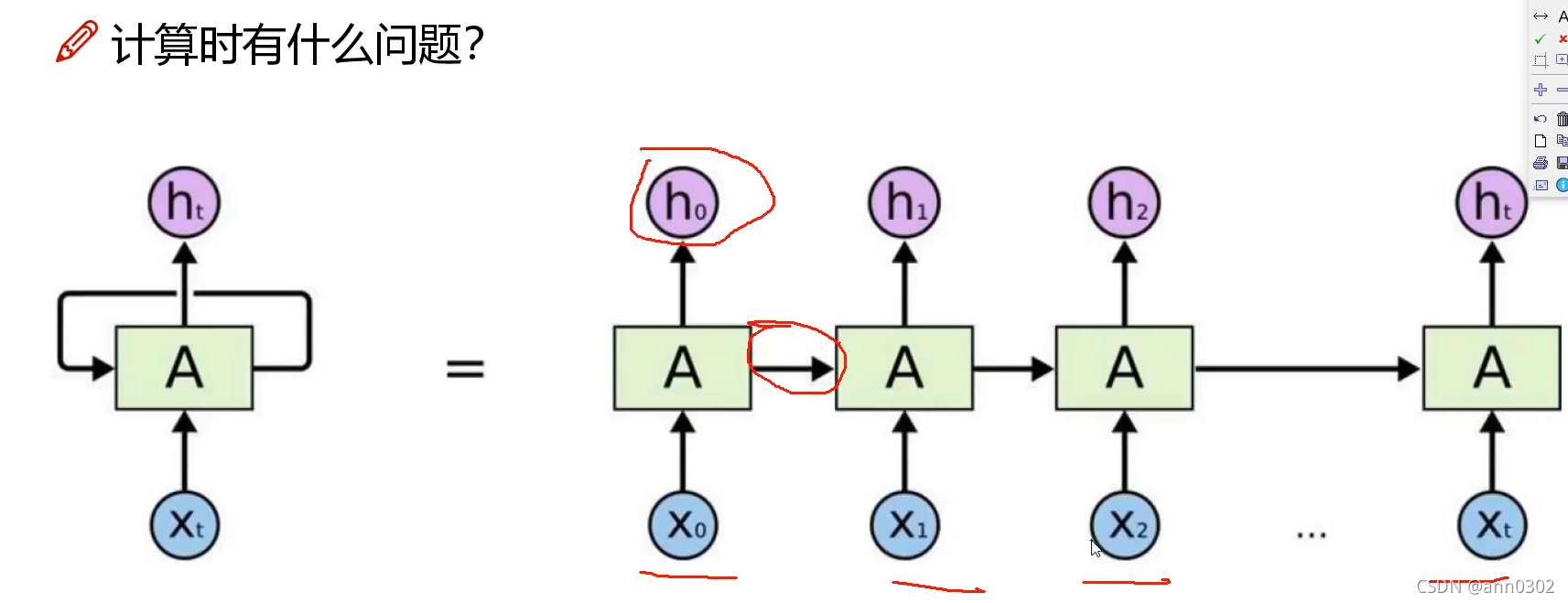
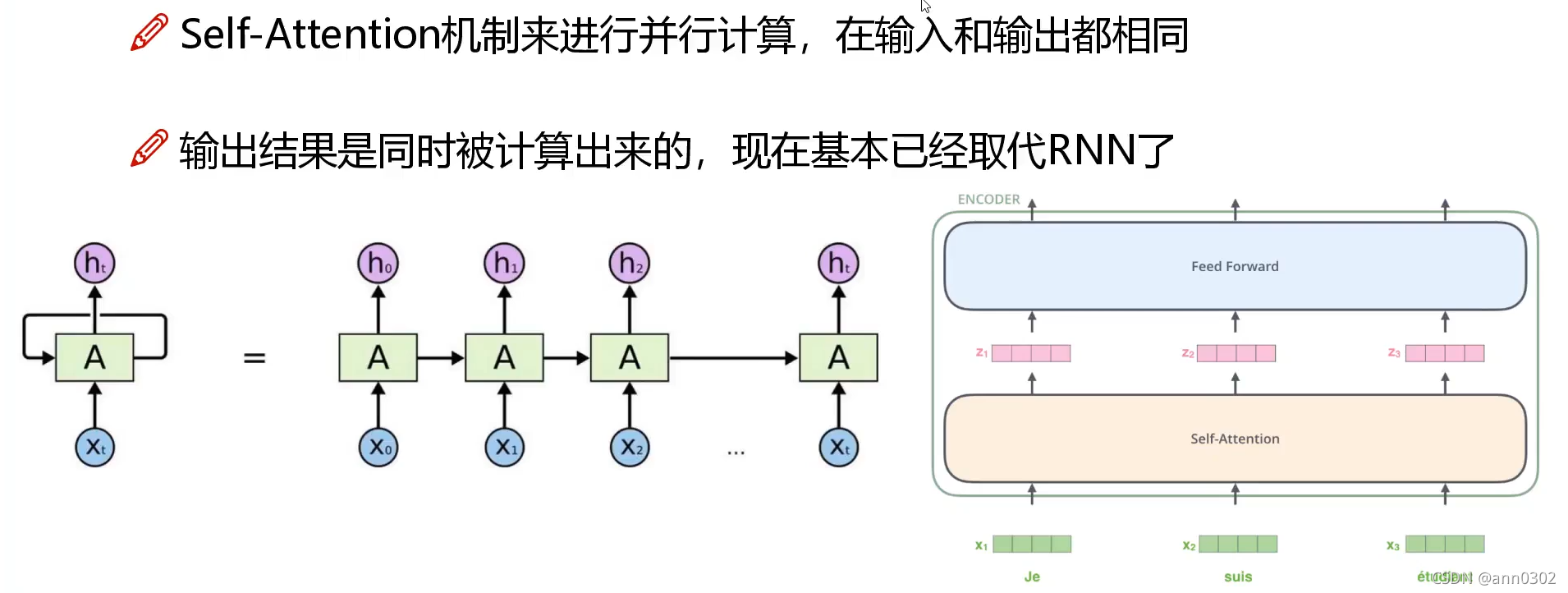
传统的RNN网络 无法并行计算,只能一个一个输入词,而Transformer可以做并行计算。 