







 本文详细介绍了哈希表和有序表的概念,包括它们的使用场景、C++中的实现(如unordered_set、unordered_map、set、map)以及各种操作(插入、删除、查找、统计等)。此外,还探讨了单向和双向链表的翻转,如何找出两个有序链表的公共部分,以及判断链表是否为回文结构的方法。文章最后讨论了链表解题的方法论,如如何高效地处理链表问题。
本文详细介绍了哈希表和有序表的概念,包括它们的使用场景、C++中的实现(如unordered_set、unordered_map、set、map)以及各种操作(插入、删除、查找、统计等)。此外,还探讨了单向和双向链表的翻转,如何找出两个有序链表的公共部分,以及判断链表是否为回文结构的方法。文章最后讨论了链表解题的方法论,如如何高效地处理链表问题。
文章目录
1.哈希表的简单介绍
(1)哈希表在使用层面上可以理解为一种集合结构
(2)如果只有key,没有伴随数据value,C++可以使用unordered_set
(3)如果既有key,又有伴随数据value,C++可以使用unordered_map
(4)有无伴随数据,是unordered_set和unordered_map唯一的区别,底层的实际结构是一回事
(5)使用哈希表增(insert)、删(erase)的操作,可以认为时间复杂度为O(1),但是常数时间比较大
(6)放入哈希表的东西,如果是基础类型,内部按值传递,内存占用就是这个东西的大小
(7)放入哈希表的东西,如果不是基础类型,内部按引用传递,内存占用是这个东西内存地址的大小
(8)unordered_set:
#include<iostream>
using namespace std;
#include<unordered_set>
//unordered_set容器介绍
//无序性:unordered_set将相同键值的元素放到相同的桶中
//唯一标识性:元素的值同时也是唯一地标识它的key
//构造函数:默认构造 拷贝构造 通过数组构造 通过迭代器区间构造
int main() {
//默认构造
unordered_set<int>us1;
us1.insert(1);
us1.insert(1);//相同元素,unordered_set会自动去重,只保留一个
cout << us1.size() << endl;//插入了相同元素,因此size()的值不是2.而是1
//拷贝构造
unordered_set<int>us2(us1);
//通过数值构造
unordered_set<int>us3({ 1,2,5,5,6,8 });
//通过迭代器构造
unordered_set<int>us4(us3.begin(), us3.end());
system("pause");
return 0;
}
#include<iostream>
using namespace std;
#include<unordered_set>
//插入和删除:insert&erase
int main() {
unordered_set<int>us1({ 1,2,5,5,6,8 });
//插入
us1.insert(10);
us1.insert(10);//会自动去重
//删除
us1.erase(8);//根据键值删除
unordered_set<int>::iterator pos = us1.find(10);//find()查找元素,找到返回迭代器,找不到返回end()
if (pos != us1.end()) {
us1.erase(pos);//通过迭代器删除
}
//遍历
//方式1
for (auto a : us1) {
cout << a << " ";
}
cout << endl;
//方式2
for (unordered_set<int>::iterator it = us1.begin(); it != us1.end(); it++) {
cout << *it << " ";
}
cout << endl;
//count()查找相应值的个数,因为unordered_set不允许重复,则结果为0或1
cout << us1.count(11) << endl;
//容器大小size()
cout << us1.size() << endl;
//清空容器:clear()
us1.clear();
//判断容器是否为空:empty()
cout << us1.empty() << endl;
//交换两个容器:swap()
unordered_set<int>temp{ 11,12,13 };
us1.swap(temp);
for (auto a : us1) {
cout << a << " ";
}
cout << endl;
system("pause");
return 0;
}
(8)unordered_map:
#include<iostream>
using namespace std;
#include<unordered_map>
//unordered_map简介
/*
unordered_map,它是一个关联容器,内部采用的是hash表结构,拥有快速检索的功能。
关联性:键值对key-value,(*it).first为key,(*it).second为value
无序性:内部无序,不提供顺序遍历
键唯一性:不存在两个一样的键
数据存储结构:哈希表(链地址法解决冲突,像个桶(bucket),每个哈希桶中可能没有元素,也可能有多个元素)
*/
//构造函数
int main() {
unordered_map<string, string>first;//默认构造
unordered_map<string, string>second({ {"apple","red"},{"lemon","yellow"} });//通过数组构造
unordered_map<string, string>third({ {"orange","orange"},{"strawberry","red"} });
unordered_map<string, string>fourth(second);//拷贝构造
unordered_map<string, string>fifth(fourth.begin(), fourth.end());//通过区间的方式进行构造
//遍历
cout << "second contains:" << endl;
for (auto x : second) {
cout << " " << x.first << ":" << x.second << endl;
}
cout << endl;
cout << "third contains:" << endl;
for (auto x : third) {
cout << " " << x.first << ":" << x.second << endl;
}
cout << endl;
cout << "fourth contains:" << endl;
for (auto x : fourth) {
cout << " " << x.first << ":" << x.second << endl;
}
cout << endl;
cout << "fifth contains:" << endl;
for (auto x : fifth) {
cout << " " << x.first << ":" << x.second << endl;
}
cout << endl;
