







Improve Mathematical Reasoning in LanguageModels by Automated Process Supervision
arxiv: https://arxiv.org/abs/2406.06592
问题背景
COT和SC-COT对于模型推理能力的提升仍然有效,已有研究提出用一个验证器去帮助LLM提升推理能力。采用ORM结果验证器岁可以对最终结果生成一个信号,但是不能去奖励或者惩罚中间步骤。采用PRM可以对中间步骤在更细粒度的视角下,对中间步骤进行奖励或者惩罚。受到AlphaGo Zero的启发,本文提出了一个分而治之的蒙特卡洛树搜索算法OmegaPRM,来有效的收集高质量过程监督数据。
本文方法
这篇论文提出了一种名为OmegaPRM的新型分治风格蒙特卡罗树搜索(MCTS)算法,通过引入二分搜索算法来高效识别COT中的第一个错误快速定位错误位置,用于自动收集高质量的过程监督数据。
(1)蒙特卡洛过程标注方法
已有的方式是构建了一个『完成者』策略,接受一个问题q和一个包含前t步骤
x
1
:
t
x_{1:t}
x1:t的前缀解决方案,并输出后续步骤的完成度。

在图里的(a)中,对于解决方案的任何步骤,可以使用更完备的策略从该步骤随机抽样k个rollout。然后,将这些rollout后得到的最终答案与正确答案进行比较,评估出一个前缀步骤的『正确性等级』,公式如下:

