



DeepSeekMath-V2横空出世:吊打Google Gemini,首创“自验证数学推理”全深度解析
大模型Scaling Law可能已失效,算法创新才是破局关键。本文深度拆解DeepSeekMath-V2背后的核心技术——自验证数学推理训练,看它如何以1/1000的算力通过“左右互搏”实现数学能力的指数级进化。
🚀 引言:OpenAI前首席科学家的预言
2025年11月25日,OpenAI前首席科学家Ilya Sutskever在采访中抛出一个震动业界的观点:大模型Scaling Law可能已失效。他断言,即使将参数、数据、算力再放大100倍,也难以触及更高层次的智能天花板。未来的关键,在于算法层面的深度创新。
仅仅3天后,DeepSeekMath-V2横空出世,仿佛是为了狠狠印证Ilya的预言。这款模型不仅没有堆砌算力,反而以不到谷歌1/1000的资源,凭借独创的 “自验证数学推理训练法”(Self-Verifiable Mathematical Reasoning) ,在数学领域正面击败了谷歌最强模型 Gemini Deep Think。
一个人分饰三角:既是运动员,又是裁判,还是裁判的监督员。这种看似“天方夜谭”的左右互搏,正是DeepSeekMath-V2突破极限的秘诀。
📊 战绩:碾压级表现
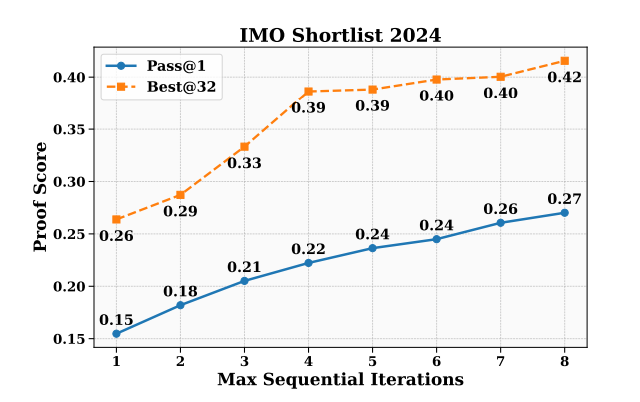
DeepSeekMath-V2的进化速度令人咋舌,其数学能力曲线一路飞升:
- CNML(中国高中数学联赛):在极高难度的赛题上,得分碾压GPT-5的Thinking-High模式。
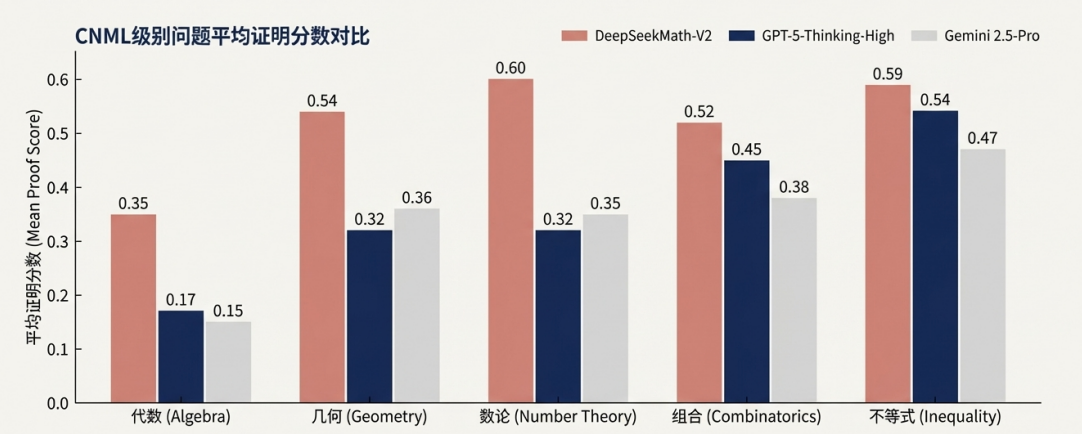
- Putnam 2024(北美普特南数学竞赛):解决了12个问题中的11个,取得近乎完美的分数,超越所有人类参赛者。

