




作者:cmathx
原文:https://zhuanlan.zhihu.com/p/1477078851
openai o1复现中,有个比较关键的问题,怎么样自动化构造prm模型的训练数据?本文主要从代码层面,来解析OmegaPRM原理。
论文
Improve Mathematical Reasoning in Language...[1]
原理
Markov决策过程

OmegaPRM
State:对应Markov决策过程中的状态,rollout:对应Markov决策过程中的动作;
-
• step1:初始化root节点state;每个state包含n个扩展rollouts,q+pa作为prompt,进行n次llm生成采样;基于bootstrap采样方法估计Monte Carlo模拟正确答案的概率mc;
-
• step2:从所有节点中,基于UCB1(Explore&&Exploit方法)选取最优的“state和rollout”,添加到PRM训练集;Exploit:alpha ** (1 - mc) * beta ** (len(r) / L),其中:mc表示蒙特卡洛模拟正确答案概率、len(r)表示LLM生成的长度;Explore:c_puct * sqrt(N_sum) / (1 + s.v),其中:N_sum表示所有节点的访问次数,s.v表示当前节点的访问次数,c_puct控制MCTS树的探索程度;
-
• step3:评估最优“state和rollout”,二分rollout的结果,将左半部分纳入到新的state中,并计算新的mc;mc=1,表示state完全包含正确答案,忽略;mc=0,表示state完全没有生成正确答案可能性,添加到叶子节点;mc>0,表示state作为继续探索的节点;
-
• step4:重复step2、step3,直至“探索到足够的样本、无法继续探索”退出;
-
• step5:将叶子节点全部添加到PRM训练集;
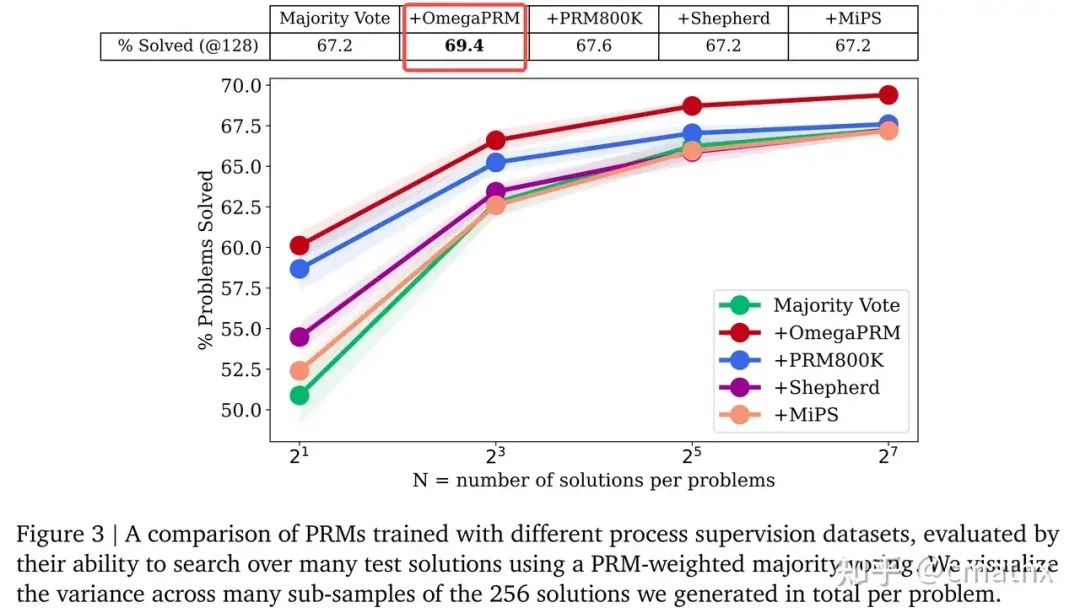
PRM模型训练效果
论文的base模型

基于OmegaPRM方法合成数据,在MATH数据集,相比base model51%的准确率,OmegaPRM准确率提高到69.4%;
其他PRM方法
OmegaPRM:gemini提到的方法;
AlphaMath:qwen提到的方法;
Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations[2]
AlphaMath Almost Zero: Process Supervision without Process[3]
源码来源
https://github.com/openreasoner/openr[4]
源码解析
数据结构
class State:
def __init__(self, q, pa, a):
self.q = q #问题
self.pa = pa #当前step的prompt
self.a = a #答案
self.mc = None #基于当前节点,生成正确答案的概率
self.v = 0 #被访问次数
self.rollouts = [] #扩展的子节点
self.rollout_was_visited = [] #扩展的子节点是否被访问主流程
# Load the JSON data
data = load_json_file(json_file_path)
# Process each problem and its final answer
for i, item in enumerate(data):
problem = item.get('problem', 'No problem found')
final_answer = item.get('final_answer', 'No answer found')
# Print to console
print(f'Problem {i + 1}: {problem}')
print(f'Final Answer: {final_answer}')
&n 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 326
326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