这种方式计算了从步骤t开始后所有rollout里得到正确答案的比例情况,这种方式需要从头到尾执行每个步骤的rollout,需要大量的调用,开销过大。
为了优化标注效率,本文提出了一种基于二分搜索的蒙特卡洛的方法。当解决方案中出现了第一个错误步骤时,这种数据就足以用来训练PRM。基于这种想法,本文的目标是有采用有效的方式定位第一个错误。主要是通过重复划分解决方案和执行rollout来实现这一点。
- 二分搜索定位错误大致流程:
假设我们的目标数据是真负例,首先从中点步骤m将其拆分,然后对前半步骤1:m执行rollout,当 c m > 0 c_m>0 cm>0时,表示前半步骤中至少有一个步骤是正确的可以得到正确的答案,错误步骤在后半部分。当 c m = 0 c_m=0 cm=0时,说明前半部分中很有可能有错误步骤,因为从该步骤往后进行rollout后的结果中没有一个是正确的。
以此方式不断迭代定位错误,直至到达停止条件(该解过程足够短,视为单个步骤)。从而将时间复杂度从O(kM),缩短至O(klogM)。
(2)蒙特卡罗树搜索
在实践中,需要为一个问题收集多个PRM训练样例(即问题、部分解和正确性标签的三元组)。与每次从头开始不同,本文在过程中存储所有的rollout,并在需要收集新例子时,从这些rollout中的任何一个执行二分搜索。这种方法允许使用具有相同解决方案前缀,但补全后续步骤和不同错误位置的三元组。
考虑一个正式的station-action树的表示:
- 状态s:包含问题和先前所有的推理步骤
- 动作a:特定状态下潜在的后续步骤。
- 根状态 r r o o t = q r_{root}=q rroot=q是没有任何推理步骤的初始问题。
- 策略 π ( a ∣ s ) = L M ( a ∣ s ) \pi(a|s)=LM(a|s) π(a∣s)=LM(a∣s)。
- 状态转移函数: s ′ = C o n c a t e n a t e ( s , a ) s'=Concatenate(s,a) s′=Concatenate(s,a),简单地将前面步骤和动作步骤进行拼接。
传统的MCTS的动作空间为有限空间,但是语言模型具有无限的动作空间,在实践中本文采用temperature采样为prompt生成固定数量k的补全,将k动作视为近似的动作空间。OmegaPRM的MCTS算法如下:
树结构
节点:每个节点代表部分CoT解决方案的状态,包含问题q、前缀解决方案 x 1 : t x_{1:t} x1:t和所有之前的模拟结果。每个边 (s, a) 是从节点s开始的单个步骤或连续步骤的序列。每个节点存储一组统计信息:
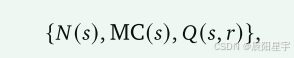
包括访问次数(N(s))、蒙特卡罗估计(MC(s))和state-rollout值函数(Q(s, r)),这个值函数与树遍历的选择阶段选择rollout的机会相关。具体来说:
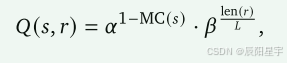
其中, α , β ∈ ( 0 , 1 ] 和 L > 0 \alpha, \beta \in (0,1] 和 L>0 α,β∈(0,1]和L>0是常数超参数。len® 是以token个数表示的rollout长度。Q表示每次迭代选择rollout的可能性,公式中第一部分目的是让MC(s)接近于1解能尽可能的大,第二部分是惩罚过长的rollouts。目标是定义一个启发式方法,选择最有价值的rollout进行搜索。文中建议在选择过程中优先考虑『被认为是正确的错误答案』。『被认为是正确的』表示蒙特卡罗估计MC(𝑠)接近于1的状态,但最终答案是错误的。 作者期望PRM可以学习到如何检测出这种『高MC值但结果是错误的』这一类rollout错误问题,这对于纠正策略所犯的错误方面很有用。
选择阶段
池管理:维护一个满足条件的模拟结果池,这些模拟结果的MC(s)值在0到1之间。
选择策略:在每次选择期间,根据树统计数据
(
s
,
r
)
=
a
r
g
m
a
x
(
s
,
r
)
[
Q
(
s
,
r
)
+
U
(
s
)
]
(s,r)=argmax_{(s,r)}[Q(s,r)+U(s)]
(s,r)=argmax(s,r)[Q(s,r)+U(s)]选择执行一个rollout,使用PUCT算法的变体:
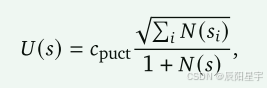