system("pause");
return 0;
}
#include<iostream>
using namespace std;
#include<unordered_map>
//.size();返回unordered_map的大小
//.empty();空返回true,不为空返回false
int main() {
unordered_map<string, string>first({ {"apple","red"},{"lemon","yellow"} });//通过数组构造
if (first.empty()) {
cout << "first为空" << endl;
}
else {
cout << "first大小为:" << first.size() << endl;
cout << "first contains:" << endl;
for (auto x : first) {
cout << " " << x.first << ":" << x.second << endl;
}
cout << endl;
}
system("pause");
return 0;
}
#include<iostream>
using namespace std;
#include<unordered_map>
//插入:insert
//删除:erase
//清空:clear
int main() {
pair<string, string>mypair("orange", "orange");
unordered_map<string, string>first({ {"apple","red"},{"lemon","yellow"} });//通过数组构造
unordered_map<string, string>second = { {"banana","yellow"},{"pear","white"} };//初始化,重载了=
//插入
first.insert(mypair);//复制插入
first.insert(make_pair<string, string>("strawberry", "red"));//移动插入
first.insert(second.begin(), second.end());//范围插入
first.insert({ "peach","pink" });//数组插入(可以用二维一次插入多个元素,也可以用一维插入一个元素)
first["strawberry"] = "pink";//数组形式插入
//遍历
for (auto x : first) {
cout << " " << x.first << ":" << x.second << endl;
}
cout << endl;
cout << endl;
//删除
first.erase(first.begin());//通过位置
first.erase("peach");//通过key
//遍历
for (auto x : first) {
cout << " " << x.first << ":" << x.second << endl;
}
cout << endl;
cout << endl;
//清空
first.clear();
//遍历
for (auto x : first) {
cout << " " << x.first << ":" << x.second << endl;
}
cout << endl;
cout << endl;
system("pause");
return 0;
}
#include<iostream>
using namespace std;
#include<unordered_map>
//修改
//at();的方式
//数组的方式
//查找
//iterator find ( const key_type& k );
//找key所在的元素。找到:返回元素的迭代器;没找到:返回unordered_map::end
//交换
int main() {
unordered_map<string, string>first({ {"apple","red"},{"lemon","yellow"} });//通过数组构造
unordered_map<string, string>second = { {"banana","yellow"},{"pear","white"} };
first.at("apple") = "pink";//at()
first["lemon"]="blue";//数组的方式
//遍历
for (auto x : first) {
cout << " " << x.first << ":" << x.second << endl;
}
cout << endl;
//查找
unordered_map<string, string>::iterator it = first.find("apple");
if (it != first.end()) {
cout << it->second << endl;
}
//交换
first.swap(second);
//遍历
cout << "this is first:" << endl;
for (auto x : first) {
cout << " " << x.first << ":" << x.second << endl;
}
cout << endl;
cout << "this is second:" << endl;
for (auto x : second) {
cout << " " << x.first << ":" << x.second << endl;
}
cout << endl;
system("pause");
return 0;
}
#include<iostream>
using namespace std;
#include<unordered_map>
int main() {
unordered_map<string, string>first({ {"apple","red"},{"lemon","yellow"} });//通过数组构造
unordered_map<string, string>second = { {"banana","yellow"},{"pear","white"} };
first.insert(second.begin(), second.end());
//遍历
//begin()和end()迭代器
for (unordered_map<string, string>::iterator it = first.begin(); it != first.end();it++) {
cout << " " << it->first << ":" << it->second << endl;
}
cout << endl;
//bucket
cout << first.bucket("peach") << endl;//返回通过哈希计算key所在的bucket(序号从0开始)(注意:这里仅仅做哈希计算确定bucket,并不保证key一定存在bucket中!)
cout << first.bucket_count() << endl;//返回bucket总数
cout << first.bucket_size(0) << endl;//返回第n个bucket的大小(这个位置的桶子里有几个元素,注意:函数不会判断n是否在count范围内)
system("pause");
