知道了如何求取一个新给的样本属于各个类别的概率,但上面所讲的是在一个封闭的系统(xxx只能从两个盒子里面抽取)里面的概率,且我们可以直接看出两个类别的概率分布。然而,在实际的应用中我们往往没有某一个类别精确的概率分布,我们的训练集也无法穷举所有的可能性,这时候就要求我们对一个类别求取一个最符合它样本分布的概率模型,以便我们在这个概率模型下计算P(x∣Ci)P(x|C_i)P(x∣Ci)。
如何求取概率模型
我们先假设数据的概率分布(正态、伯努利、播送、···),然后用概率公式去计算xxx属于的类型P(C1∣x)P(C_1|x)P(C1∣x)。
一般的,我们假设xxx为高斯分布,这是由概率论中的中心极限定理所得来的。
多维高斯分布:
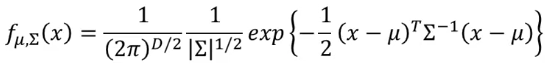
其中均值为μ\muμ,协方差为∑\sum∑
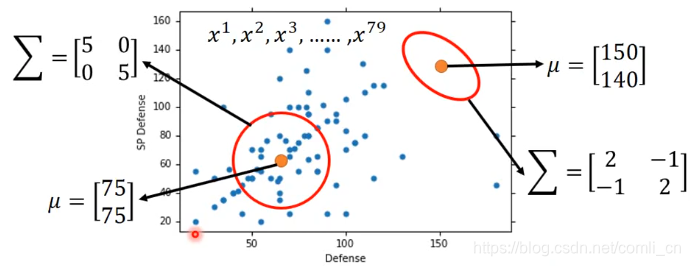
这里举个例子来看一下不同的μ\muμ和∑\sum∑对分布的影响:
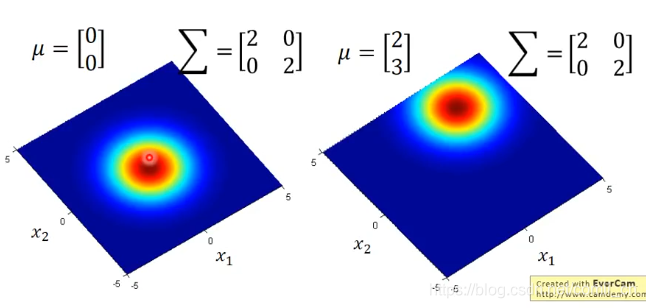
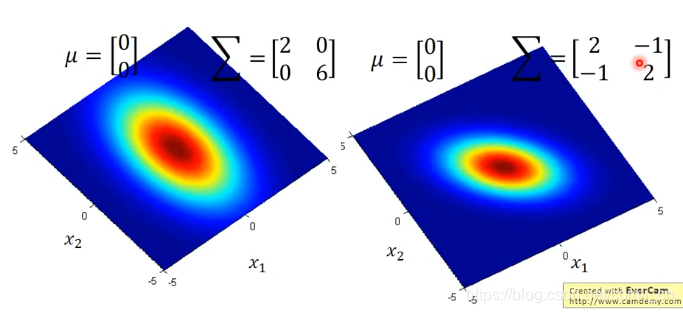
接下来就是求取这个假设的分布中的参数μ\muμ和∑\sum∑了,这里用极大似然估计来求取。比如说我们用某个模型生成了下图所示的79个样本点,那么我们的目的就是要求最有可能生成这79个样本点的模型,即求出这个模型的μ\muμ和∑\sum∑。
这里我们用下面的极大似然估计的函数:
