







引言
强化学习是除了监督学习和无监督学习之外的另一种机器学习方法。
监督学习:是从标记好的训练数据中学习模型。
无监督学习:是从未标记的数据中发现模式、结构或关系,而无需提前知道预期的输出标签。
强化学习:其重点是让智能体(agent)从与环境的交互中学习,以达到最大化某种形式的累积奖励。在强化学习中,智能体采取一系列行动来实现特定目标,然后根据环境的反馈(奖励或惩罚)来调整其行为策略。
强化学习有哪些好处?
适用于复杂环境:强化学习能够处理复杂、不确定和动态的环境,其中传统的监督学习和无监督学习方法可能无法有效应对。
自动化学习:强化学习不需要大量手工标记的训练数据,而是通过与环境的交互自动学习。这使其适用于一些领域,其中标记数据难以获得,成本高昂或不实际。
针对长期目标进行优化: 强化学习本质上侧重于长期奖励最大化,因此适用于行动可带来长期后果的场景。它特别适合每一步都无法立即获得反馈的现实情况,因为它可以从延迟的奖励中学习。
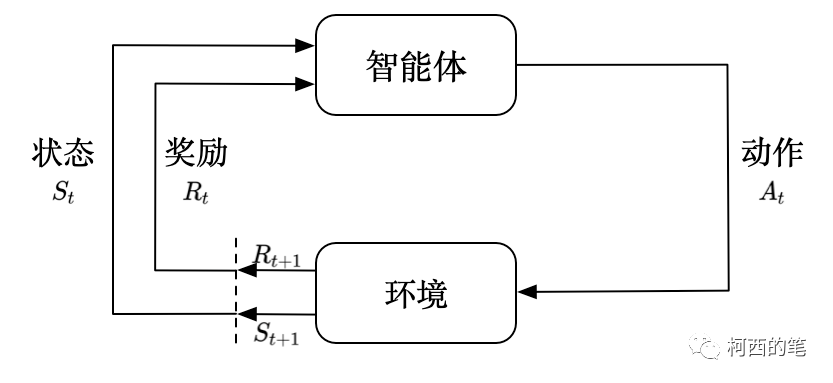
强化学习基本元素
智能体(Agent):智能体是强化学习系统的主体,它是进行学习和决策制定的实体。智能体可以是机器人、虚拟角色、自动驾驶汽车,或任何需要在环境中采取行动的实体。
环境(Environment):环境是智能体所处的外部世界,它包括智能体与其互动的所有事物和条件。环境可以是仿真环境、现实世界、游戏环境等。智能体通过与环境互动来获取信息和奖励。
状态(State):状态是描述环境的一个关键因素,它是一个包含有关环境的信息的表示。状态可以是连续的(如传感器数据)或离散的(如棋盘上的棋子位置)。智能体的目标是在不同的状态下采取行动以获得最大的奖励。
动作(Action):动作是智能体可以执行的操作或决策,它们是智能体与环境互动的方式。动作可以是连续的(如控制机器人的关节运动)或离散的(如在棋盘上移动一枚棋子)。
奖励(Reward):奖励是环境提供给智能体的反馈信号,用于评估智能体采取特定动作的好坏。奖励通常是一个数值,表示动作的质量或对智能体的性能产生的影响。智能体的目标是最大化长期累积的奖励。
策略(Policy):策略是智能体在特定状态下选择动作的规则或函数。策略可以是确定性的,即对于每个状态都有一个确定的最佳动作,也可以是随机的,即在每个状态下选择动作的概率分布。
价值函数(Value Function):价值函数用于评估状态或状态-动作对的好坏。它指示在特定状态下采取行动的长期回报期望值。有两种主要类型的价值函数:状态值函数(评估状态的好坏)和动作值函数(评估状态-动作对的好坏)。
回报(Return):回报是智能体在一个时间步骤或一系列时间步骤中获得的累积奖励。强化学习的目标通常是最大化长期回报,这要求智能体能够制定长期规划。
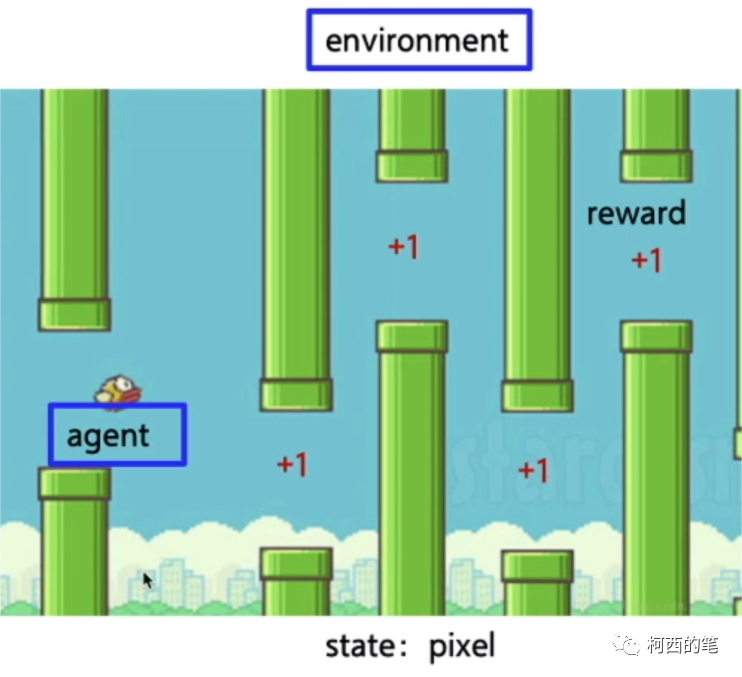
| Agent |
小鸟 |
| Environment |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











