







 本文分享了作者在使用Lattice Diamond软件时遇到的license问题,包括版本更新、环境变量设置、申请步骤和物理地址获取等关键环节,最终通过正确操作成功解决。
本文分享了作者在使用Lattice Diamond软件时遇到的license问题,包括版本更新、环境变量设置、申请步骤和物理地址获取等关键环节,最终通过正确操作成功解决。
使用小脚丫FPGA的diamond软件license莫名其妙过期了,多次申请后都不能成功注册,最后换了一个版本的diamond,然后卸载了radiant,环境变量重新设置一番,终于成功。记录一下。
- diamond和radiant都是lattice软件,安装目录可以一致,但是,环境变量要注意,设置两个license路径。
- 可以把先安装并注册过license的软件环境变量放后面,新安装的放第一个。
- 同一台电脑可以申请多次license。
- 申请过程:
去他家的网站:
https://www.latticesemi.com/en/Products/DesignSoftwareAndIP/FPGAandLDS/LatticeDiamond.aspx
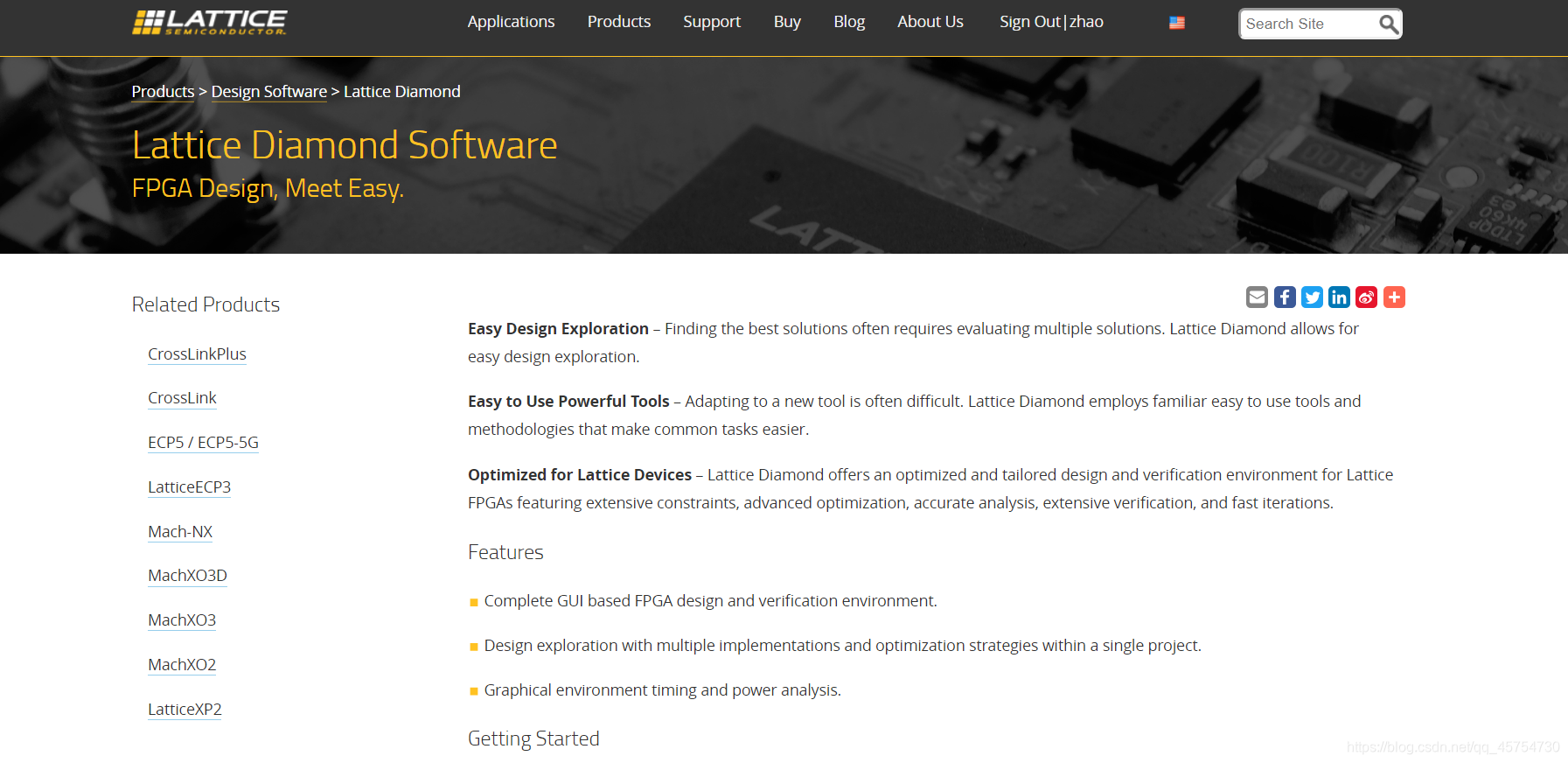
下滑;点击licensing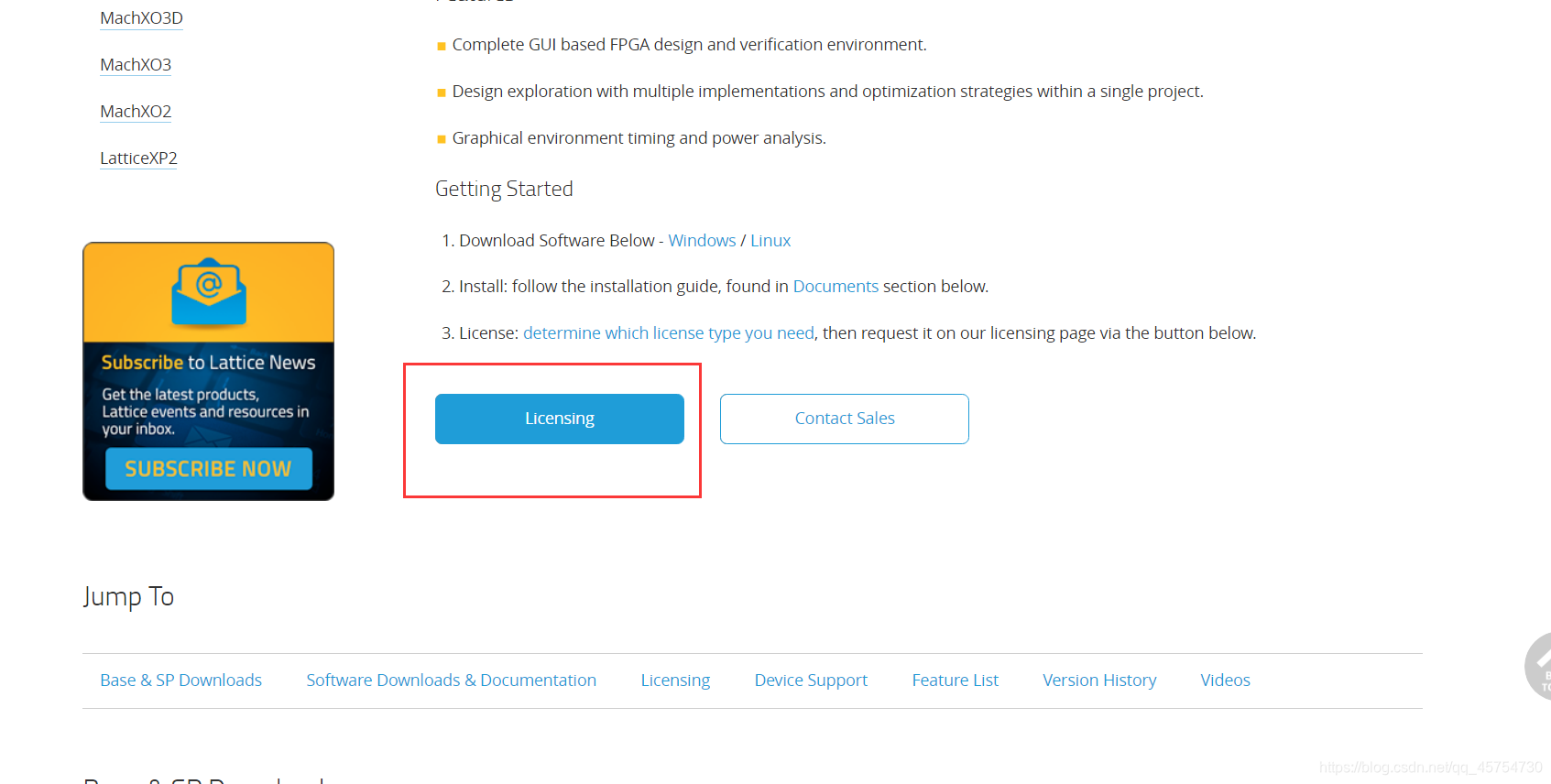
看清楚自己是什么软件(Diamond和Radiant的license不能混用);点击对应的request,建议选择Node-locked;不要问我为什么。(气死我了,多次申请floating就是不行)

其实你还需要注册邮箱账号的。。。
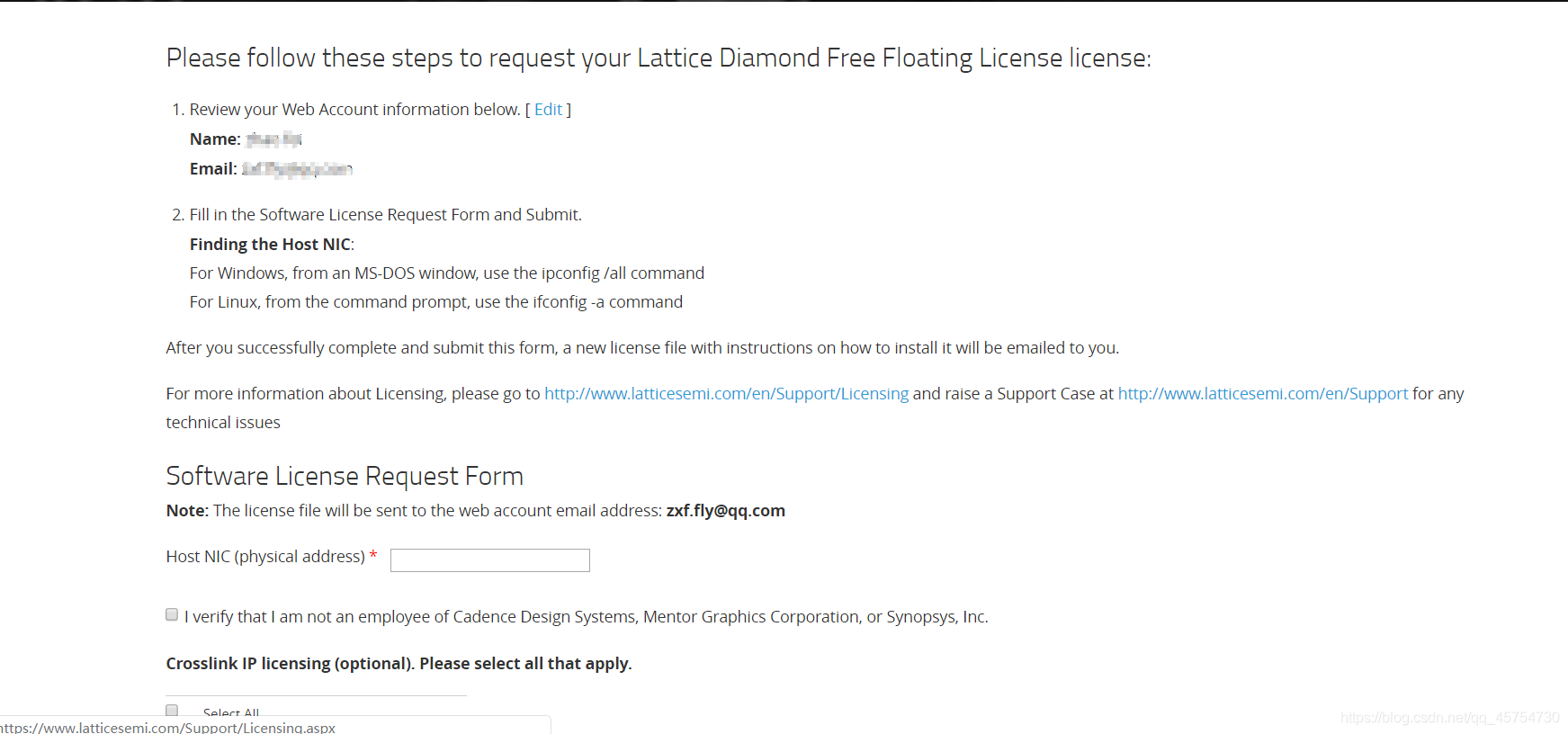
什么是物理地址?