return 0;
}
2.有序表的简单介绍
(1)有序表在使用层面上可以理解为一种集合结构
(2)如果只有key,没有伴随数据value,C++可以使用set
(3)如果既有key,又有伴随数据value,C++可以使用map
(4)有无伴随数据,是set和map唯一的区别,底层的实际结构是一回事
(5)有序表和哈希表的区别是,有序表把key按照顺序组织起来,而哈希表完全不组织
(6)红黑树、AVL树、size-balance-tree和跳表等都属于有序表结构,只是底层具体实现不同
(7)放入哈希表的东西,如果是基础类型,内部按值传递,内存占用就是这个东西的大小
(8)放入哈希表的东西,如果不是基础类型,必须提供比较器,内部按引用传递,内存占用是这个东西内存地址的大小
(9)set:
#include<iostream>
using namespace std;
#include<set>
//set容器构造和赋值
void printSet(set<int>& s) {
for (set<int>::iterator it = s.begin(); it != s.end(); it++) {
cout << *it << " ";
}
cout << endl;
}
void test01() {
set<int>s1;//默认构造
//插入数据只有insert方式
s1.insert(10);
s1.insert(20);
s1.insert(40);
s1.insert(30);
s1.insert(30);
//遍历容器
//set容器特点:所有元素插入时自动排序,set容器不允许插入重复值,可以插入,但不会保存
printSet(s1);
//拷贝构造
set<int>s2(s1);
printSet(s2);
//赋值
set<int>s3;
s3 = s2;
printSet(s3);
}
void test02() {
set<int>s1;//默认构造
//插入数据只有insert方式
s1.insert(10);
s1.insert(20);
s1.insert(10);
s1.erase(10);
//遍历容器
//set容器特点:所有元素插入时自动排序,set容器不允许插入重复值,可以插入,但不会保存
printSet(s1);
//拷贝构造
set<int>s2(s1);
printSet(s2);
//赋值
set<int>s3;
s3 = s2;
printSet(s3);
}
int main() {
test01();
system("pause");
return 0;
}
#include<iostream>
using namespace std;
#include<set>
//set容器大小和交换
void printSet(set<int>& s) {
for (set<int>::iterator it = s.begin(); it != s.end(); it++) {
cout << *it << " ";
}
cout << endl;
}
//大小
void test01() {
set<int>s1;
s1.insert(10);
s1.insert(20);
s1.insert(40);
s1.insert(30);
s1.insert(30);
printSet(s1);
if (s1.empty()) {
cout << "s1为空" << endl;
}
else {
cout << "s1不为空" << endl;
cout << "s1大小:" << s1.size() << endl;
}
}
//交换
void test02() {
set<int>s1;
s1.insert(10);
s1.insert(20);
s1.insert(40);
s1.insert(30);
s1.insert(30);
set<int>s2;
s2.insert(100);
s2.insert(200);
s2.insert(400);
s2.insert(300);
s2.insert(300);
printSet(s1);
printSet(s2);
s1.swap(s2);
printSet(s1);
printSet(s2);
}
int main() {
test01();
test02();
system("pause");
return 0;
}
#include<iostream>
using namespace std;
#include<set>
//set容器插入和删除
void printSet(set<int>& s) {
for (set<int>::iterator it = s.begin(); it != s.end(); it++) {
cout << *it << " ";
}
cout << endl;
}
//大小
void test01() {
set<int>s1;
//插入
s1.insert(20);
s1.insert(10);
s1.insert(40);
s1.insert(30);
s1.insert(30);
printSet(s1);
//删除
s1.erase(s1.begin());
printSet(s1);
//删除重载
s1.erase(30);
printSet(s1);
//清空
/*s1.erase(s1.begin(), s1.end());*/
s1.clear();
printSet(s1);
}
int main() {
test01();
system("pause");
return 0;
}
#include<iostream>
using namespace std;
#include<set>
//set容器查找和统计
void printSet(set<int>& s) {
for (set<int>::iterator it = s.begin(); it != s.end(); it++) {
cout << *it << " ";
}
cout << endl;
}
//大小
void test01() {
//查找
set<int>s1;
s1.insert(20);
s1.insert(10);
s1.insert(40);
s1.insert(30);
printSet(s1);
set<int>::iterator pos = s1.find(20);
if (pos != s1.end()) {
cout << "找到20" << endl;
}
else {
cout << "没有找到20" << endl;
}
}
//统计
void test02() {
set<int>s1;
s1.insert(20);
s1.insert(10);
s1.insert(40);
s1.insert(30);
s1.insert(30);
printSet(s1);
int num = s1.count(30);
cout << "num = " << num << endl;
//对于set而言,统计的结果0或者1
}
int main() {
test01();
test02();
system("pause");
return 0;
}
#include<iostream>
using namespace std;
#include<set>
//set容器和mutiset容器的区别
void printSet(set<int>& s) {
