







 本文探讨了利用深度学习模型(Seq2Seq+BIGRU)生成新闻主题句,并通过引入领域知识图谱优化多文档摘要,解决了信息冗余和组织难题。研究重点是构建主题句与知识图谱的映射,提升摘要的连贯性和非冗余性。
本文探讨了利用深度学习模型(Seq2Seq+BIGRU)生成新闻主题句,并通过引入领域知识图谱优化多文档摘要,解决了信息冗余和组织难题。研究重点是构建主题句与知识图谱的映射,提升摘要的连贯性和非冗余性。
论文地址:基于领域知识图谱的多文档摘要生成与应用

先验知识
1.多文档摘要技术:
(理解:类似于每篇文章的摘要、关键词,方便通过标签筛选是否是你需要的内容)
利用计算机将同一主题下或者不同主题下的多篇文档描述的主要内容通过信息压缩技术提炼成一个文档的自然语言处理技术。目的是通过对原文档进行压缩提炼,为用户提供简明扼要的文字描述。形式化定义:

2.文档摘要的研究方法主要分为两种:一种是抽取式的摘要生成方法。主要通过提取原文的句子作为摘要。另一种是生成式的摘要生成方法。通过对文档内容特征提取,用新的句子概括原文作为摘要。前者的方法易于实现,但是摘要的可读性、连贯性较差。后者可读性较好,但是难以实现。
抽取式摘要的一种思路是将原文按句子进行切分、将每个句子打分、排序,最后选择排序靠前的句子作为最终的摘要结果。
生成式摘要是指通过理解文档的内容和意思,它不仅将那些重要的信息进行抽取,同时抽象释义出原文档的内容。这种方法更加接近摘要的本质,更加类似于人工提炼的摘要结果。
3.Seq2Seq框架
Seq2Seq框架是一种序列转换的框架,核心思想是使用深度神经网络(本文主要:双向门控循环单元神经网络BIGRU)将一个输入序列映射为另一个输出序列,在这个过程中,它是由编码器和解码器构成。Seq2Seq(Sequence to sequence Leanring),又称为端到端学习,编码器的作用:将输入的原文档编码成一个向量(context),该向量是原文档的一个表征,包含了文档背景。解码器的作用:从向量中提取重要的信息,加工,最后生成文档摘要。
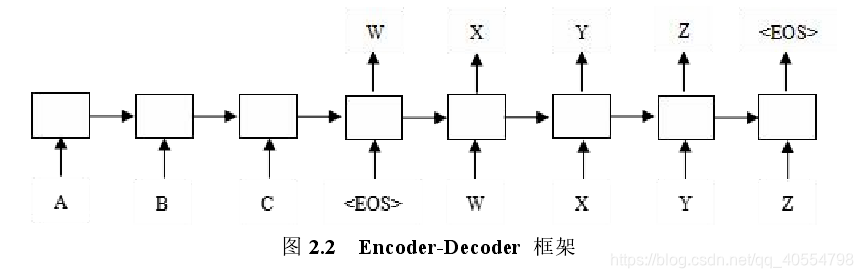
框架解读:在训练的过程中,编码器读入的是文档中的字符或者词向量,假设输入了A,B,C及终止符,编码器就会将输入的向量编码成一个固定长度的向量W,在解码时,则将W作为初始的状态,根据W解码来预测X,在预测Y的时候,则将之前解码输出的X作为下一次预测的输入,迭代循环,直到遇到终止符结束。
4.门控循环单元神经网络GRU




5.Beam Search集束搜索

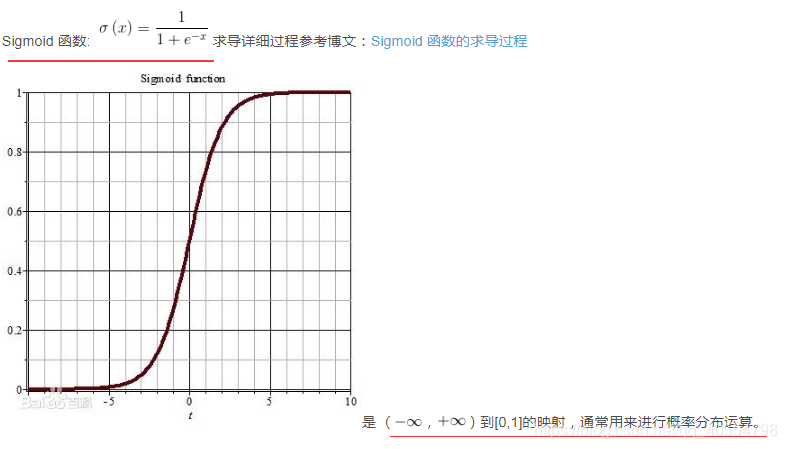
6.sigmoid函数

7.tanh激活函数
sigmoid函数过有一个缺点就是输出不以0为中心,使得收敛变慢的问题。而Tanh则就是解决了这个问题。Tanh就是双曲正切函数。等于双曲余弦除双曲正弦。函数表达式和图像见下图。这个函数是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 781
781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