你且往下看,分为三步走:
打开WiFi,点击连接的那个的属性(别跟我说你没连网)
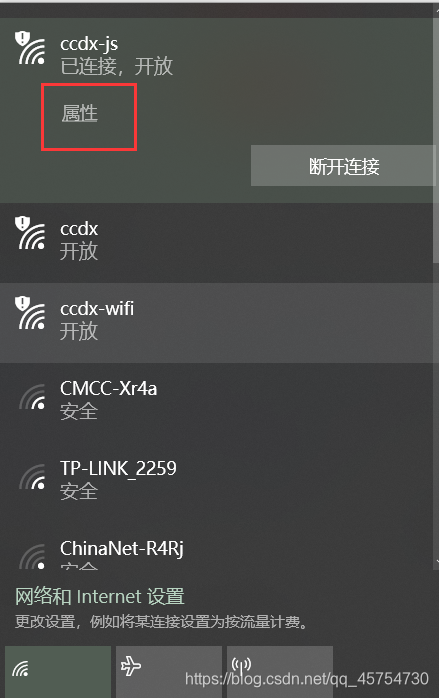
点开之后下滑:

只需要框框里的一串,搞到刚刚需要物理地址一栏中。(好像只有两步)
然后看见框框就打勾,看见选择就yes
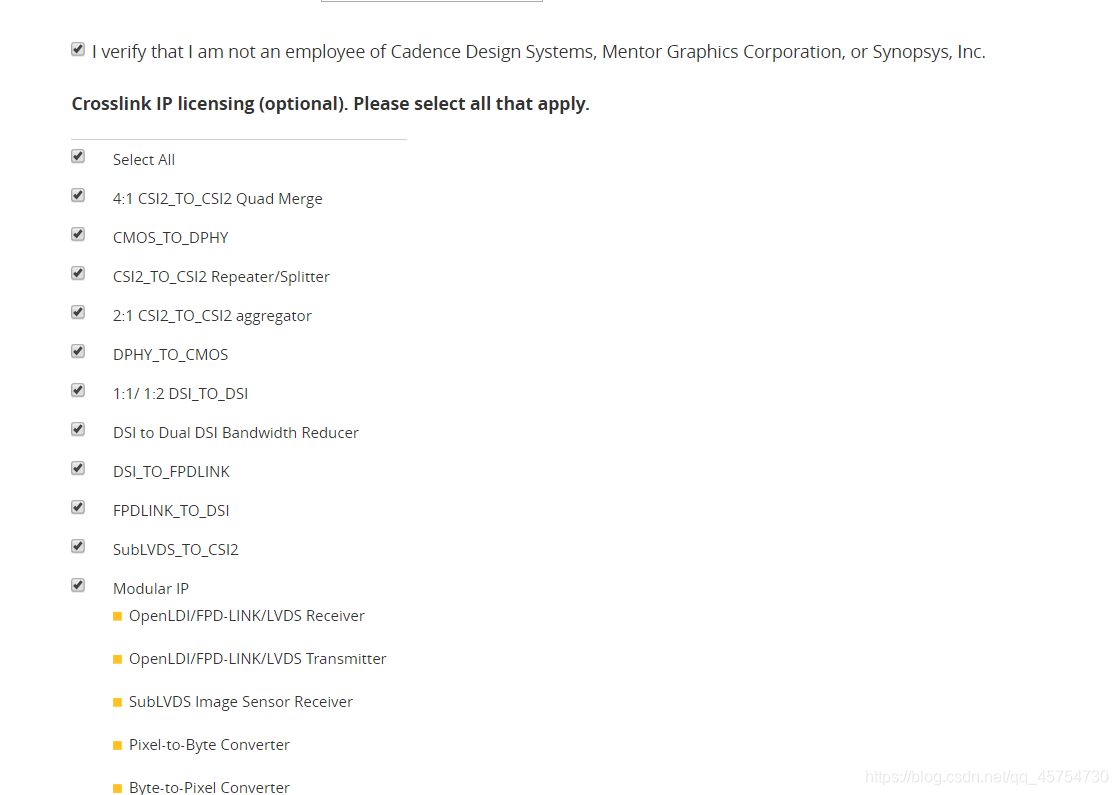
