



- 一、内核链表
- 内核链表是操作系统内核中用于管理内存中数据结构的一种方式,特别是在Linux内核中。它提拱了一种灵活且高效的方法来组织和管理数据,如进程、缓冲区、定时器等。内核链表的设计允许快速插入、删除和遍历节点,这对于需要高效率和实时响应的内核操作至关重要
- 可以给里面放不止一套相同类型的数据,但数据的对象不同
- 内核链表是双向链表、有头链表,循环链表
- 内核链表的特点
- 双向链表:大多数内核链表是双向循环链表,这意味着每个节点都有指向前一个和后一个节点的指针。这使得从链表中任意位置插入和删除节点都变得容易
- 内存管理:内核链表通常用于管理内核空间的内存,因此它们需要高效且占用空间小
- 并发控制:由于内核代码可能被多个处理器或线程同时访问,内核链表的实现通常需要考虑并发控制,如使用自旋锁或互斥锁
- 性能优化:内核链表的设计通常针对性能进行了优化,以减少内存访问延迟和提高处理速度
- 将节点放在存储数据的结构体中
- 怎么通过节点获取数据呢------->内核提供了两个宏:
- offset of:获取结构体成员到结构体开头的偏移量
- contianer_of:通过偏移量获取结构体首地址
- 构建一个类内核链表实现航班及乘客查询(即将节点放在结构体
- 二、栈区
- 计算机中的内存管理
- 内核:指操作系统内核,是操作系统的核心组件,负责管理系统资源
- 堆区:主要用于动态内存分配(malloc/free)
- 栈区:用于存储程序执行期间的临时变量,如函数调用的参数、局部变量和返回地址。栈的内存分配和回收是自动的
- 数据区:数据区通常用于存储全局变量和静态变量。这个区域可以进一步分为初始化数据区(用于存储初始化的全局变量和静态变量)和未初始化数据区(也称为 BSS 段,用于存储未初始化的全局变量和静态变量)
- 文本区:文本区或代码区用于存储程序的执行代码,也就是 CPU 执行的机器指令
- 栈区
- 存放的数据类型
- 局部变量:函数内的局部变量通常存储在栈上。当函数被调用时,其局部变量被创建并推入栈中,函数执行完毕后,这些变量随栈帧(stack frame)一起被销毁
- 函数参数:函数的形参和返回值通常存放在栈区
- 返回地址:栈区在函数进行函数调用时,会保存调用的函数的入口地址(保护现场)
- 保护现场和恢复现场的规则:先入后出,后入先出
- 递归调用的嵌套关系:在递归函数中,每次递归调用都会生成一个新的栈帧,包含该调用的局部变量和返回地址,这些栈帧在递归调用返回时被销毁
- 存放的数据类型
- 数据栈(通常的“栈”)和系统栈(调用栈)的区别与联系
- 用途
- 数据栈:用于存储程序运行时的临时数据,如表达式求值、函数调用的中间结果等
- 系统栈:用于跟踪函数调用的顺序和状态,包括存储局部变量、参数、返回地址和函数的执行环境
- 控制方式
- 数据栈:由程序员在代码中通过栈操作函数控制
- 系统栈:由操作系统和运行时环境自动管理,例如在函数调用和返回时自动压栈和出栈
- 作用域
- 数据栈:用于存储不同作用域的数据,但通常用于局部作用域
- 系统栈:用于存储函数调用的作用域信息,每个函数调用都有自己的栈帧
- 相同之处
- LIFO(后进先出)原则:无论是数据栈还是系统栈,都遵循 LIFO 的原则,即最后进入的元素会第一个被移除
- 栈操作:两者都使用类似的基本操作,如 push(压栈)和 pop(出栈),来添加和移除元素
- 内存管理:它们都涉及到内存的分配和释放。数据栈和系统栈在添加元素时分配内存,在移除元素时释放内存
- 数据结构:从数据结构的角度看,它们都是栈这种抽象数据类型的实现,无论是在硬件层面还是软件层面
- 用途
- 数据栈(栈)
- 只允许从一端进行数据的插入和删除的线性的存储结构
- 数据插入:入栈,压栈
- 数据出栈:出栈,弹栈
- 数据栈分类
- 顺序栈:用数组实现
- 链式栈:用链表实现
- 栈结构:满增栈 满减栈 空减栈 空增栈
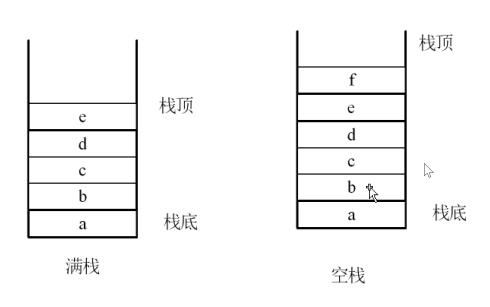
- 满栈、空栈:
- 满栈的入栈顺序,先移动栈顶,再入栈数据
- 空栈的入栈顺序:先入栈一个数据,再移动栈顶
- 出栈顺序:先移动的栈顶,再移出数据
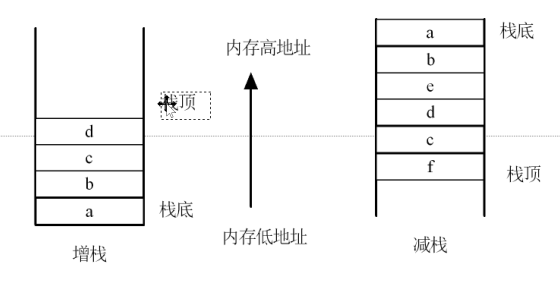
- 增栈、减栈:
- 增栈:无论是满栈还是空栈,加入数据后,栈顶是由内存低地址移向高地址就是增栈
- 减栈:栈顶由内存高地址移向内存低地址
- 满栈、空栈:
- 创建链式栈
- 计算机中的内存管理
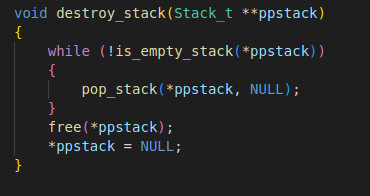
- 入栈
- 出栈
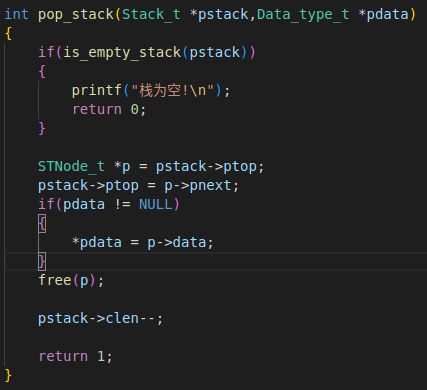
- 判断是否为空栈
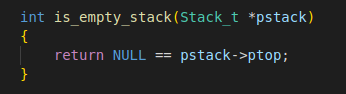
- 获取栈顶元素
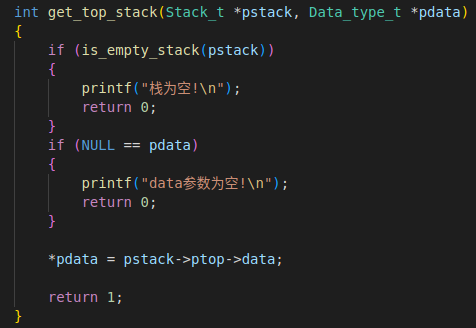
- 销毁栈
- 三、队列
- 允许从一端插入数据,另一端删除数据的线性的存储结构