for (set<int>::iterator it = s.begin(); it != s.end(); it++) {
cout << *it << " ";
}
cout << endl;
}
//大小
void test01() {
set<int>s1;
pair<set<int>::iterator, bool>ret = s1.insert(20);
if (ret.second) {
cout << "插入成功" << endl;
}
else {
cout << "插入失败" << endl;
}
ret = s1.insert(20);
if (ret.second) {
cout << "插入成功" << endl;
}
else {
cout << "插入失败" << endl;
}
multiset<int>ms;
//允许插入重复值
ms.insert(10);
ms.insert(10);
for (multiset<int>::iterator it = ms.begin(); it != ms.end(); it++) {
cout << *it << " ";
}
cout << endl;
}
int main() {
test01();
system("pause");
return 0;
}
#include<iostream>
using namespace std;
#include<set>
//对组的创建
//大小
void test01() {
//第一种方式
pair<string, int>p("Tom", 20);
cout << "姓名:" << p.first << " 年龄:" << p.second << endl;
//第二种方式
pair<string, int>p2 = make_pair("Jerry", 25);
cout << "姓名:" << p2.first << " 年龄:" << p2.second << endl;
}
int main() {
test01();
system("pause");
return 0;
}
#include<iostream>
using namespace std;
#include<set>
//set容器排序
class myCompare {
public:
bool operator()(int v1, int v2) const {
return v1 > v2;
}
};
//大小
void test01() {
set<int>s1;
s1.insert(20);
s1.insert(10);
s1.insert(40);
s1.insert(30);
for (set<int>::iterator it = s1.begin(); it != s1.end(); it++) {
cout << *it << " ";
}
cout << endl;
//指定排序规则为从大到小
set<int, myCompare>s2;
s2.insert(20);
s2.insert(10);
s2.insert(40);
s2.insert(30);
s2.insert(30);
for (set<int, myCompare>::iterator it = s2.begin(); it != s2.end(); it++) {
cout << *it << " ";
}
cout << endl;
}
void test02() {
set<string>s1;
s1.insert("ABC");
s1.insert("ACB");
s1.insert("BAC");
s1.insert("BCA");
s1.insert("CAB");
s1.insert("CBA");
for (set<string>::iterator it = s1.begin(); it != s1.end(); it++) {
cout << *it << " ";
}
cout << endl;
/*
//指定排序规则为从大到小
set<int, myCompare>s2;
s2.insert(20);
s2.insert(10);
s2.insert(40);
s2.insert(30);
s2.insert(30);
for (set<int, myCompare>::iterator it = s2.begin(); it != s2.end(); it++) {
cout << *it << " ";
}
cout << endl;
*/
}
int main() {
test01();
test02();
system("pause");
return 0;
}
#include<iostream>
using namespace std;
#include<set>
//set容器排序(自定义数据类型)
//自定义的数据类型都要指定排序规则
class Person {
public:
Person(string name, int age) {
this->m_Name = name;
this->m_Age = age;
}
string m_Name;
int m_Age;
};
class myCompare {
public:
bool operator()(Person p1, Person p2) const {
return p1.m_Age < p2.m_Age;
}
};
void test01() {
set<Person,myCompare>s;
Person p1("张三", 18);
Person p2("李四", 15);
Person p3("王五", 17);
Person p4("赵六", 19);
s.insert(p1);
s.insert(p2);
s.insert(p3);
s.insert(p4);
for (set<Person>::iterator it = s.begin(); it != s.end(); it++) {
cout << "姓名:" << (*it).m_Name << " 年龄:" << (*it).m_Age << endl;
}
cout << endl;
}
int main() {
test01();
system("pause");
return 0;
}
(10)map:
#include<iostream>
using namespace std;
#include<map>
//map容器 构造和赋值
void printMap(map<int, int>& m) {
for (map<int, int>::iterator it = m.begin(); it != m.end(); it++) {
cout << "key = " << (*it).first << " value = " << it->second << endl;
}
cout << endl;
}
void test01() {
map<int, int>m;//默认构造
m.insert(pair<int, int>(2, 10));
m.insert(pair<int, int>(1, 20));
m.insert(pair<int, int>(3, 30));
m.insert(pair<int, int>(4, 40));
printMap(m);
//拷贝构造
map<int, int>m2(m);
printMap(m2);
//赋值
map<int, int>m3;
m3 = m2;
printMap(m3);
}