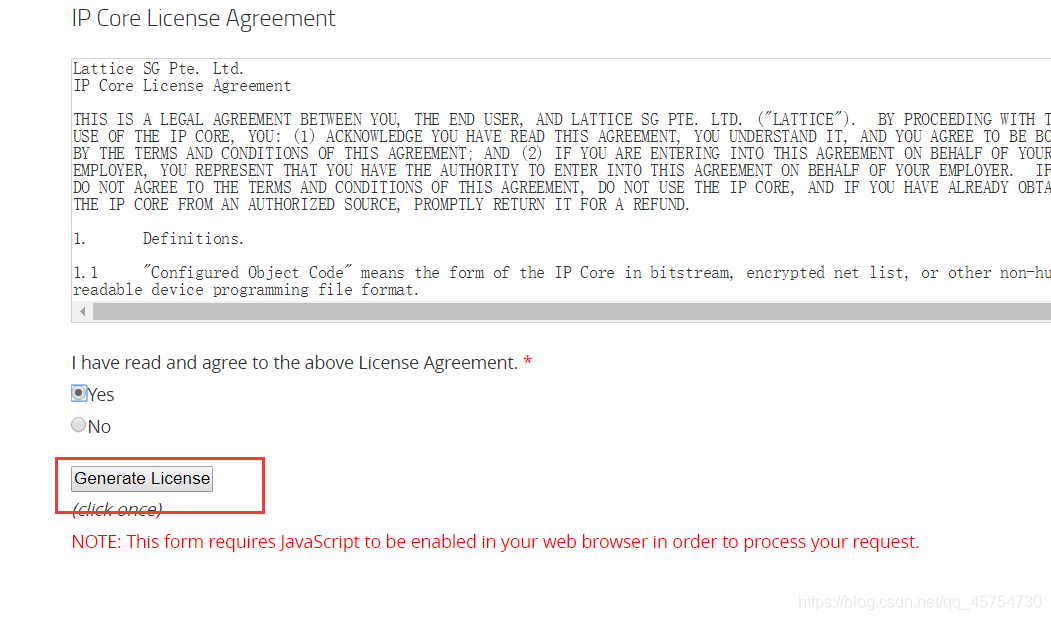
最后也可能“Generate License”是灰色的,翻到上面物理地址看一下:
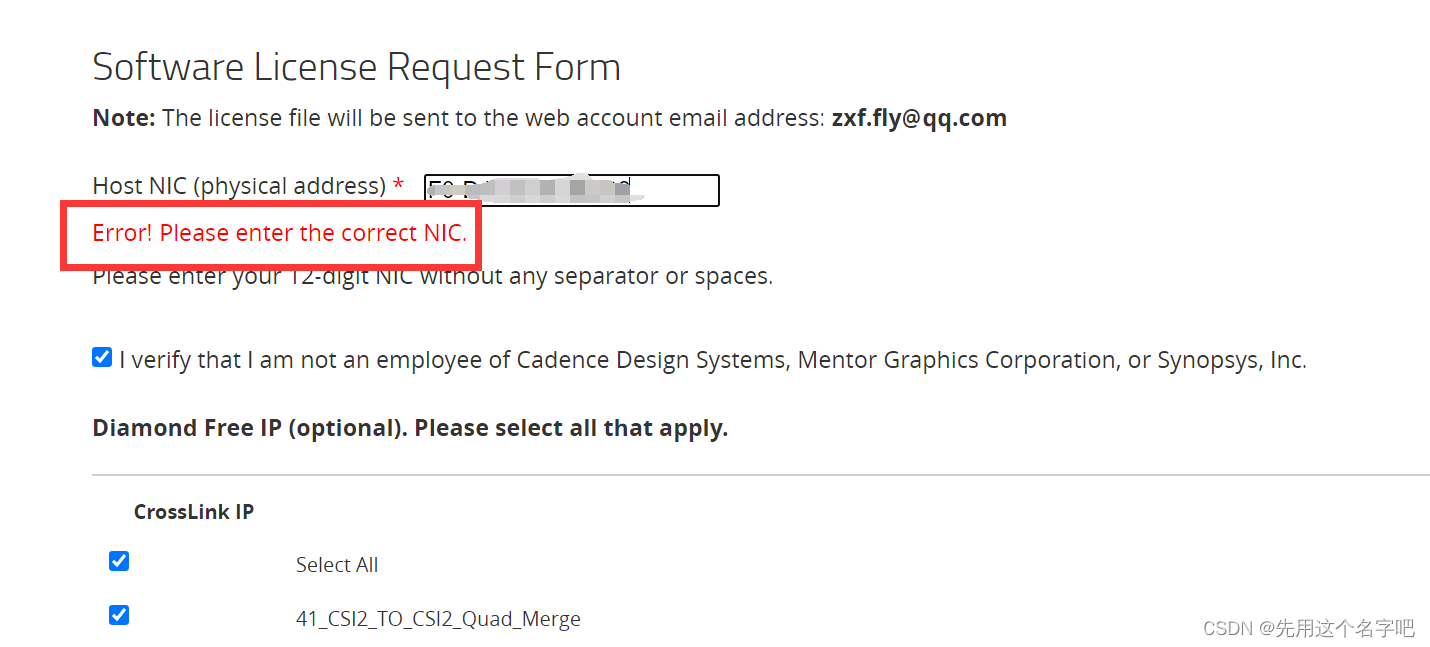
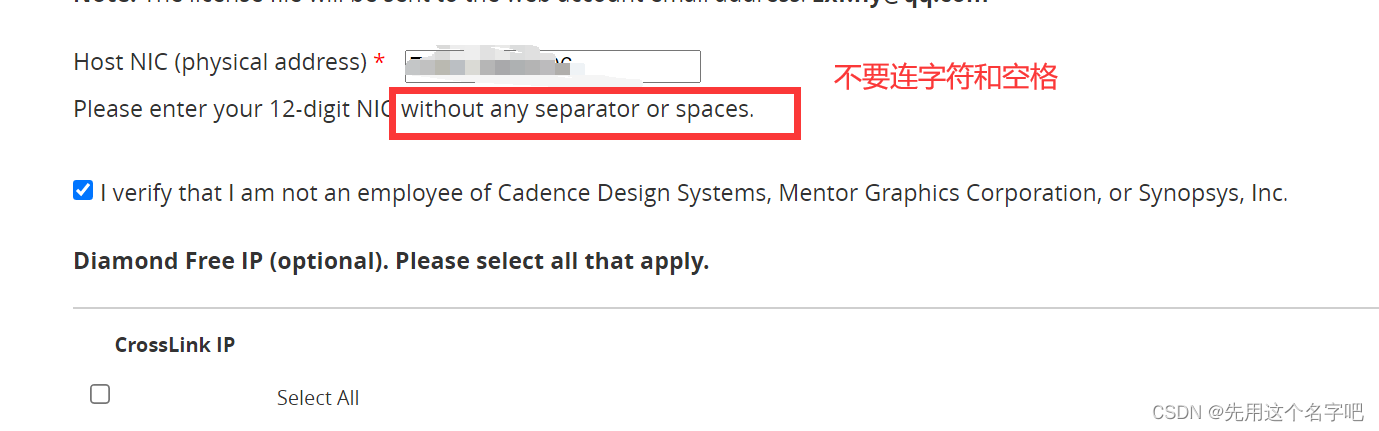
