







 损失函数是衡量模型预测值与真实值之间差距的指标,其大小影响模型的鲁棒性。常见的损失函数包括绝对值损失、平方损失、0-1损失、对数损失、指数损失和铰链损失,分别应用于不同的问题,如回归、分类等。损失函数的选择受异常值、算法选择、梯度下降复杂度等因素制约,不存在适用于所有情况的通用损失函数。
损失函数是衡量模型预测值与真实值之间差距的指标,其大小影响模型的鲁棒性。常见的损失函数包括绝对值损失、平方损失、0-1损失、对数损失、指数损失和铰链损失,分别应用于不同的问题,如回归、分类等。损失函数的选择受异常值、算法选择、梯度下降复杂度等因素制约,不存在适用于所有情况的通用损失函数。
损失函数(Loss Function):
1. 定义:
如下是几种关于损失函数的定义:
用来表现预测与实际数据的差距程度
用来估计模型的预测值f(x)与真实值Y的不一致程度,是一个非负实值函数,通常用L(Y,f(x))来表示。损失函数越小,模型的鲁棒性(robustness:抗变换性)越好
机器学习中所有算法都需要最大化或者最小化一个函数(目标函数)。所以一般就把最小化的一类函数,称为“损失函数”。能根据预测结果,衡量出模型预测能力的好坏。
比如你做一个线性回归,实际值和你的预测值肯定会有误差,那么我们可以找到一个函数表示这个误差就是损失函数;所以其实在线性回归中的最小二乘法便可以看成是一个损失函数,损失函数受到多种因素制约,而且几乎不存在一个适合所有模型的损失函数,所以针对不同模型就会有不同的损失函数。
2. 损失函数结构:
损失函数是经验风险函数的核心部分,也是结构风险函数的重要组成部分。
模型的结构风险函数包括经验风险项和正则项。如下
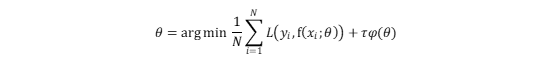
其中,前面的均值函数表示经验风险函数,L代表的是损失函数;后面的是正则化项(regularizer)或者叫做惩罚项(penalty
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