Transformer Self-Attention 当我们对一个词做编码时,不是简简单单只考虑当前的词,而是要考虑当前词的上下文语境,要把整个上下文语境融入到当前词的词向量中。








 当我们对一个词做编码时,不是简简单单只考虑当前的词,而是要考虑当前词的上下文语境,要把整个上下文语境融入到当前词的词向量中。
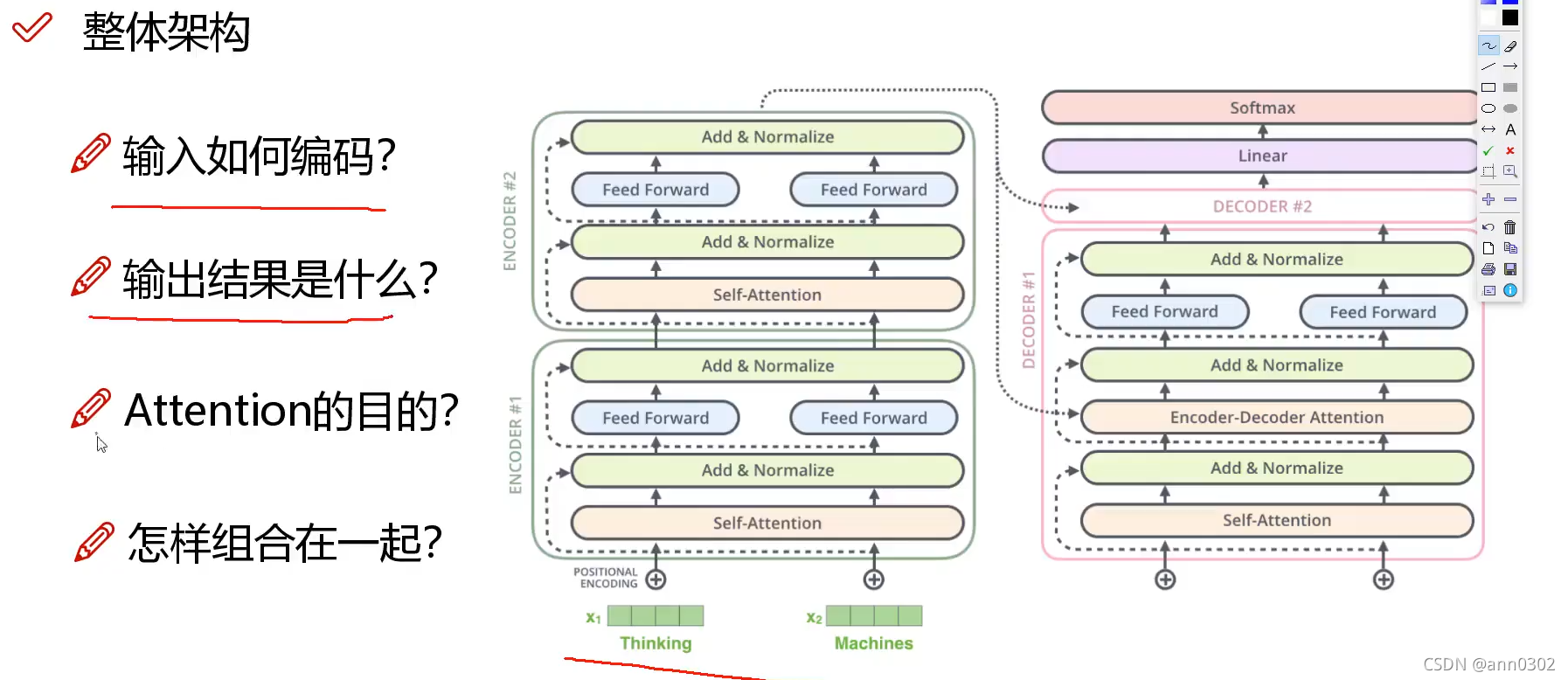
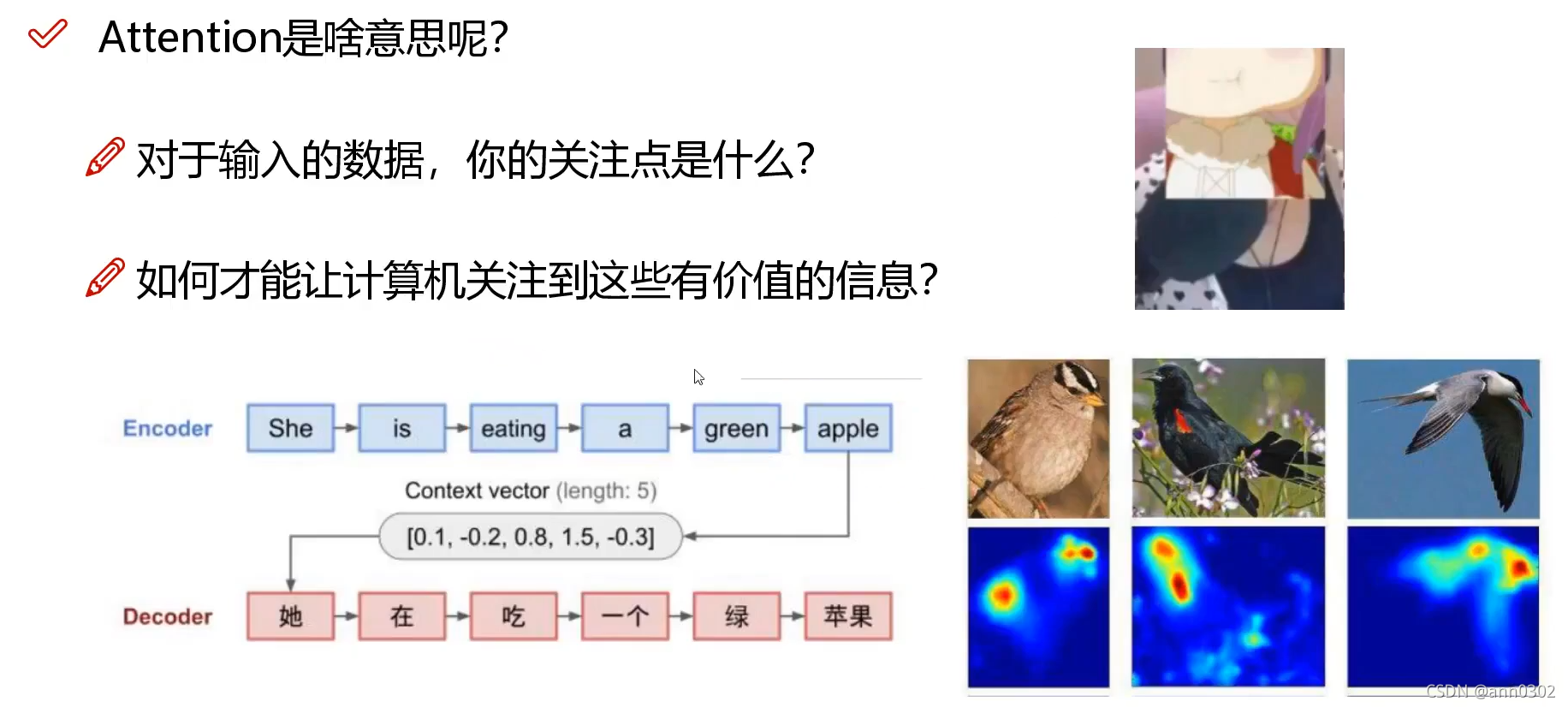
当我们对一个词做编码时,不是简简单单只考虑当前的词,而是要考虑当前词的上下文语境,要把整个上下文语境融入到当前词的词向量中。