最后点击generate license,就会得到一个附有许可证文件的邮件
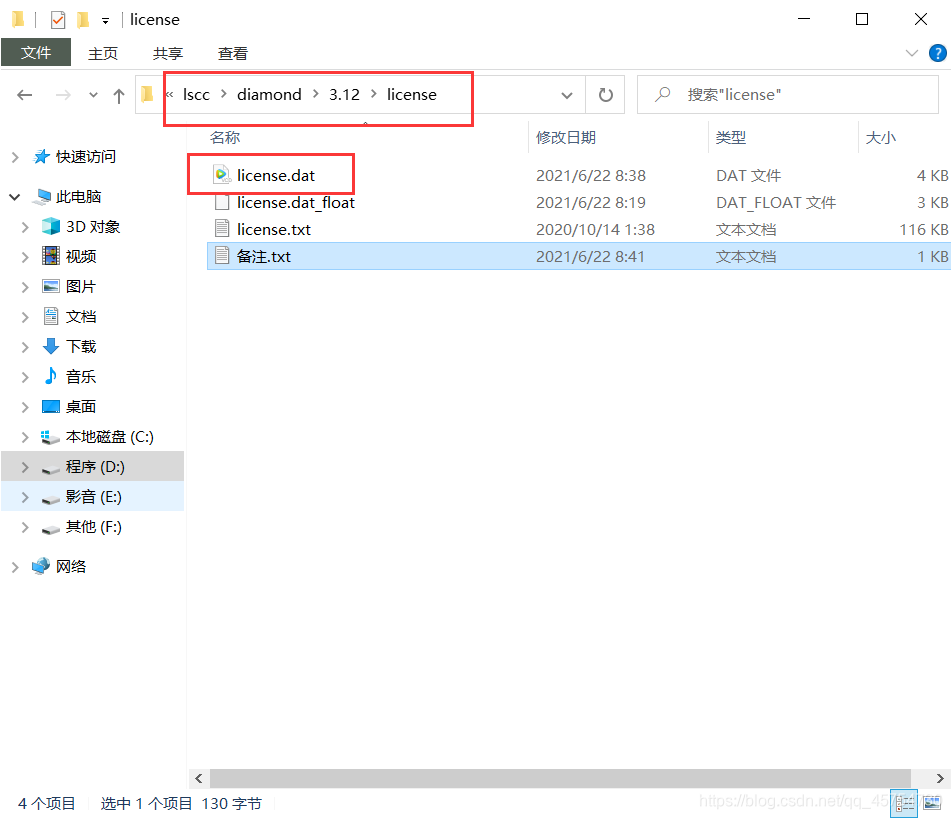
等待邮箱license到来,下载后搞到安装目录的这个文件夹下。
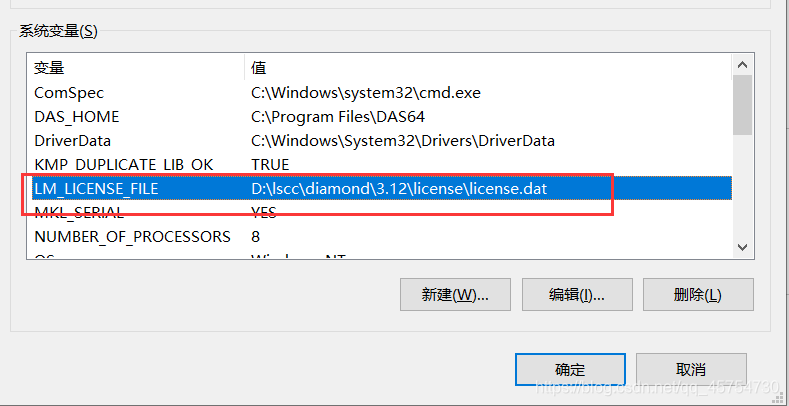
建议运行前看一下系统环境变量,下图才是正常的。
(window10/11任务栏或者开始的搜索可以直接搜索“环境变量”)
打开软件看看是不是成功了?
反正我是成功了,而且成功了好几次。

















 3857
3857

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