int main() {
test01();
system("pause");
return 0;
}
#include<iostream>
using namespace std;
#include<map>
//map容器 大小和交换
//大小
void printMap(map<int, int>& m) {
for (map<int, int>::iterator it = m.begin(); it != m.end(); it++) {
cout << "key = " << (*it).first << " value = " << it->second << endl;
}
cout << endl;
}
//大小
void test01() {
map<int, int>m;
m.insert(pair<int, int>(2, 10));
m.insert(pair<int, int>(1, 20));
m.insert(pair<int, int>(3, 30));
m.insert(pair<int, int>(3, 40));//key不能重复,插入失败
printMap(m);
if (m.empty()) {
cout << "m为空" << endl;
}
else {
cout << "m不为空" << endl;
cout << "m的大小为:" << m.size() << endl;
}
}
//交换
void test02() {
map<int, int>m;
m.insert(pair<int, int>(2, 10));
m.insert(pair<int, int>(1, 20));
m.insert(pair<int, int>(3, 30));
m.insert(pair<int, int>(3, 40));//key不能重复,插入失败
printMap(m);
map<int, int>m2;
m2.insert(pair<int, int>(2, 100));
m2.insert(pair<int, int>(1, 200));
m2.insert(pair<int, int>(3, 300));
m2.insert(pair<int, int>(4, 300));
printMap(m2);
m.swap(m2);
printMap(m);
printMap(m2);
}
int main() {
test01();
test02();
system("pause");
return 0;
}
#include<iostream>
using namespace std;
#include<map>
//map容器 插入和删除
void printMap(map<int, int>& m) {
for (map<int, int>::iterator it = m.begin(); it != m.end(); it++) {
cout << "key = " << (*it).first << " value = " << it->second << endl;
}
cout << endl;
}
void test01() {
map<int, int>m;
//插入
//第一种
m.insert(pair<int, int>(1, 10));
//第二种
m.insert(make_pair(2, 20));
//第三种
m.insert(map<int, int>::value_type(3, 30));
//第四种
m[4] = 40;
//[]不建议插入,用途:可以利用key访问value
cout << m[5] << endl;
printMap(m);
//删除
m.erase(m.begin());
printMap(m);
m.erase(3);//按照key删除
printMap(m);
//清空
//m.erase(m.begin(), m.end());
m.clear();
printMap(m);
}
int main() {
test01();
system("pause");
return 0;
}
#include<iostream>
using namespace std;
#include<map>
//map容器 查找统计
void printMap(map<int, int>& m) {
for (map<int, int>::iterator it = m.begin(); it != m.end(); it++) {
cout << "key = " << (*it).first << " value = " << it->second << endl;
}
cout << endl;
}
void test01() {
map<int, int>m;
m.insert(pair<int, int>(2, 10));
m.insert(pair<int, int>(1, 20));
m.insert(pair<int, int>(3, 30));
printMap(m);
map<int, int>::iterator pos = m.find(3);
if (pos != m.end()) {
cout << "查到了" << endl;
}
else {
cout << "没查到" << endl;
}
//统计
//map不允许插入重复key,count统计结果要么是0要么是1;multimap可以大于1
int num = m.count(3);
cout << "num = " << num << endl;
}
int main() {
test01();
system("pause");
return 0;
}
#include<iostream>
using namespace std;
#include<map>
//map容器 排序
class myCompare {
public:
bool operator()(int v1, int v2) const{
return v1 > v2;
}
};
void printMap(map<int, int,myCompare>& m) {
for (map<int, int>::iterator it = m.begin(); it != m.end(); it++) {
cout << "key = " << (*it).first << " value = " << it->second << endl;
}
cout << endl;
}
void test01() {
map<int, int, myCompare>m;
m.insert(pair<int, int>(2, 10));
m.insert(pair<int, int>(1, 20));
m.insert(pair<int, int>(3, 30));
m.insert(pair<int, int>(5, 50));
printMap(m);
map<int, int>::iterator pos = m.find(3);
if (pos != m.end()) {
cout << "查到了" << endl;
}
else {
cout << "没查到" << endl;
}
//统计
//map不允许插入重复key,count统计结果要么是0要么是1;multimap可以大于1
int num = m.count(3);
cout << "num = " << num << endl;
}
int main() {
test01();
