










在计算病理学领域,全切片图像(WSI)因其超高分辨率和复杂性,给自动化诊断技术带来了巨大的挑战。传统方法依赖精确标注的训练数据,面对标注困难、数据稀缺的小样本任务往往表现受限。CVPR 2023的一篇论文提出了一种新的框架 MI-Zero,通过结合视觉语言模型与多实例学习(MIL),实现了病理学领域的零样本(Zero-shot)分类,展现出极大的应用潜力。
1. 背景
全景切片图像通常具有高达 100,000 × 100,000 像素的分辨率,图像包含多种组织和细胞类型,局部区域可能展现复杂的病理特征,标注复杂且样本量有限。
传统的监督学习方法依赖区域级或图像级的标注,且无法精确定位病灶区域。许多罕见肿瘤类型因样本数量不足,无法训练高性能的监督学习模型。因此,传统方法面临着数据匮乏与计算资源瓶颈的问题。
视觉-语言模型(如 CLIP、ALIGN)已证明其在自然图像分类上的零样本迁移(Zero-shot transfer)能力,但这些技术尚未被充分探索应用于病理图像,原因在于:
- 缺乏大规模的图像-文本配对数据集。
- 全切片图像的超高分辨率和异质性,增加了模型处理的难度。
为此,MI-Zero 提出了一个多实例学习框架,以利用预训练模型在病理学领域执行零样本任务。
Zero-shot Transfer(零样本迁移)指的是一个模型在没有见过目标任务的任何标注数据的情况下,直接通过学习到的知识(即预训练一个通用性强的模型)完成该任务。这个能力依赖于模型在预训练阶段所学到的通用知识和语义关系,可以通过灵活的方式将其迁移到新的场景或任务中。
- 预训练:模型通常在一个大规模的通用数据集上进行预训练。比如 CLIP 模型预训练时使用了包含数亿对图片和文本描述的对比数据。目标是学习到一个共享的嵌入空间,使图片和文本能够在这个空间中相互对齐。
任务迁移(Transfer):在零样本任务中,不需要额外的训练,而是通过一些灵活的机制(如文本描述)将任务提示传递给模型。比如,在猫狗图像分类中,通过文本描述(如“这是一张显示猫的图片”,“这是一张显示狗的图片”)告诉模型需要识别的类别信息,模型基于输入的图片和任务提示(文本描述)利用预训练时学到的语义关系和对齐知识进行推理,输出预测结果(“猫”或“狗”)。
2. MI-Zero 方法
2.1 数据集的构建
论文中构建了一个包含 33,480 个病理学图像-文本对的数据集,这是目前已知规模最大的此类数据集,主要来源包括:病理学公开教育资源,ARCH 数据集,Massachusetts General Hospital 的病理报告。
