







强化学习是通过让智能体(Agent)不断地对所处环境(Environment)进行探索和开发并根据反馈的回报(Reward)进行的一种经验学习。其中智能体是我们要学习的对象,环境则是对智能体的一种外在的约束,智能体可以在这个环境内进行探索和开发,而回报则是环境对智能体最直接的反馈。
智能体会根据现有的经验做出决策动作,这个经验可能是保守型的(只选择可能累积价值最大的动作,称之为开发),也可能是探索型的(随机选择一个未知的动作,称之为探索)
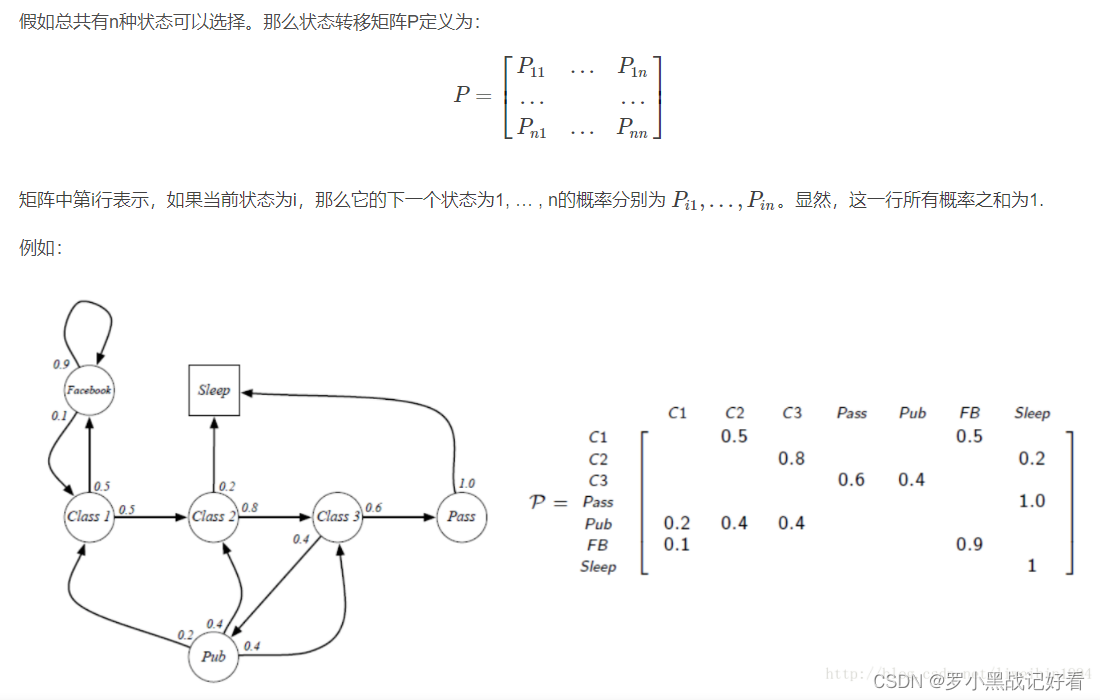
优快云强化学习系列1 概述
开发对于最大化当前时刻期望收益是正确的做法,而探索则是从长远角度讲可能带来最大化总收益。然而不幸的是,在某一个状态下,智能体只能执行一个动作,要么开发,要么探索,二者无法同时进行,因此这就是强化学习重点突出的矛盾——权衡开发与探索。
下面介绍两个用于权衡开发与探索的策略——ϵ−贪心和UCB(最大置信度上界)
ϵ−贪心【收益大的概率高,没试过的概率小,但有可能试到】
这个说得清楚 90%选高收益,10%随机选(随机选是包含高收益的那个选项的)
UCB方法【哪个选择还不够清楚的>哪个选择收益最大的>已知哪个选择不划算】【适用于静态分布,下棋那种太复杂了试不出置信度】
我们以10-臂赌博机例子,当首先开始进行动作选择时,由于初始化的置信度都为0,因此是随机选择一个动作(拉杆),并获得相关的收益,第二次进行动作选择时,由于之前的动作已经被选择一次,其不确定性降低,不会被选择,智能体将会从剩下的9个动作中选择,直到第10次,所有动作都被选择一遍。因此这10次选择基本以探索为主,同样也获得了一个全局最优。从第11次开始,由于每个动作都被执行至少一次,此时不确定性的值大家都一样,而收益不一样,因此偏向于开发(以为此时动作的选择取决于谁的动作价值大),但是当执行几次之后,有的动作被多次选择,其不确定性反倒下降,【感到工作开始变得索然无味,于是】其他的动作也会相应被再次选择。经过一次次的迭代,每个动作的置信区间都会得到收敛,从而实现对所有动作的一个遍历,平衡了开发与探索。
优快云强化学习系列2 ε-greedy &UCB
强化学习的目标是什么?总的来说是最大化累计收益,但具体累计收益是什么?本节将引入两个重要的概念,分别是状态价值和动作价值。状态价值(亦称为状态价值函数 ),其是衡量智能体处于当前状态有多好,是智能体在当前状态下,采取所有动作后得到的回报的期望值。动作价值(亦称动作价值函数或Q函数 ),是衡量在当前状态下执行某个动作后,能够得到的价值的期望。π 是一个策略,准确的来说是一个概率分布,即其保存一个概率分布,保存着在每个状态下,采取某一个动作的概率。因此在有限马尔科夫决策过程中,给定一个已知的π 分布,则对应的两个价值函数则可以求解出。
优快云强化学习系列3 有限马尔可夫决策与贝尔曼方程【讲得很好 但看不懂】
【补充学习】强化学习中马尔科夫决策过程和贝尔曼方程
Markov的定义则是忽略掉历史信息,只保留了当前状态的信息来预测下一个状态。【卡尔曼滤波的特性也是只需要知道前两个状态】


