



 这篇博客介绍了EfficientPose,一种在RGB图像中实现高精度(97.5% LINEMOD)的端到端6D物体姿态估计方法。它结合了EfficienDet的2D检测与角轴旋转表示,创新地采用真实数据增强和扩展了EfficienDet。文章着重讨论了旋转估计网络、数据增强策略和ADD损失调整,展示了出色的性能和易用性。
这篇博客介绍了EfficientPose,一种在RGB图像中实现高精度(97.5% LINEMOD)的端到端6D物体姿态估计方法。它结合了EfficienDet的2D检测与角轴旋转表示,创新地采用真实数据增强和扩展了EfficienDet。文章着重讨论了旋转估计网络、数据增强策略和ADD损失调整,展示了出色的性能和易用性。
EfficientPose: An efficient, accurate and scalable end-to-end 6D multi object pose estimation approach
这篇文章的工作是近年来RGB姿态估计效果最好的,LINEMOD中精度可达97.5,最近阅读了论文并跑了代码。
首先它讲2DBBOX的识别也放进了整个网络里面,然后有四个要学习的东西,包括物体的类别,BBOX,R以及t,这里面主要是用来EfficienDet,然后旋转使用了角轴的表示方法,这一点和GDRnet使用6个参数表示R矩阵不同,后续探究旋转的不同表示应该是一个比较重要的事情。
文章有两个创新点:
1.6D位姿数据增强的方法,使用真实数据进行数据增强,感觉比使用合成数据跟个容易学习到
2.扩展了最先进的二维物体检测EfficienDet,具有额外的6D物体姿态估计能力,同时保持其固有的单镜头多目标的优势和实例检测、高精度、可伸缩性、效率和易用性。
旋转估计网络
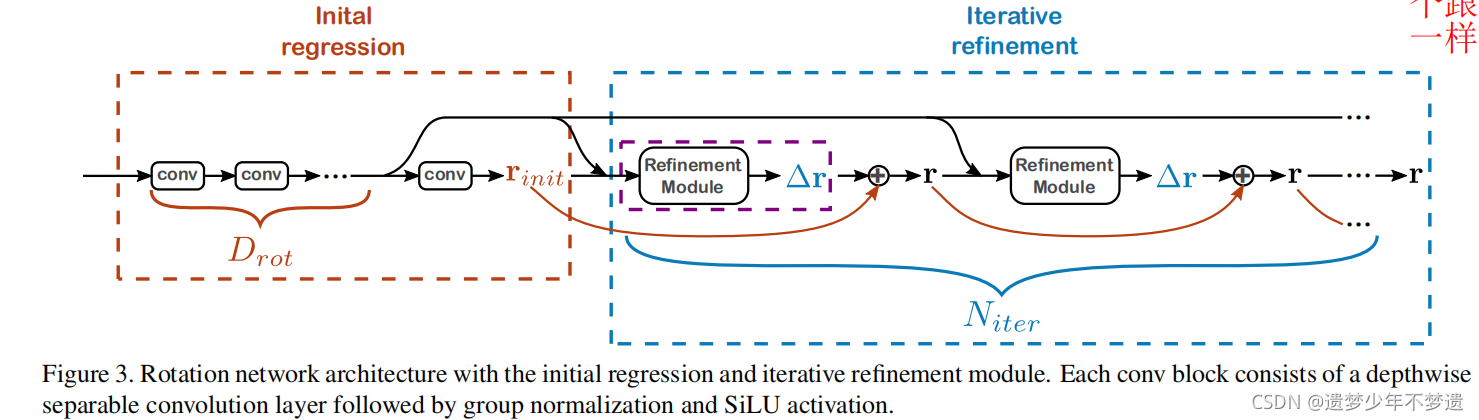
这个旋转估计网络的一个优点是估计出一个旋转之后,会加入一个细化网络,这样可以使得网络效果更好。
然后还做了一些网络上的改进,这点没看太明白
平移估计网络
t方面的估计使用了跟PoseCNN一样的表示方法,先估计深度tz,然后估计出tx和ty,如下图,原理就是下面的投影模型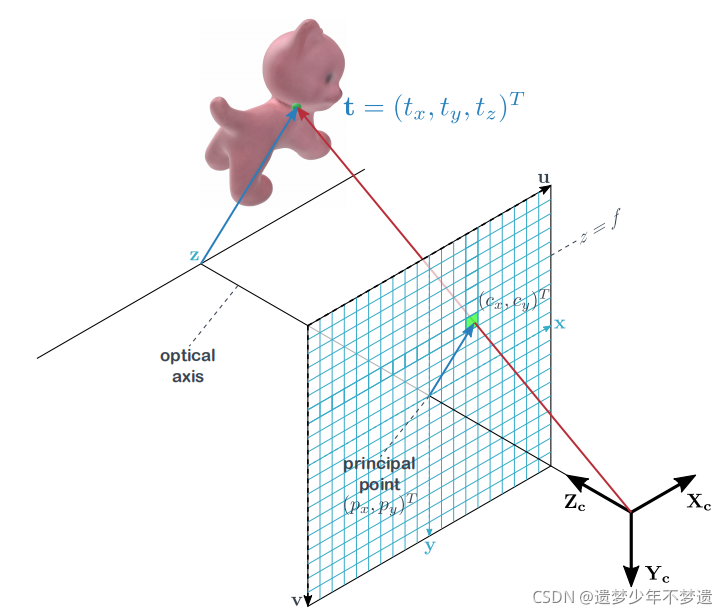
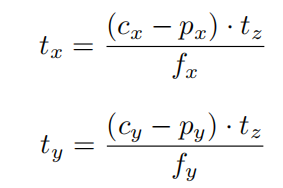
LOSS设计方面
这个直接用ADD的方法去做的,然后针对对称物体做了一些改进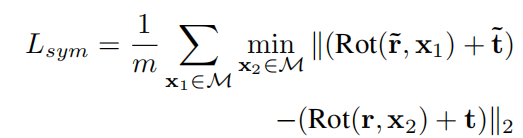
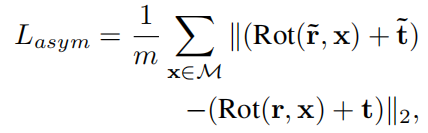
数据增强
对于数据增强的手段也是比较简单的,主要是对图像进行Z轴方向的旋转,这个旋转的角度可以得到旋转矩阵,原R左乘这个旋转矩阵就可以得到增强数据,平移矩阵也一样,对于缩放,也是z轴方向的
 备注:该网络效果还是不错的,我只使用了渲染数据训练,3000张数据,然后测试效果不错,网络的的重点在于如何送入合适的数据集
备注:该网络效果还是不错的,我只使用了渲染数据训练,3000张数据,然后测试效果不错,网络的的重点在于如何送入合适的数据集

















 2090
2090

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









