







 本文详细介绍了深度学习模型构建的步骤,包括定义问题、收集数据、设定性能指标、模型评估、数据预处理、模型搭建、交叉验证和测试集验证。重点讨论了激活函数和损失函数的选择,以及如何通过逐步扩大模型规模和正则化提升模型性能。强调了在不同验证方法下找到最佳模型的重要性。
本文详细介绍了深度学习模型构建的步骤,包括定义问题、收集数据、设定性能指标、模型评估、数据预处理、模型搭建、交叉验证和测试集验证。重点讨论了激活函数和损失函数的选择,以及如何通过逐步扩大模型规模和正则化提升模型性能。强调了在不同验证方法下找到最佳模型的重要性。
一、定义问题,收集数据集。
注意确保数据集特征丰富程度足以作出预测
二、定义模型预测性能指标
平衡分类问题常用精度、接受者操作特征曲线下面积;
不平衡分类问题常用精度和召回率;
标量回归常用平均绝对误差(MAE)等等。
三、确定模型评估方式
如:留出法、K折交叉验证、乱序重复K折交叉验证
四、数据预处理
预处理目标:
1、特征值为张量数据
2、特征取值较小(0-1区间或正负1区间)
3、特征非异质数据
4、特征缺失处理为0
五、搭建模型
1、确定激活函数、损失函数
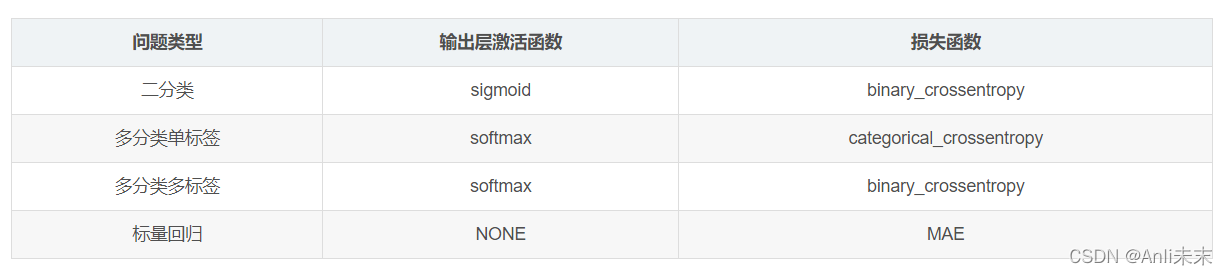
激活函数与损失函数
①在选择激活函数时, 一般隐层选择 Leak ReLU 函数会得到较为理想的效果 。
当然这不是恒定的规律,我们可以尝试使用 Sigmoid 函数作为隐层激活函数,但注意使用时尽量不要超过太多隐层。
②另外可以使用 Tanh 函数来代替 Sigmoid 函数观察模型的精确率曲线图。
如果直接使用 ReLU 函数作为激活函数,注意梯度下降算法的学习率参数不能设置得过高,避免神经元的大量“消亡”。
③对于输出层,一般使用 softmax函数获得同分布最高概率作为输出结果。
④ 此外,可以加入 Batch Normalization (BN)层,让下一层的输入数据具有相同的分布。如果遇到神经网络训练时收敛速度慢,或梯度爆炸或者梯度消失等无法训练的状况都可以尝试加入 BN层,然后观察其训练结果。
2、从简单结构开始逐步扩大模型规模
3、考虑正则化和dropout
六、交叉验证
在验证集上多次训练,找到最佳性能的模型结构
七、测试集验证
注意:测试集性能和验证集性能相差较大,考虑采用更复杂的验证方法,如乱序重复K折交叉验证


















评论 3

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
查看更多评论
添加红包