数据预处理采用正则化表达式对病理报告进行去标识化,并基于 Byte Pair Encoding(BPE)技术训练了自定义分词器,最终形成领域特定的文本嵌入模型 HistPathGPT。
- 去标识化:病理报告中可能包含患者的隐私信息(例如姓名、年龄、地址、病历号等),为了满足数据隐私要求,必须在训练模型之前对这些信息进行脱敏处理。使用 正则化表达式 来实现去标识化,通过定义匹配规则,精确识别敏感信息位置并将其删除或替换。这样既能保留报告的诊断信息,又能满足数据隐私的要求。假设一份病理报告包含如下信息:
患者姓名:张三,出生日期:1980年05月15日 诊断结果:乳腺癌匹配到
患者姓名:张三,将其替换为患者姓名:[已脱敏]。匹配到1980年05月15日,将其替换为[已脱敏]。处理后的文本如下:患者姓名:[已脱敏],出生日期:[已脱敏] 诊断结果:乳腺癌 -
Byte Pair Encoding(BPE)技术训练自定义分词器:分词是自然语言处理中的关键步骤,它将文本分解为更小的单位(如单词或子词),以便后续建模。通用分词器可能无法很好地处理病理学领域的专业术语(如“adenocarcinoma”或“lymphocyte”),这会降低模型对领域文本的理解能力。因此,论文使用 BPE 技术在病理学数据上训练了一个自定义分词器:
-
从病理报告和医学文献中获取领域数据,作为训练分词器的语料。
-
使用 BPE 在病理学文本上生成子词词表,确保领域内常用术语能够被分解为合适的子词单元。它的核心思想是:
-
从单字符开始:将每个单词分成单个字符。假设文本为 "adenocarcinoma cancer",每个单词拆分成单个字符 "a d e n o c a r c i n o m a c a n c e r"。
-
频率最高的字符对合并:计算相邻字符对的出现频率:
('a', 'd'): 1, ('d', 'e'): 1, ('e', 'n'): 1, ...每次合并频率最高的字符对,逐步形成更大的子词单元,假设 ('a', 'd') 出现频率最高,则将其合并:"ad e n o c a r c i n o m a c a n c e r"。
-
反复执行上述操作:直到达到指定的词表大小或没有可合并的字符对,如最终分解得到子词序列:adeno,carcinoma,cancer
-
-
- 文本嵌入模型 HistPathGPT:分词后的文本(子词序列)需要进一步通过模型转换为嵌入向量,以便与图像特征对齐。HistPathGPT 使用了 GPT2-medium 的自回归 Transformer 架构,是一个专为病理学领域设计的文本嵌入模型,能够有效捕捉病理报告中的语义信息。将病理文本子词序列输入到 HistPathGPT 中,输出高质量的文本嵌入。
