




arxiv: https://arxiv.org/abs/2310.11716
背景
不一致或质量欠佳的数据集可能导致模型产生不稳定、有偏见甚至似是而非的输出,从而降低其可靠性和适用性。LLM对劣质数据具有敏感性,可以通过精选高质量数据子集来增强性能指标。从LLM的评估能力和自我增强的当代范式中获得灵感,本文使用『反思-循环』机制在指定的标准下反思评估并对当前数据集进行改进。这种数据精炼的过程,称之为"反思调优"。
本文方法
- 思想动机
- 反思答案的学生通常可以取得更高的分数,因为他们可以在反思过程中发现错误并做出一些合理的改变。
- LLM具备自我改进和评估能力。
- 方法实现过程
- 大致流程:输入给模型初始指令对 (x_0, y_0) ,模型需要根据特定的标准集反思出更好的指令对。为保证输出内容的多样性,引入COT和TOT的方式。为了让得到的y变为最优值,再继续对已有的y进行进一步反思,得到更优质的响应y。
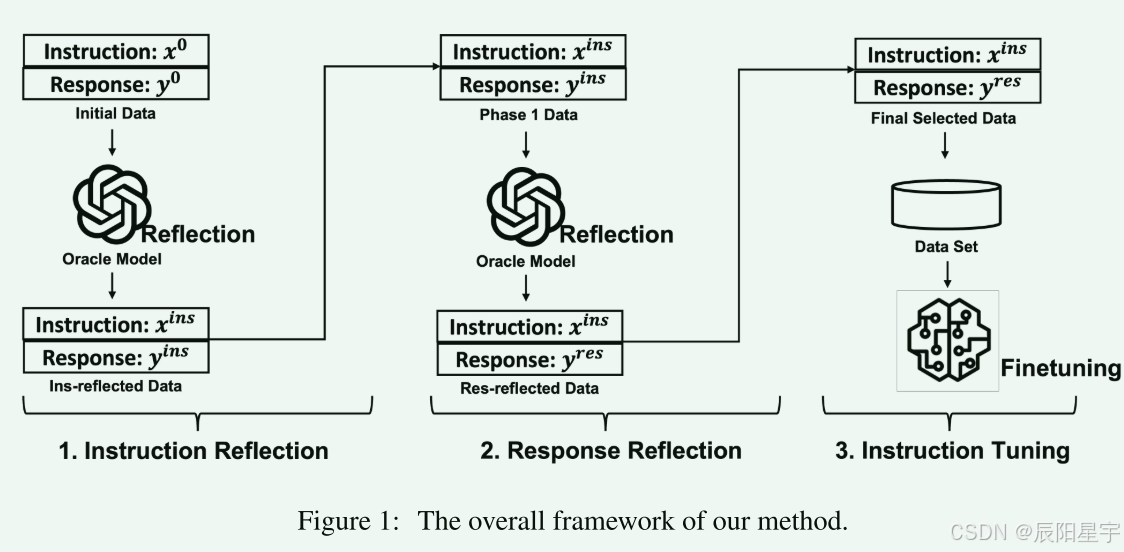
- 针对输入指令对进行反思
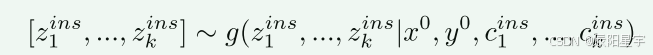
其中,x0、y0是初始输入指令对,c{ins}是标准,z{ins}是根据上述输入得到的反思的过程,
- 根据反思结果得到新的指令对
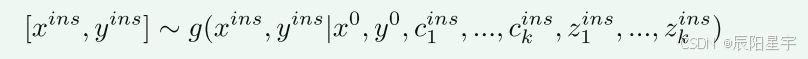
其中,x{ins}、y{ins}是根据上述的输入得到的新的指令对。
标准包括:主题的复杂性、回应所需的细节程度、回应所需的知识、指令的模糊程度、是否设计逻辑推理或解决问题
- 针对响应y进一步优化
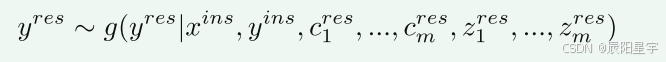
其中,z{res}是针对y{res}的标准,y^{res}是最终的输出响应。最后得到的 (x^{res}, y^{res}) 作为最终指令对。
标准包括:有用性、相关性、准确性、细节水平。
- Prompt设计
-
反思指令对