system("pause");
return 0;
}
3.单/双向链表的翻转
(1)单项链表的翻转
需要三个指针:cur(指向当前正在操作的节点)、pre(指向当前节点的前一个节点)和next(指向当前节点的后一个节点)。pre的作用是记录当前节点反向后要指向谁;next的作用是防止当前节点转向后链表断开(以防找不到下一个节点)
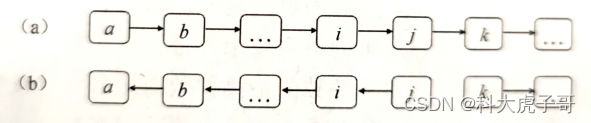
代码实现:
Node* reverseSingleList(Node* head) {
Node* pre = nullptr;
Node* cur = head;
while (cur != nullptr) {
Node* next = cur->next;
cur->next = pre;
pre = cur;
cur = next;
}
return pre;
}
(2)双向链表的翻转
双向链表的翻转和单向链表的翻转思路一样,只需要多一步操作:
Node* reverseDoubleList(Node* head) {
Node* pre = nullptr;
Node* cur = head;
while (cur != nullptr) {
Node* next = cur->next;
cur->next = pre;
cur->pre = next;//单/双向链表的翻转只有这一步的差异
pre = cur;
cur = next;
}
return pre;
}
4.打印两个有序链表的公共部分

解:双指针分别指向两个链表的头部,然后谁小谁移动(假设链表是从小到大排列);相等则打印输出,并且一块移动;直到有一个链表结束

void printCommonListPart(Node* head1,Node* head2) {
while (head1 != nullptr && head2 != nullptr) {
if (head1->val > head2->val) {
head2 = head2->next;
}else if (head1->val < head2->val) {
head1 = head1->next;
}else {
cout << head1->val << " ";
head1 = head1->next;
head2 = head2->next;
}
}
cout << endl;
}
5.链表解题的方法论

笔试只要通过就行,在不考虑空间复杂的情况下往往很容易实现;面试链表类题目考察的是代码能力,因此要在时间复杂度小的情况下取优化空间复杂度,给面试官留下好的印象
6.判断一个链表是否为回文结构

解:
(1)笔试:将链表存储在一个栈里,每次从栈里弹出一个元素与链表顺序比较,由于栈是先入后出,所以相当于将链表的前后做了比较
代码实现:
bool isPalindrmeList01(Node* head) {
stack<Node*>sk;
Node* p = head;
while (p != nullptr) {
sk.push(p);
p = p->next;
}
while (head != nullptr) {
if (head->val != sk.top()->val) {
return false;
}
head = head->next;
sk.pop();
}
return true;
}
–>优化:用快慢指针只将链表的后半段存储在栈中,也能达到相同的效果。注意快慢指针可能要根据链表中节点的奇偶性进行定制(边界条件)
代码实现:
bool isPalindrmeList02(Node* head) {
stack<Node*>sk;
Node* p1 = head;
Node* p2 = head;
while (p2 != nullptr && p2->next != nullptr) {
p1 = p1->next;
p2 = p2->next->next;
}
while (p1 != nullptr) {
sk.push(p1);
p1 = p1->next;
}
while (!sk.empty()) {
if (head->val != sk.top()->val) {
return false;
}
head = head->next;
sk.pop();
}
return true;
}
(2)面试:利用双指针将链表的后半段逆序,然后再用双指针从两端开始遍历比较,最后记得将逆序的半段链表还原
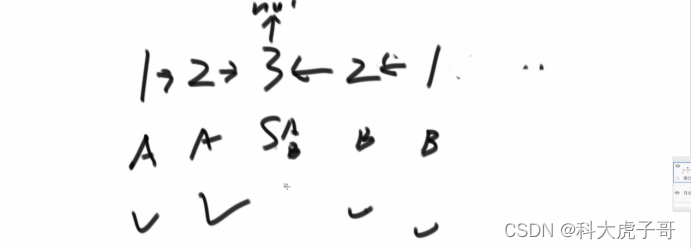
代码实现:
bool isPalindrmeList03(Node* head) {
Node* p1 = head;
Node* p2 = head;
while (p2 != nullptr && p2->next != nullptr) {
p1 = p1->next;
p2 = p2->next->next;
}
Node* cur = p1;
Node* pre = nullptr;
while (cur != nullptr) {
Node* next = cur->next;
cur->next = pre;
pre = cur;
cur = next;
}
p1 = head;
p2 = pre;
bool flag = true;
while (p2 != nullptr) {
if (p1->val != p2->val) {
flag = false;
break;
}
p1 = p1->next;
p2 = p2->next;
}
//恢复链表
cur = pre;
pre = nullptr;
while (cur != nullptr) {
Node* next = cur->next;
cur->next = pre;
pre = cur;
cur = next;
}
return flag;
}
7.将单向链表按某值划分成左边小、中间相等、右边大的形式

解:
(1)笔试:将单链表中的元素放到一个数组中,在数组中用快排的partition,最后在将数组元素放回到单链表中
代码实现:
Node* arrPartition01(Node* head, int povit) {
vector<int>arr;
Node* p = head;
while (p != nullptr) {
arr.push_back(p->val);
p = p->next;
}
partition(arr, povit);
p = head;
int i = 0;
while (p != nullptr) {
p->val = arr[i];
p = p->next;
i++;
}
return head;
}
(2)面试:申请六个变量:小于给定值的头、尾,等于给定值的头、尾,大于给定值的头、尾;然后遍历一遍链表,将各个节点插入到相应的区域;最后将小于区域、等于区域和大于区域首尾依次相连。注意:三个区域均有可能为空,在相连的时候一定要讨论清楚边界!
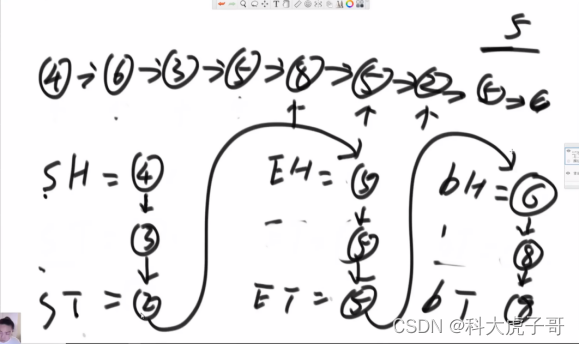
代码实现:
Node* listPartition02(Node* head, int povit) {
Node* sh = nullptr;
Node* st = nullptr;
Node* eh = nullptr;
Node* et = nullptr;
Node* bh = nullptr;
Node* bt = nullptr;