MI-Zero 是一种结合视觉语言模型与多实例学习的框架,核心思想是将全切片图像分割为多个小块(patch),通过对比学习实现图像和文本特征的对齐,并通过无监督的聚合方法完成分类。
2.2 模型训练:双向对齐视觉与语言嵌入
-
预训练的图像编码器:MI-Zero 需要在图像数据集上预训练一个图像编码器(如 CTransPath)。预训练通常采用 自监督学习(SSL),无需显式标签。CTransPath 专为病理学领域设计,通过大规模无标注的病理图像提取通用视觉特征。
-
预训练的文本编码器:文本编码器会在与病理学相关的文本上预训练(如病理报告或 PubMed 摘要)。预训练目标是让文本编码器对领域特定的语言(如病理学术语)具备更强的语义理解能力。
有了预训练编码器之后,论文采用对比学习方法,通过温度缩放的交叉熵损失函数(详细讲解见文章Temperature-scaled cross-entropy loss,温度缩放的交叉熵损失)对视觉和语言嵌入进行对齐。为了确保图像和文本之间的相似度计算是双向对称的,也就是让图像能够与正确的文本匹配,同时让文本也能与正确的图像匹配。其核心公式如下:
图像到文本的对比损失:
文本到图像的对比损失:
其中, 和
分别表示图像和文本的嵌入;
是温度参数,用于调整对比学习的敏感性;
是参与损失计算的图像-文本对数量。
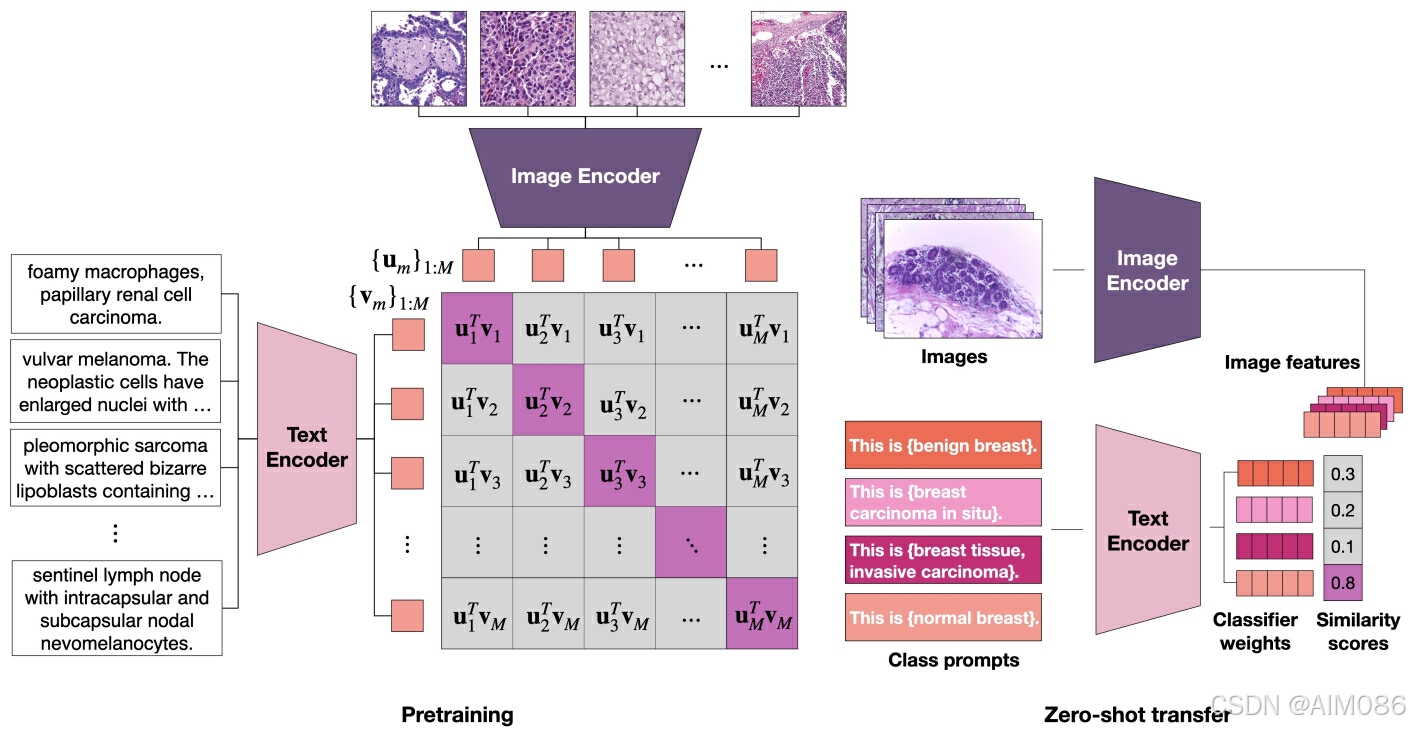
图像-文本对齐的具体操作:
由于 全切片图像(WSI)的超大规模图像特性,直接对整张图像进行嵌入计算是不现实的。论文提出通过切分图像为小块(patch),并聚合其特征的方式来完成分类。
-
切分与编码:将每张全切片图像(WSI)切分为多个 patch,每个 patch 单独通过图像编码器生成特征向量。
-
类别标签模板化:将类别标签(如“腺癌”)通过模板生成自然语言描述(如“这是一张展示腺癌的图像”)。这种模板化提供上下文信息,帮助文本编码器生成更准确的文本嵌入。
-
相似度计算:对每个 patch 特征与所有类别标签文本特征计算相似度分数。通过聚合操作(均值池化(适合整体信息分布均匀的情况) 或 Top-K 池化(选取最具代表性的 K 个 patch,对其分数进行聚合,更适用于含关键区域的病理图像)),得到全切片图像的整体相似度分数。
-
对比学习:通过对比学习对齐图像和文本的特征空间。通过对比损失优化,最小化图像与不相关文本描述的相似度,最大化图像与正确文本描述的相似度。
