







 本文档详细介绍了在Ubuntu 18.04上安装Hadoop的步骤,包括配置JDK、设置环境变量、下载及解压Hadoop、配置环境。接着讲解了Hadoop的基本命令,如查看目录、创建/删除目录、读取文件内容等。最后,通过一个简单的WordCount Java程序展示了如何进行分词处理,并指导了如何运行和查看结果。
本文档详细介绍了在Ubuntu 18.04上安装Hadoop的步骤,包括配置JDK、设置环境变量、下载及解压Hadoop、配置环境。接着讲解了Hadoop的基本命令,如查看目录、创建/删除目录、读取文件内容等。最后,通过一个简单的WordCount Java程序展示了如何进行分词处理,并指导了如何运行和查看结果。
安装 搭建环境
基本命令
简单分词处理
1.安装搭建
(环境:ubuntu 18.04 LTS)
-
安装 jdk8
sudo apt update #更新软件源的metadatasudo apt install openjdk-8-jdk-headlesssudo apt install net-tools openssh-server
-
配置环境变量
gedit ~/.bashrc- 在文件末另起一行添加如下内容,并保存
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/ - 运行命令 source ~/.bashrc 使之生效
-
下载hadoop
cd ~/Downloadswget "https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz"
-
解压
sudo mkdir /usr/local/hadoopsudo tar xzf hadoop-2.7.7.tar.gz -C /usr/local/hadoop
-
修改权限
sudo chmod -R 755 /usr/local/hadoop/hadoop-2.7.7sudo chown -R fosia:fosia /usr/local/hadoop/hadoop-2.7.7
fosia是我的用户名
-
查看hadoop版本信息:
/usr/local/hadoop/hadoop-2.7.7/bin/hadoop version
(配置了环境之后我们可以直接运行hadoop version来查看版本信息) -
配置一下环境变量,在~/.bashrc文件末加上如下内容并保存
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7export PATH=$PATH:$HADOOP_HOME/sbinexport PATH=$PATH:$HADOOP_HOME/bin
运行命令 source ~/.bashrc 使之生效
这样我们在运行hadoop的时候就不用写/usr/local/hadoop/hadoop-2.7.7/bin这么长的绝对路径
(Hadoop默认的是单机版本,不影响后续的简单操作,分布式版本网上也有搭建教程)
2.基本命令
- 查看目录
- 直接运行
hdfs dfs -ls是查看根目录 - 查看特定目录时运行
hdfs dfs -ls 路径例如hdfs dfs -ls /test
- 直接运行
- 创建目录
hdfs dfs -mkdir 路径- 例如
hdfs dfs -mkdir /test/test1
- 目录包含的文件大小
hdfs dfs -du 路径- 例如
hdfs dfs -du /test/test1
- 查看文件内容
hdfs dfs -cat 文件- 例如
hdfs dfs -cat output
- 删除
- 删除目标目录:
hdfs dfs -rm - 删除目标目录下的所有目录:
hdfs dfs -rm -r
- 删除目标目录:
- 把本地文件复制到hdfs的文件
hdfs dfs -put 本地文件 hdfs中的文件- 例如
hdfs dfs -put /Desktop/test.txt input
- 复制文件到目标文件
hdfs dfs -cp output /test/test1
- 移动文件
hdfs dfs -mv /output /test/test1
3.简单的分词处理
- 下载eclipse
- 下载:可以在虚拟机内下载也可以下载之后把tar文件拖入虚拟机
- 添加jar:分别建立用户hadoop_commom,hadoop_hdfs,hadoop_mapreduce并且添加相应的jar
- 创建java工程WordCount
- 创建过程中加入我们刚才创建的用户
- 在src新建类WordCount
- 粘贴代码下面代码保存
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(
Object key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new
StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,Context context )
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
if(args.length!=2){
System.err.println("Uage: wordcount <in> <out>"); System.exit(2);
}
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}- 导出为可运行的jar,在export里,注意导出的路径为本地,我这里导出在了桌面上
hdfs dfs -rm input/*hdfs dfs -rm -r output/hdfs dfs -put 新概念英语第二册.txt input/hdoop jar Desktop/WordCpunt.jar input output
我们在本地保存一个文档新概念英语.txt
将本地文件上传到hdfs的input文件中
运行WordCount,注意这里运行的一定是本地jar
hdfs dfs -get output/part-r-00000 .cat part-r-00000
将output的结果取回本地然后展示结果
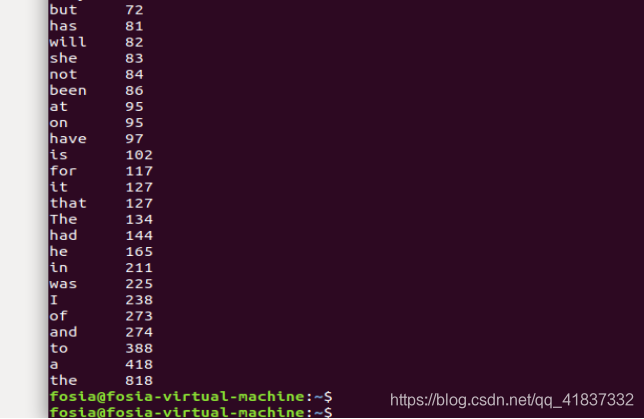
sort part-r-00000 -n -k2
以第二列的数组进行排序展示
(搭建或者导出过程中有问题私信qaq,比较忙就没写的很详细)

















 1569
1569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