while (head != nullptr) {
if (head->val < povit) {
if (sh == nullptr) {
sh = head;
st = head;
}else {
st->next = head;
st = head;
}
}else if (head->val > povit) {
if (bh == nullptr) {
bh = head;
bt = head;
}
else {
bt->next = head;
bt = head;
}
}else {
if (eh == nullptr) {
eh = head;
et = head;
}
else {
et->next = head;
et = head;
}
}
head = head->next;
}
//三个区域相连接:左神的思路不好想,这里使用笨方法
if (sh != nullptr) {
if (eh != nullptr) {
if (bh != nullptr) {
st->next = eh;
et->next = bh;
bt->next = nullptr;
}else {
st->next = eh;
et->next = nullptr;
}
}else {
if (bh != nullptr) {
st->next = bh;
bt->next = nullptr;
}else {
st->next = nullptr;
}
}
return sh;
}else {
if (eh != nullptr) {
if (bh != nullptr) {
et->next = bh;
bt->next = nullptr;
}else {
et->next = nullptr;
}
return eh;
}else {
if (bh != nullptr) {
bt->next = nullptr;
}else {
//三者都为空
}
return bh;
}
}
return nullptr;
}
8.复制含有随机指针节点的链表

(1)笔试:用hashmap:key:老节点;value:copy的新节点;遍历链表,根据对应的节点设置新的节点
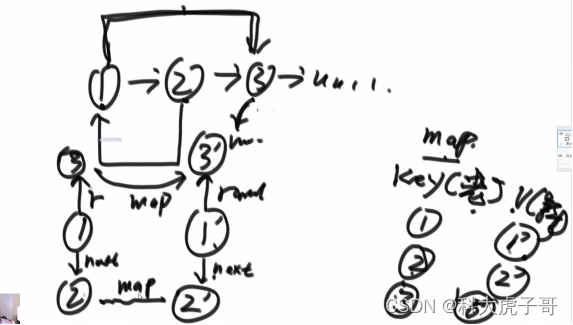
代码实现:
Node* copyListWithRand01(Node* head) {
unordered_map<Node*, Node*>mp;
Node* p = head;
while (p != nullptr) {
Node* newNode = new Node(p->val);
mp.insert({ p,newNode });
p = p->next;
}
p = head;
while (p != nullptr) {
mp[p]->next = mp[p->next];
mp[p]->rand = mp[p->rand];
p = p->next;
}
return mp[head];
}
(2)面试:将copy的节点放到老节点的后面;然后一对一对的遍历新链表,根据老节点的rand指针找到新节点的rand指针;最后在next方向上将新老链表分离。利用copy节点放的位置关系代替了hashmap中的对组关系
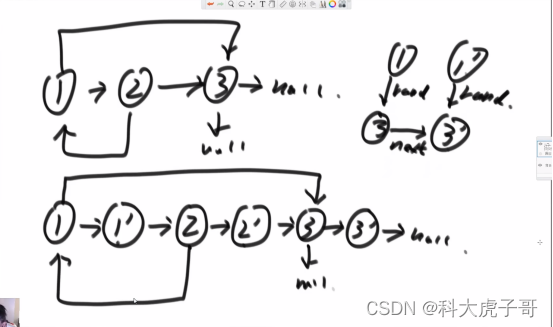
代码实现:
Node* copyListWithRand02(Node* head) {
if (head == nullptr) {
return nullptr;
}
Node* p = head;
while (p != nullptr) {
Node* newNode = new Node(p->val);
Node* next = p->next;
p->next = newNode;
newNode->next = next;
p = p->next->next;
}
p = head;
while (p != nullptr) {
if (p->rand != nullptr) {
p->next->rand = p->rand->next;
}
p = p->next->next;
}
p = head;
Node* newHead = head->next;
Node* p2 = nullptr;
while (p->next->next!=nullptr) {
p2 = p->next;
p->next = p->next->next;
p2->next = p2->next->next;
p = p->next;
}
p->next = nullptr;
return newHead;
}
9.两个单链表相交的一系列问题

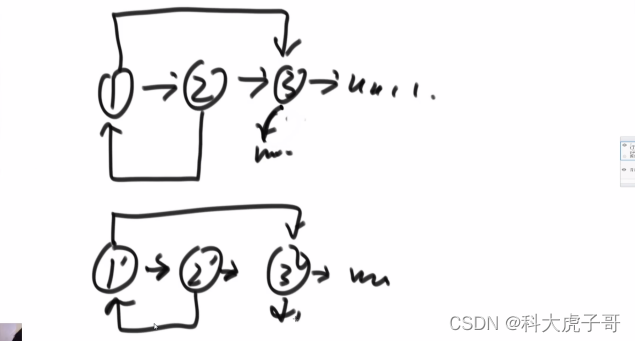
解:首先判断两链表是否有环;然后分两个都没环和两个都有环讨论(一个有环、一个没环不可能相交),两个都有环又可以分为交点在环前和交点在环上两种情况
注:两个链表相交,后面的节点必定全部相同,相交之后不可能再有分岔,因为一个节点只可能有一个next指针,因此好多脑补的结构是不存在的
(1)如何判断链表有没有环?有环一定走不到nullptr
1)笔试:用一个hashset将所有节点放到set中,放之前先检查set中是否已经存在当前节点,如果存在,则当前节点就是入环节点
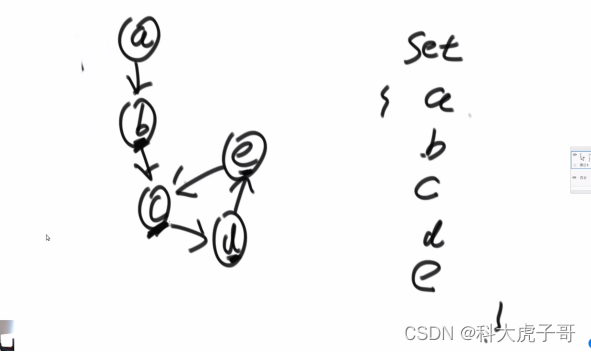
实现代码:
Node* isLoop01(Node* head) {//笔试写法
unordered_set<Node*>st;
Node* p = head;
while (p != nullptr) {
if (st.find(p)== st.end()) {
st.insert(p);
}else {
return p;
}
p = p->next;
}
return nullptr;
}
2)面试:使用快慢指针f、s,快指针每次走两步,慢指针每次走一步,当f和s相遇时(假设存在环,否则f可以走到nullptr),f走了2k步,s走了k步,并且f超s环的整数倍步(因为相遇了,且环之前的步数相同)。假设环之前的节点数为a,环内(包括入口)节点数为b即:
f=2k
s=k
f-s=k=n*b
那么让s再走a步则必定来到环的入口节点,因此可以将f放回起始节点,然后每次让f和s都只走一步,当再次相遇时所在节点即为环的入口节点。
注:起始节点可以是链表的头节点,也可以是头节点的前一个节点(假设存在),但f再次回到起始节点的位置要和第一次的保持一致。
代码实现:
Node* isLoop02(Node* head) {//面试:快慢指针
if (head == nullptr) {//后面用到了head->next,所以要先保证head不能为空指针
return nullptr;
}
Node* f = head->next;
Node* s = head;
while (f != nullptr && f->next != nullptr && f != s) {
f = f->next->next;
s = s->next;
}
if (f == s) {
f = head;
s = s->next;
while (f != s) {
f = f->next;
s = s->next;
}
return f;
}
return nullptr;
}
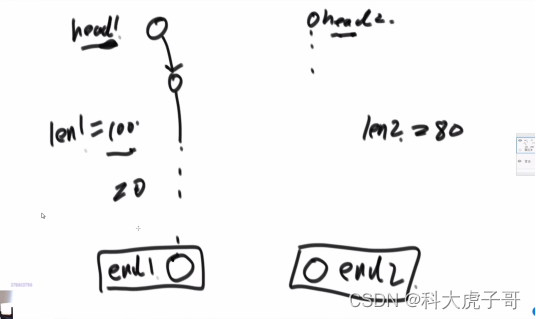
(2)两个都没环的链表是否相交?相交如何求第一个交点?
