






 本文深入探讨了栈这种特殊线性表的结构与操作,包括入栈、出栈、判断空栈等基本功能,以及顺序栈和链栈的实现方式。通过对比两种栈的优缺点,介绍了栈在中缀表达式求值、转换为后缀表达式以及后缀表达式求值中的应用。
本文深入探讨了栈这种特殊线性表的结构与操作,包括入栈、出栈、判断空栈等基本功能,以及顺序栈和链栈的实现方式。通过对比两种栈的优缺点,介绍了栈在中缀表达式求值、转换为后缀表达式以及后缀表达式求值中的应用。
栈
栈—是一种特殊的线性表
栈(stack)又名堆栈,它是一种运算受限的线性表。限定仅在表尾进行插入和删除操作的线性表。这一端被称为栈顶,相对地,把另一端称为栈底。向一个栈插入新元素又称作进栈、入栈或压栈,它是把新元素放到栈顶元素的上面,使之成为新的栈顶元素;从一个栈删除元素又称作出栈或退栈,它是把栈顶元素删除掉,使其相邻的元素成为新的栈顶元素。
栈的特殊之处在于:仅在表尾进行插入和删除操作的线性表。也就是先进后出,只有后入的数据出栈,之前的数据才能出栈。
空栈:不含任何数据元素的栈。
允许插入和删除的一端称为栈顶,另一端称为栈底。
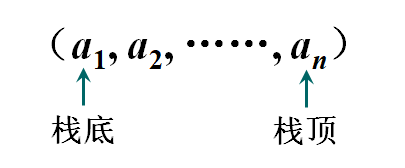
需要搞清楚的是:栈只是对表插入和删除操作的位置进行了限制,并没有限定插入和删除操作进行的时间。
对于栈的实现:首先是自己定义的栈:
1.顺序栈—栈的顺序存储结构
不同的函数:
①入栈:
void Push( T x )
template <class T>
void seqStack<T>::Push ( T x)
{
if (top==MAX_SIZE-1) throw “溢出”;
top++;
data[top]=x;
}
②判断是否是空栈:
bool Empty( )
template <class T>
bool seqStack<T>::Empty ()
{
if (top==-1)
return true;
return false;
}
③取栈顶
T GetTop( )
template <class T>
T seqStack<T>::GetTop ( )
{
if (Empty()) throw ”空栈” ;
return data[top];
}
④出栈
T Pop( )
template <class T>
T seqStack<T>:: Pop ( )
{
if (top==-1) throw “溢出”;
x=data[top];
top--;
return x;
}
顺序栈还可以一个数组来储存两个栈,两栈共享空间:使用一个数组来存储两个栈,让一个栈的栈底为该数组的始端,另一个栈的栈底为该数组的末端,两个栈从各自的端点向中间延伸。
栈1的底固定在下标为0的一端;栈2的底固定在下标为StackSize-1的一端。top1和top2分别为栈1和栈2的栈顶指针;
Stack_Size为整个数组空间的大小;
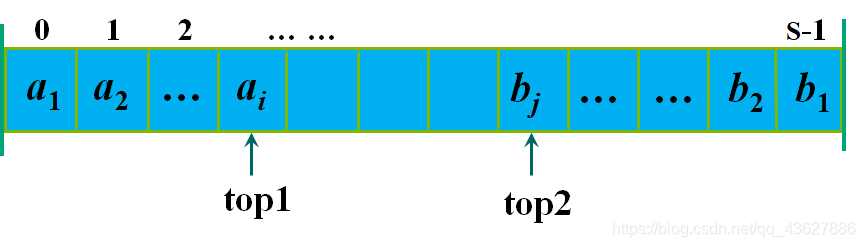
当top1= -1的时候栈1为空,当top2= Stack_Size栈2为空,当top1+1=top2时栈满。
2.栈之链式存储
通常将将链头作为栈顶,方便操作,利用头插法,并在再进行出栈的时候,秩序便利一个数据。且链栈不需要附设头结点。

①入栈:
void Push(T x)
template <class T>
void LinkStack<T>::Push(T x)
{
s=new Node<T>;
s->data=x;
s->next=top;
top=s;
}
②出栈:
T Pop( )
template <class T>
T LinkStack<T>::Pop( )
{
if (top==NULL)
throw "下溢";
x=top->data;
p=top;
top=top->next;
delete p;
return x;
}
③析构
template <class T>
LinkStack<T>::~LinkStack( )
{
while (top)
{
Node<T> *p;
p=top->next;
delete top;
top=p;
}
}
顺序栈和链栈的比较
时间性能:相同,都是常数时间O(1)
空间性能:
顺序栈:有元素个数的限制和空间浪费的问题。
链栈:没有栈满的问题,只有当内存没有可用空间时才会出现栈满,但是每个元素都需要一个指针域,从而产生了结构性开销。 结论:当栈的使用过程中元素个数变化较大时,用链栈是适宜的,反之,应该采用顺序栈。
对于栈的一些应用
中缀表达式求值
中缀表达式转化为后缀表达式
后缀表达式求值
后缀表达式求值——
从左到右对后缀表达式字符串进行处理,每次处理一个符号
若遇到数字,入栈
若遇到运算符,栈顶两个数字出栈,执行运算符所定义的运算,并将运算结果入栈
重复以上的工作,直到表达式结束,此时,栈中的数字代表最终的值。
中缀表达式求值过程
设置两个栈:
OVS(运算数栈)和OPTR(运算符栈)。
自左向右扫描中缀表达式,
遇操作数进OVS,
遇操作符则与OPTR栈顶优先数比较:
OPTR栈顶<当前操作符, 当前操作符进OPTR栈
OPTR栈顶>=当前操作符,OVS栈顶、次顶和OPTR栈顶,退栈形成运算T(i),T(i)进OVS栈。
中缀表达式转化为后缀表达式——
设置一个运算符栈。从左到右依次对中缀表达式中的每个符号进行处理
如果遇到数字,直接输出
如果遇到“(”,则将其入栈
如果遇到运算符a,如果栈顶符号的优先级低于a的优先级,则入栈;否则,栈顶符号出栈,直到栈顶符号的优先级低于a的优先级,此时让a入栈
若遇到“)”,则栈顶符号出栈,直到“(”
重复以上工作,直到表达式结束,此时,将栈里符号全部出栈。
二.STL的栈
对于自己写的栈再进行操作时难免会出现或遇到一些问题,所以运用C++ Stack(堆栈)它 是一个容器类的改编,为程序员提供了堆栈的全部功能,——也就是说实现了一个先进后出(FILO)的数据结构。
c++ STL栈stack的头文件为: #include
c++ STL栈stack的成员函数介绍
操作 比较和分配堆栈
empty() 堆栈为空则返回真
pop() 移除栈顶元素
push() 在栈顶增加元素
top() 返回栈顶元素
在学习栈后对线性表的理解更加深刻和透彻,再次回顾线性表的问题是也没有之前写代码时的迷茫,对于顺序结构和链式结构都有了更深刻的了解,栈作为一种特殊的线性表,可以解决许多的问题,有括号匹配,火车等问题。

















 5764
5764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