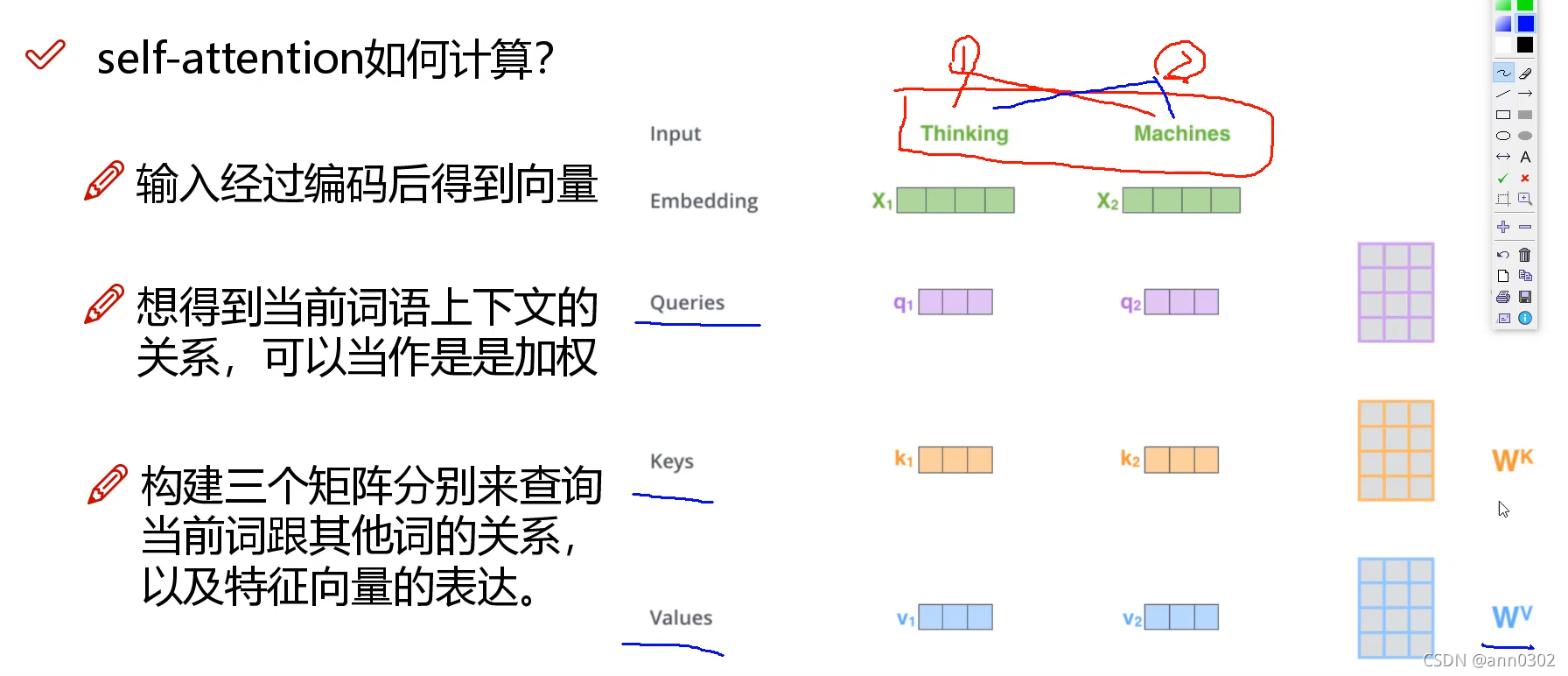
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5057
5057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