若两个无环的链表相交,则相交之后的部分必定全部重合,即最后一个节点必定一样,因此可以分别遍历两个链表至最后一个节点,通过比较是否相同,来判断是否相交。
如果相交如何求交点?可以在上面遍历时分别求出两链表的长度,用双指针分别指向两链表,让长链表的指针先走长度差值步,任何在让两指针同步移动,当两指针相等时所指向的节点即为第一个交点
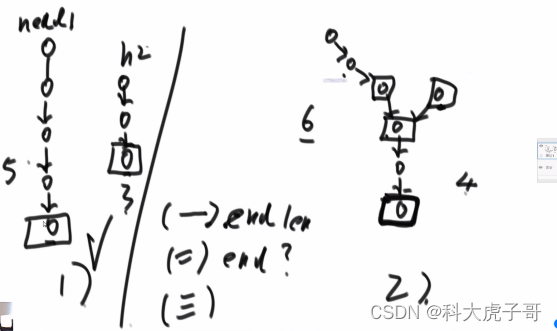
代码实现:
Node* noLoopIntersection(Node* head1,Node* head2) {
if (head1 == nullptr || head2 == nullptr) {
return nullptr;
}
Node* p1 = head1;
Node* p2 = head2;
int len1 = 1, len2 = 1;
while (p1->next != nullptr) {
len1++;
p1 = p1->next;
}
while (p2->next != nullptr) {
len2++;
p2 = p2->next;
}
if (p1 != p2) {
return nullptr;
}
p1 = len1 > len2 ? head1 : head2;
p2 = len1 > len2 ? head2 : head1;
for (int i = 0; i < abs(len1 - len2); i++) {
p1 = p1->next;
}
while (p1 != p2) {
p1 = p1->next;
p2 = p2->next;
}
return p1;
}
(3)两个都有环的链表是否相交?如何求第一个交点?
若相交,存在两种相交的情况:在环之前相交和在环中相交。第二种情况:在环前相交(根据入环节点是否相同判断)等效于两个无环链表相交的问题,只不过终止节点不再是空指针,而是入环节点(通过上面的分析,入环节点已经求出);第一种情况和第二种情况判断:让其中一个链表经过入环节点后继续走直到回到入环节点,如果在这个过程中和另一个链表的入环节点相遇,则是情况三(返回哪个入环节点都对);否则是情况一。
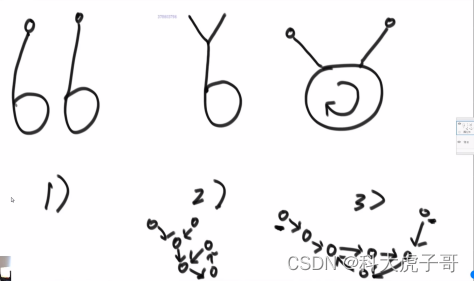
代码实现:
Node* douleLoopIntersection(Node* head1, Node* loop1, Node* head2, Node* loop2) {
Node* p1 = head1;
Node* p2 = head2;
if (loop1 == loop2) {
int len1 = 1;
int len2 = 1;
while (p1 != loop1) {
len1++;
p1 = p1->next;
}
len1++;
while (p2 != loop2) {
len2++;
p2 = p2->next;
}
len2++;
p1 = len1 > len2 ? head1 : head2;
p2 = len1 > len2 ? head2 : head1;
for (int i = 0; i < abs(len1 - len2); i++) {
p1 = p1->next;
}
while (p1 != p2) {
p1 = p1->next;
p2 = p2->next;
}
return p1;
}
p1 = loop1->next;
p2 = loop2;
while (p1 != loop1) {
if (p1 == p2) {
return loop1;//return loop2也对
}
p1 = p1->next;
}
return nullptr;
}
主函数代码实现:
Node* getIntersectionNode(Node* head1, Node* head2) {
if (head1 == nullptr || head2 == nullptr) {
return nullptr;
}
Node* loop1 = isLoop02(head1);
Node* loop2 = isLoop02(head2);
if (loop1 == nullptr && loop2 == nullptr) {
return noLoopIntersection(head1, head2);
}
if (loop1 != nullptr && loop2 != nullptr) {
return douleLoopIntersection(head1, loop1, head2, loop2);
}
return nullptr;
}

















 781
781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