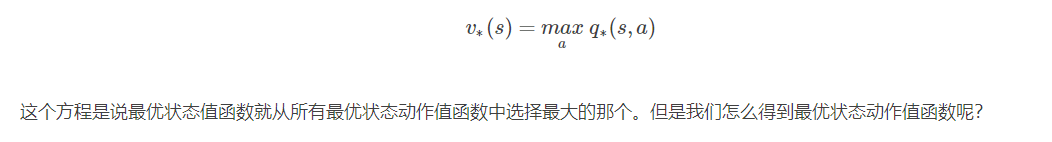
基于动态规划的强化学习则是一种基于有模型的方法,具体的讲,只有已知环境中所有的状态以及对应的策略分布、状态转移概率分布,才能应用动态规划。
大概就是要寻找最好的策略,通过迭代选择最大的价值来确定最佳策略。可是这策略究竟是怎么记录更新应用的。。。 优快云强化学习系列4 好的,已经基本没法掌握了动态规划的状态价值函数迭代在计算每一个状态的价值函数时,都需要遍历所有可能的动作,以及这些动作能够转移的所有下一个状态,这是一个穷举的过程,而事实上,我们无法做到穷举所有动作,同时我们也无法或者已知的状态转移概率分布,因此动态规划是一种理想条件下的方法,也是一种基于模型(model-based)的方法。本文将引入蒙特卡洛方法。蒙特卡洛方法是通过平均样本的回报来解决强化学习问题,其通过多次采样来对潜在的搜索空间进行描述,使用均值来近似价值,这也称为动态规划的一个推广,本人也认为动态规划在某些意义上是一个特殊的蒙特卡洛。
嘿,下面这个公式牛逼【可能是我孤陋寡闻了】。把求和公式变成增量公式了。 新平均值 = 旧平均值 +(新的值 - 旧平均值)/新数量
优快云强化学习系列5 看不懂在干嘛

先这样吧 我看看是不是应该先学tensorflow或者什么来边实战边学理论

















 6908
6908

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