其中 c p u c t c_{puct} cpuct是一个决定探索水平的常数,U(s)是一个探索因子,用于平衡探索和利用。
二分搜索
错误定位:在选定的模拟结果中进行二分搜索,以识别第一个错误位置。模拟结果中MC(s)值在0到1之间的部分被添加到选择候选池中。在第一个错误之前的所有分割和rollout位置都成为新的状态。
新状态生成:所有在第一个错误之前的划分和模拟位置成为新的状态。
维护阶段
统计更新:在二分搜索后,更新树的统计信息(N(s)、MC(s)和Q(s, r))。具体来说,对于所选的(s, r),N(s) 会被加一,MC(s)和Q(s, r)都针对二分搜索中采样的新rollout进行更新。这个阶段和AlphaGo的backup阶段类似,但更简单,不需要从叶子结点到根的递归更新反向传播。
树构建
迭代过程:通过重复上述过程,构建一个state-action树。当搜索次数达到预定限制或池中没有更多的模拟候选时,构建结束。
(3)训练PRM
在构造的状态-动作树中,每个具有单步动作的边(𝑠,𝑎)都可以作为PRM的训练示例。它可以使用标准分类损失进行训练:
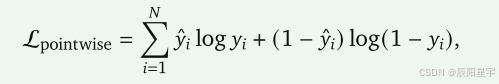
y
^
\hat y
y^是正确标签,𝑦 = PRM(𝑠, 𝑎) 是PRM的预测分数。
三种方式:
- 软标签: y ^ = M C ( s ) \hat y=MC(s) y^=MC(s)
- 硬标签: y ^ = 1 [ M C ( S ) > 0 ] \hat y=1[MC(S)>0] y^=1[MC(S)>0]
- 最小化PRM预测值与参考Bradley-Terry模型的标准化配对偏好值之间的交叉熵损失。
实验设置
- 生成数据
- 数据集:使用MATH数据集,划分出12K训练集和500测试集。
- 超参数:𝛼 = 0.5, 𝛽 = 0.9, 𝐿 = 500, c p u c t c_{puct} cpuct = 0.125。限制搜索步骤为100步,共产生了150万个过程监督标注数据。
- 基座模型
Gemini Pro策略模型:通过在数学指令数据集上蒸馏Gemini Ultra的知识,微调Gemini Pro得到的一个策略模型。该策略模型在MATH数据集上准确率为51%。 - 指标和基线
- 基线数据集:PRM800K、Math-Shepherd
- 评估指标方式:基于多数投票得到结果
实验结果
(1)MATH数据集评测结果
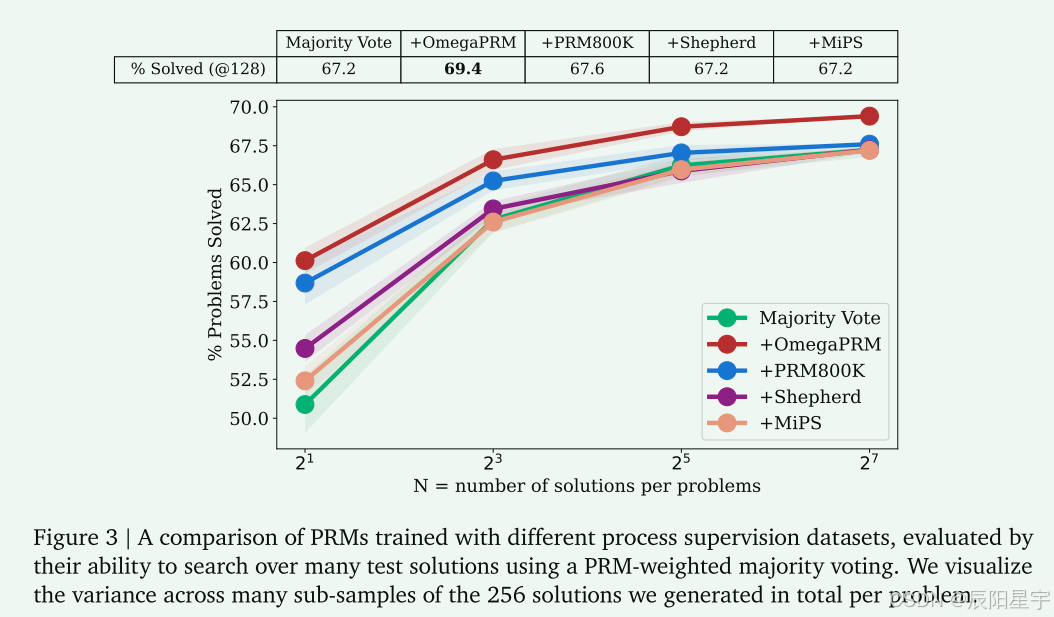
图给出了在不同过程注释数据集上训练的PRMs的性能比较。OmegaPRM始终优于其他数据集。经过微调的Gemini Pro使用OmegaPRM加权多数投票在MATH数据集上达到69.4%的准确率。
(2)步数分布
过程监督的一个重要因素是解决方案中的步骤数和每个步骤的长度。以前的方案是使用基于规则的策略将解决方案分解为步骤,例如,使用换行符作为分隔符。本文提出了一种更灵活的步骤划分方法,将解中『任何连续token序列』视为有效步骤。作者观察到Math-Shepherd中的许多步分在一定程度上缺乏语义连贯。因此,作者假设语义显式切割对于训练PRM是不必要的。
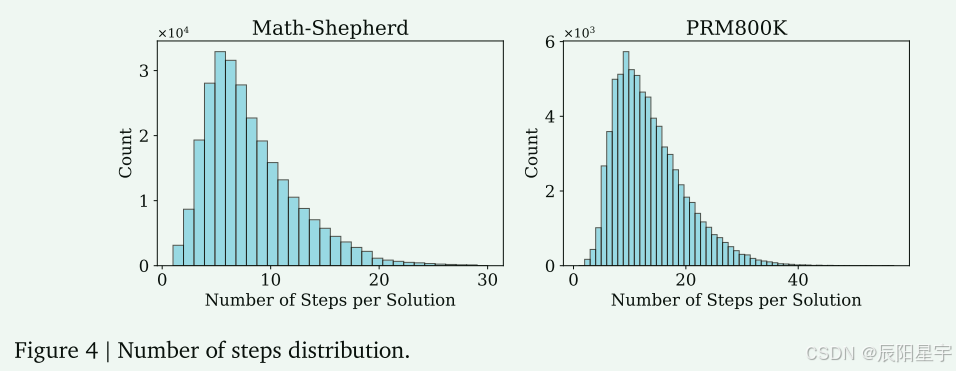
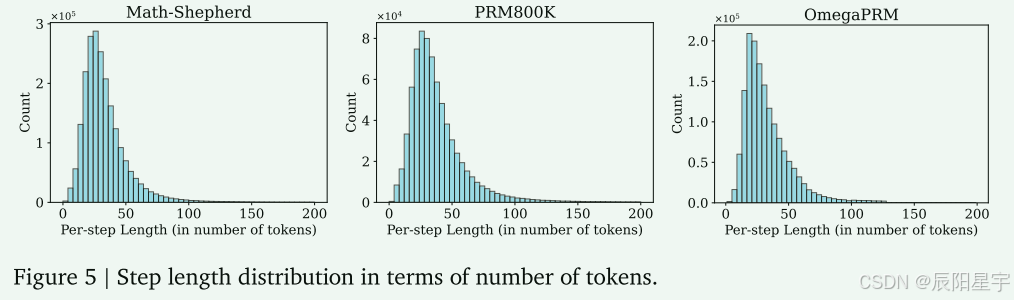
在实践中,首先检查PRM800K和Math-Shepherd中每个解决方案的步骤数分布,如图图所示,注意到大多数解决方案的步骤少于20个。在二分搜索中,文中的目标是将一个完整的解分成16个部分。为了计算期望的步长,我们将平均解的长度除以16。当步长小于此值时,二分查找终止。得到的OmegaPRM和其他两个数据集的步长分布如图图所示。这种灵活的分割策略产生的步长分布类似于基于规则的策略。
(3)RPM训练目标

PRM可以使用多个不同的目标进行训练。文中使用MATH测试集中分割的问题构造了一个小的过程监督测试集。分别使用逐点软标签、逐点硬标签和成对损失来训练PRM,并评估它们对每步正确性的分类准确率。表中给出了不同目标的对比,发现点式软标签是其中最好的,准确率为70.1%。
局限性
自动过程注释存在噪声。由于假阳性和假阴性引入了一些噪声,但实验表明它仍然可以有效地训练一个PRM。


















 655
655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