- IMO-ProofBench:在Google DeepMind提出的基准测试中,斩获金牌级成绩,Basic数据集接近满分,大幅领先尚处于安全测试阶段的Gemini Deep Think。
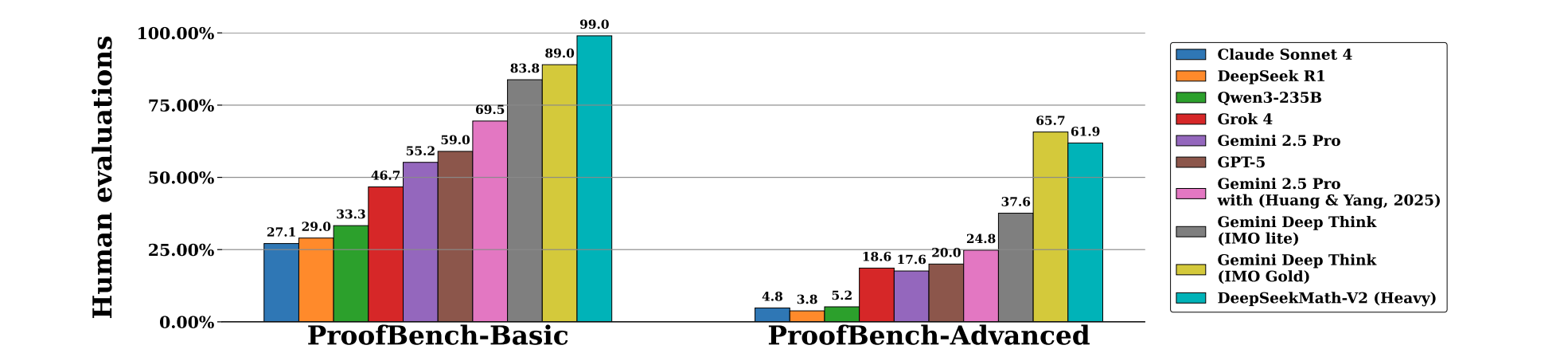
更重要的是,DeepSeek选择了全面开源!
目前,模型论文、Benchmark结果已在GitHub开源
模型权重也已上传至HuggingFace,开发者可直接下载部署
论文的精校翻译版,和更多DeepSeek本地部署与Agent开发教程,都已经上线至赋范大模型技术社区,加入赋范空间 即可免费领取。
Math模型往往是下一代通用模型的序章(如R1背后的GRPO算法最初便源于DeepSeekMath)。

而现在DeepSeekMath-V2模型提出的自验证训练方法已经表现出惊人的成绩,相信很快DeepSeek-V4模型就会发布,并且采用这一革命性的训练范式。
深入解读 DeepSeekMath-V2 训练推理方法
接下来为大家详细介绍DeepSeekMath-V2模型的训练流程,以及详解论文中提出的极具里程碑意义的算法:自验证数学推理训练法。