2.3 推理:多实例学习框架
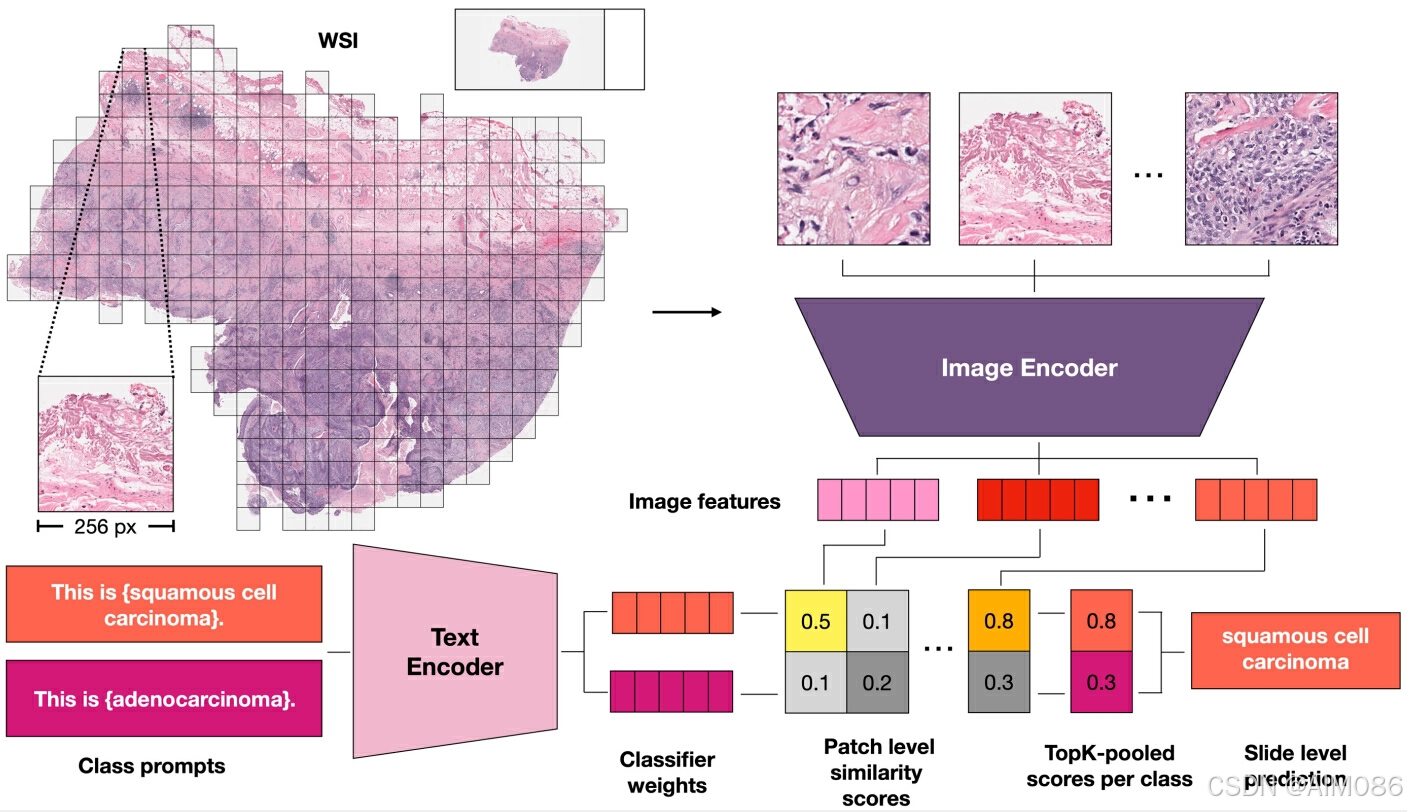
在推理阶段,依赖于对齐的特征空间,直接使用模板生成的文本描述实现图像分类,表现出零样本迁移能力。输入新的全切片图像,将其切分为多个 patch,每个 patch 的特征向量与所有类别标签的文本特征进行相似度计算,和训练阶段的流程一致。聚合所有 patch 的相似度分数,得到全切片图像的整体相似度分数。最终根据相似度最高的类别分数,预测图像的分类结果。
分块嵌入计算
每个全切片图像(WSI)被切分为 个
像素的 patch 实例,计算每个 patch 实例的嵌入
,并基于文本嵌入
计算相关性得分:
特征聚合方法
-
均值聚合(Mean Pooling):
-
TopK 聚合:
其中,
表示属于类别
的前 个最大得分。
-
图聚合(Graph-Based Pooling): 考虑实例间的空间关系,构建邻近图,采用均值滤波对实例得分进行平滑处理后再聚合。
3. 实验与结果
3.1 数据集与任务
论文在三个癌症亚型分类任务上验证了 MI-Zero 的效果:
- 乳腺癌(BRCA):IDC vs. ILC
- 非小细胞肺癌(NSCLC):LUAD vs. LUSC
- 肾细胞癌(RCC):CHRCC vs. CCRCC vs. PRCC
与弱监督方法(如 ABMIL)相比,MI-Zero 的零样本性能在多个任务上接近甚至超过了仅用 1% 数据训练的监督模型。
3.2 核心发现
-
预训练对性能的重要性:使用自监督学习预训练的 CTP 图像编码器效果显著优于随机初始化或 ImageNet 预训练。在领域特定文本上训练的 HistPathGPT 也表现优异。
-
TopK 聚合优于均值聚合:TopK 聚合能更好地捕捉关键区域信息,尤其是在异质性较强的图像中。
-
对比学习模型效果验证:与通用的 CLIP 模型相比,MI-Zero 明显更适应病理图像任务。
4. 总结
MI-Zero 为病理图像分析领域提供了一种高效的零样本解决方案,其核心亮点在于利用对比视觉语言预训练和多实例学习策略,应对了 WSIs 的高分辨率与标注稀缺问题。然而,该方法的性能仍受限于图像-文本对数据的质量与规模。
未来方向可能包括:
- 扩展更大规模的高质量病理图像-文本对数据集。
- 探索更有效的聚合策略,进一步提升对异质性区域的识别能力。
- 将此方法推广至其他高分辨率影像领域,如卫星图像和遥感图像分析。

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