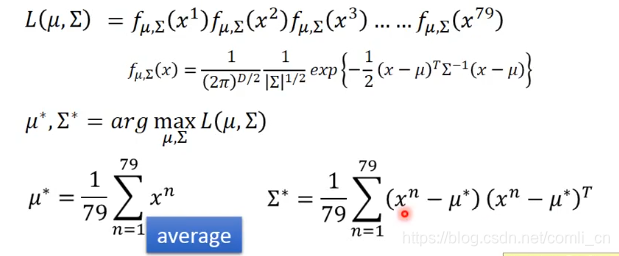
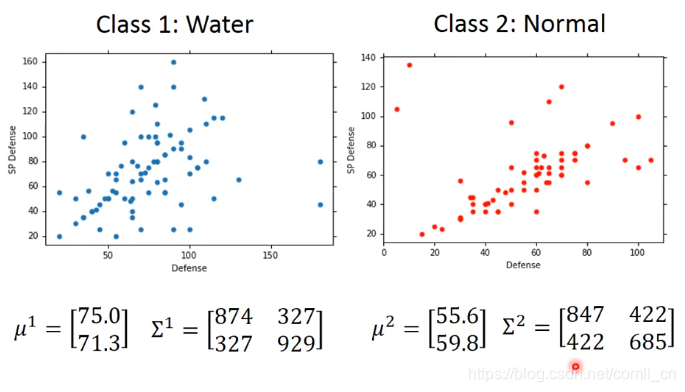
我们按照上式和两个类别的训练集来求出两个类别的极大似然估计函数的系数(第一个类别中有79个样本,第二个类别中有61个样本):
分类
接下来就可以将分布函数带入到贝叶斯函数中来进行分类了:
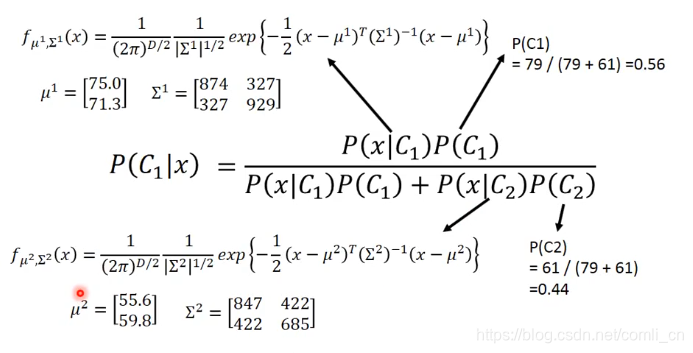
如果P(C1∣x)>0.5P(C_1|x)>0.5P(C1∣x)>0.5则可以推出xxx是属于第一类的。
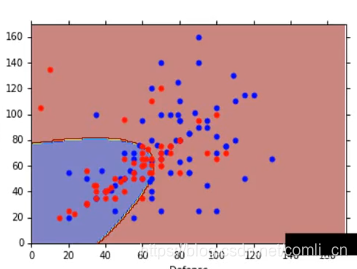
但通常情况是两个模型会共用一个∑\sum∑,那么似然函数就变成了:
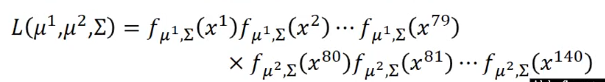
这个式子中的μ1\mu_1μ1和μ2\mu_2μ2和上面的式子中是一样的,∑=79140∑1+61140∑2\sum=\frac{79}{140}\sum^1+\frac{61}{140}\sum^2∑=14079∑1+14061∑2
这个时候就变成了线性分类:
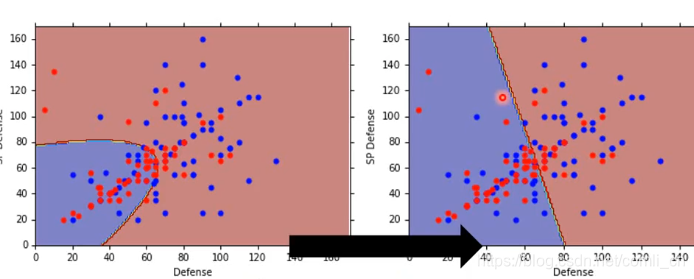
可以看到上面的模型分类准确率并不高,这可能是特征值选取的比较少,在增加特征值之后会好很多。



















 602
602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