🧠 核心痛点:答案对了,过程对吗?
阻碍大模型智力突破的核心因素在于:训练目标过于强调最终答案的正确性,而忽视了推理过程的严谨性。
在AIME等竞赛中,模型可能“蒙”对答案,但在需要严密逻辑的数学证明题面前往往一塌糊涂。输出正确答案 ≠ 推导过程正确。
要解决这个问题,必须引入数学证明题训练。但证明题无法像选择题那样简单判断对错,如何自动化评估证明过程的好坏?人工评判显然不现实。
🛠️ 解决方案:三位一体的“左右互搏”系统
DeepSeek设计了一个包含三个角色的闭环系统:
- Generator (生成器):学生,负责解题。
- Verifier (验证器):老师,负责批改,评估解题过程。
- Meta-Verifier (元验证器):教导主任,负责监督老师的评分是否合理。
需要注意的是,这里的生成器、验证器和元验证器三个模型最开始都是DeepSeek-V3.2模型的一个微调版本。
而在这个三个模型的协同系统中,其实最重要的是验证器
通过GRPO算法(一种强化学习训练方法),让验证器学会对不同的数学证明过程进行打分,并且和R1模型的训练过程类似,在验证器的训练过程中,会通过设置格式奖励,逼迫其诞生对每个数学证明过程的评价文本(Comment/Analysis),相当于是学会写对解题过程的评语,而这其实就是对解题评分的思考链。
第一阶段:冷启动 (Cold Start) —— 四步走战略
冷启动阶段使用约17,000条包含人类专家评分的数据(0分、0.5分、1分)。
Step 1:练老师 (Verifier Optimization)
使用GRPO算法训练验证器。类似于DeepSeek-R1,通过设置格式奖励,强制验证器生成对解题过程的评价文本(Comment/Analysis)。这就是“评分的思考链”。
| 模型角色 | 输入 (Input) | 输出 (Output) |
|---|---|---|
| 验证器 | 数学题 + 证明过程 | 评语 + 打分 |
Step 2:练督导 (Meta-Verifier Training)
为了防止老师(验证器)为了凑分数胡编乱造评语,DeepSeek引入了“套娃”监督。人类专家对验证器的评语进行打分,以此训练元验证器。
| 模型角色 | 输入 (Input) | 输出 (Output) |
|---|---|---|
| 元验证器 | 数学题 + 证明过程 + 验证器评语 | 对评语的评语 + 评语质量打分 |
注:DeepSeek认为不需要无限套娃,因为元验证器的任务较轻(仅核查评语),一轮训练即可达到高准确率。
Step 3:督导调教老师 (Enhanced Verifier)
使用训练好的元验证器作为奖励模型(Reward Model),重新训练验证器。现在,我们得到了一个既能准确打分,又能写出靠谱评语的增强版验证器。
Step 4:老师教学生 (Generator Optimization)
最后,用增强版验证器作为裁判,通过GRPO训练生成器。强制要求生成器输出**“证明过程 + 自我分析”**。
🔄 关键算法:RFT (Rejection Fine-Tuning) 与闭环迭代
冷启动结束后,如何将这三个模型的经验合而为一?答案是 RFT(拒绝采样微调)。
1. 自动化标注 (Automated Labeling)
系统让生成器解题,验证器进行N次评分,元验证器进行M次仲裁。
- 拒绝采样数据 (1分):高质量数据,老师挑不出毛病。
- 采样数据 (0/0.5分):存在缺陷的数据。
2. 模型融合 (Model Consolidation)
通过RFT,将高质量的“1分数据”喂给模型。这些数据包含三类:
- 验证器产生的正确评判。
- 生成器产生的正确自我分析。
- 元验证器产生的正确监督信号。
结果:经过RFT的模型同时具备了答题、改题、督导三种能力,成为下一轮迭代的“全能基座”。
为什么要先分后合?
- 分(RL阶段):术业有专攻。先让验证器(老师)进化出毒辣的眼光,才能给生成器(学生)提供精准的奖励信号。
- 合(RFT阶段):将RL探索出的短暂“灵感”固化为长久的“本能”,避免模型割裂,让下一轮迭代站在巨人的肩膀上。
♾️ 终极形态:全自动自我进化
完成冷启动后,系统不再需要人类专家。
新数据 -> 自动化标注 -> 练老师 -> 练学生 -> RFT三合一 -> 下一轮循环。
这就是自验证数学推理训练法的精髓:一个无需人工干预、自我造血、自我进化的永动引擎。
这种方法虽然依赖海量的模型调用(生成、验证、仲裁),但配合DeepSeek V3.2的稀疏注意力机制(DSA),调用成本大幅降低了30%-70%。这无疑是DeepSeek在算法与工程优化上的一盘大棋!
延伸阅读:DeepSeek V3.2 DSA机制解读
视频链接:https://www.bilibili.com/video/BV1b8nzzZE7L/

📥 资源下载
DeepSeekMath-V2不仅仅是一个模型,更是算法创新的里程碑。想要深入研究?
- 论文精校翻译版
- DeepSeek本地部署教程
- Agent开发实战
以上资源已上线至赋范大模型技术社区。
加入 赋范空间 ,免费获取以上资源 以及更多前沿大模型硬核技术解析!

















 1032
1032

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