- 队尾:插入数据 入队
- 队头:取出数据 出队
- (FIFO原则)先进先出,后进后出
- 管道的本质就是一个队列
- 缓冲区:匹配高速设备和低速设备之间的效率问题
- 队列就可以作为缓冲区来解决高低速设备之间传输时的效率
- 队列分类:
- 顺序队列:数组 存在假溢出问题,所以一般使用顺序队列的时候用循环顺序队列
- 循环队列为了区分队列为空为满,会留出一个数据的空间不做数据存储
- 循环顺序队列判空:队头和队尾处于同一位置,此时认为队列为空
- 循环顺序队列判满:当队尾+1为队头的位置时,此时认为队列为满
- 链式队列:链表
- 顺序队列:数组 存在假溢出问题,所以一般使用顺序队列的时候用循环顺序队列
- 允许从一端插入数据,另一端删除数据的线性的存储结构
- 四、队列和栈之间的区别
- 数据访问原则:
- 栈:遵循后进先出(LIFO,Last-In-First-Out)的原则,即最后添加到栈的元素会第一个被移除
- 队列:遵循先进先出(FIFO,First-In-First-Out)的原则,即最先添加到队列的元素会第一个被移除
- 操作方式
- 栈:主要操作包括 push(在栈顶添加元素)和 pop(从栈顶移除元素)还有一个 peek 或 top 操作,用来查看栈顶元素但不移除它
- 队列:主要操作包括 enqueue(在队尾添加元素)和 dequeue(从队首移除元素)同样有 front 操作,用来查看队首元素但不移除它
- 使用场景:
- 栈:常用于处理具有递归结构的问题,如函数调用堆栈、表达式求值、括号匹配、回溯算法等
- 队列:常用于处理消息队列、任务调度、广度优先搜索算法、打印机任务排队等场景
- 内存利用率:
- 栈:由于其 LIFO 的特性,栈的内存利用率通常较高,因为栈顶的内存可以快速地被重新利用
- 队列:可能需要更多的内存,因为元素在队列中停留的时间可能更长,直到它们到达队首被移除
- 数据访问原则:

















 682
682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