-
反思响应

-
实验设置
- 基座模型
- Alpaca 7B和WizardLM 7B
- 数据集
- 训练集数据
- Alpaca datasets、WizardLM datasets的子集WizardLM-7b中的训练样本(70000个)
- 评估基准平台
- Huggingface Open LLM
- ARC:评估模型回答小学水平科学问题的熟练程度
- HellaSwag:评估模型常识推理能力
- MMLU:评估模型在57个不同领域任务上的能力(涉及小学数学、美国历史、计算机科学等)
- AlpacaEval
- 衡量模型在遵循通用用户指令方面的熟练程度。
- Huggingface Open LLM
- 训练集数据
- 评估指标
- 评估方式
- 让模型自动评估,对比两个模型中哪个模型的输出响应更好。
- ChatGPT自动评估
- 为了避免输入两个序列输入顺序的不同引起的偏见,分别输入两次,以不同的顺序输入给ChatGPT,让其评价。
- 评价等级分为三等:
- 赢:两次都赢或者一次平局一次赢
- 平局:两次平局或者一次赢一次输
- 输:两次都输或者一次平局一次输
- 获胜率作为最终衡量标准
- 评估方式
实验结果
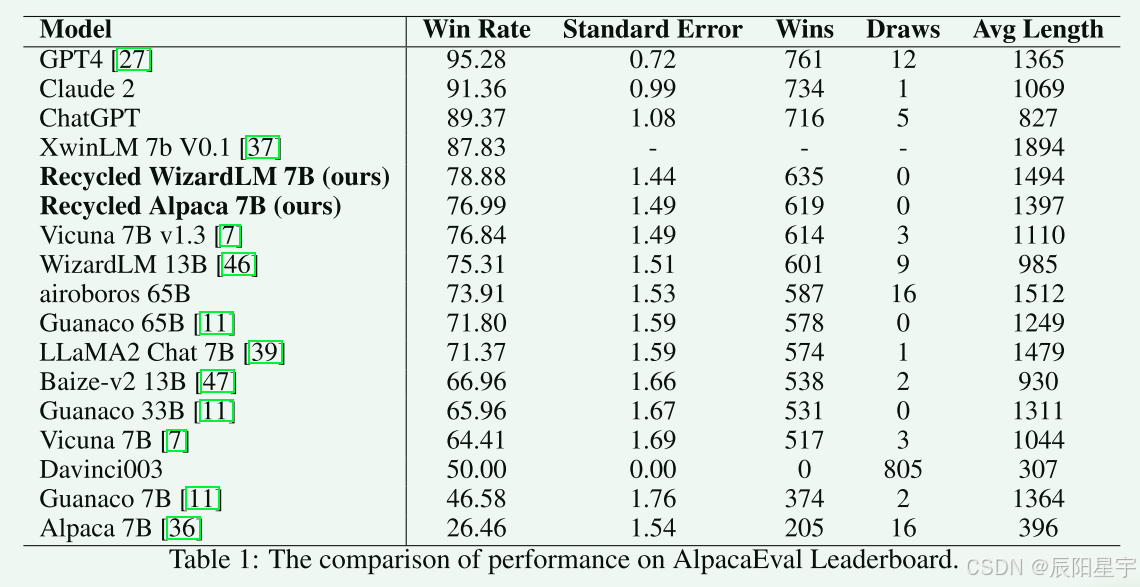
在AlpacaEval排行榜上,除了比XwinLM 7b V0.1模型胜率低外,和其他市面上7B的开源模型对比,胜率都比其他开源模型更高。
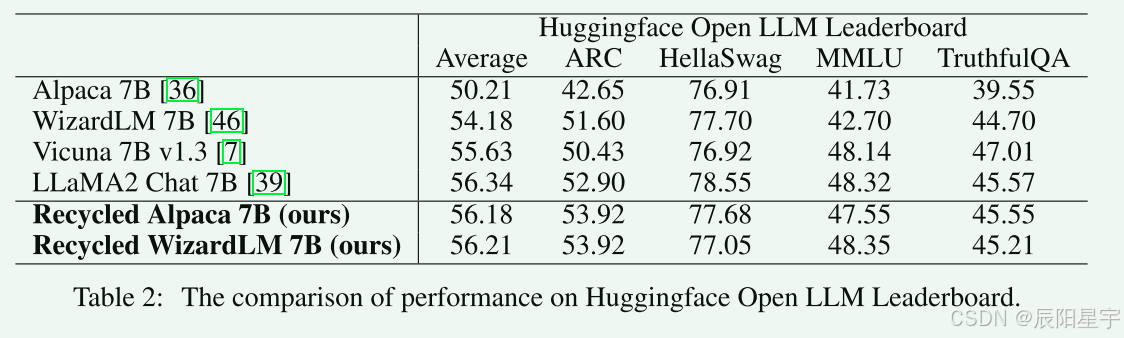
在Huggingface Open LLM排行榜上,本文方法(只进行了SFT微调)可以和使用过RLHF阶段微调的LLaMA2-Chat-7B基本持平。

本文从指令长度、生成响应长度、指令困惑度、没有相关指令下响应的困惑度、有相关指令下响应的困惑度、连贯性、指令遵循难度评分这几个维度对比了原始chat模型和用本文方法SFT后的模型性能上的区别。可以看出,性能效果大大增加。
指令部分,作者发现Alpaca的指令经过本文方法后会被增长,而WizardLM的会被缩短。而Alpaca指令更为简洁和基础,说明本文方法会对这种特点的指令增加它的复杂行。而WizardLM的指令复杂性更高一些,经过本文方法后指令会变的跟间接一些。
响应部分,本文方法倾向于生成细节更丰富的文本内容,从而导致更长的响应长度。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











