






目标检测介绍
识别分类出物体,定位物体位置画出框;学习获得一个框的起点(x,y)和宽高(h,w),并
基本范式:
sliding widow:遍历图像所有位置
卷积实现密集预测
anchor:设置不同大小和长宽的框
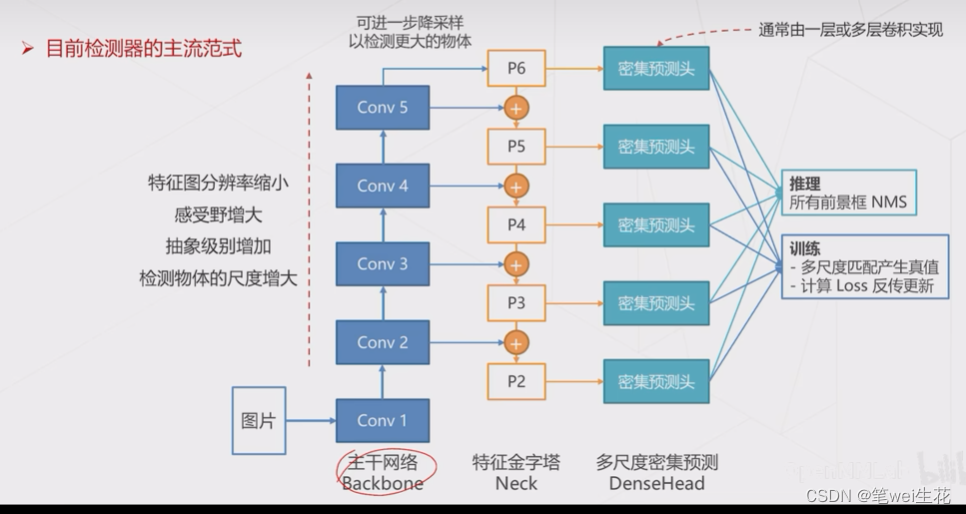
多尺度检测与FPN(特征金字塔)
单阶段和无锚框检测器
RPN
Yolo、SSD
Focal Loss与RetinaNet
FCOS
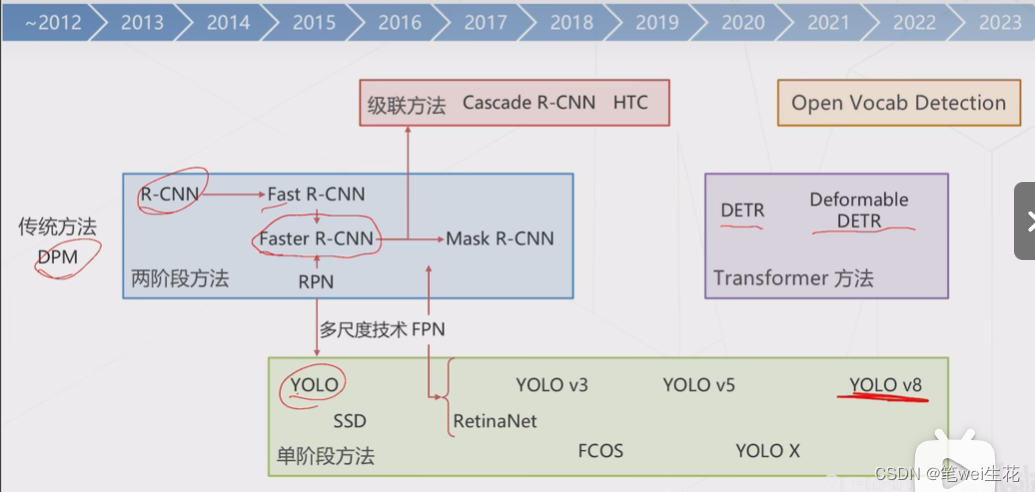
发展过程
评价标准
推理精度
推理速度
模型体积
启发式算法
特征值裁剪
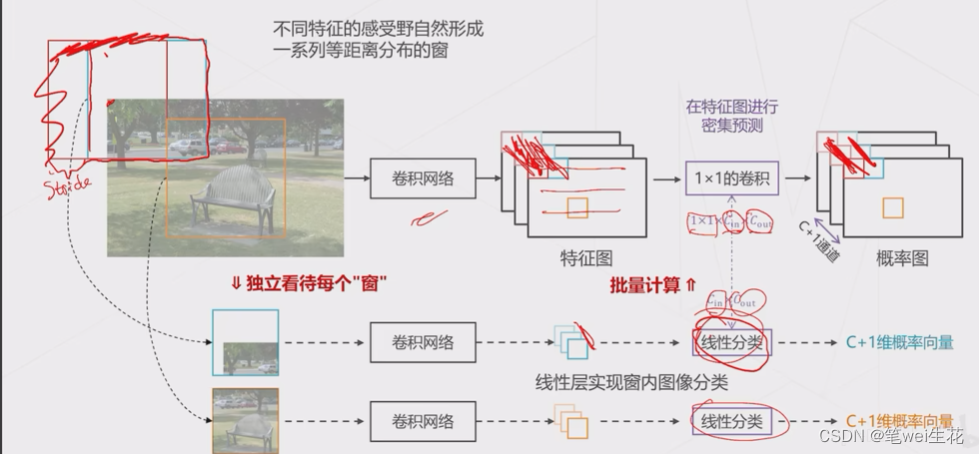
特征图
感受野:神经网络中,一个神经元能看到的原图的区域
感受野的中心:特征图的中心点乘以步长
过程:
非极大值抑制:重叠的框,只需要范围内最大的一个
置信度:选择概率最高的
卷积实现密集预测
基本流程
用模型做密集预测,得到预测图,每个位置包含类别概率、边界框回归的预测结果
保留预测类别不是背景的“框
基于“框”中心,和边界框回归结果,进行边界框解码
后处理: 非极大值抑制(Non-Maximum Suppression)
训练过程(匹配+Loss计算)
检测头在每个位置产生一个预测(有无物体、类别、位置偏移量)
该预测值应与某个真值比较产生损失,进而才可以训练检测器
但这个真值在数据标注中并不存在,标注只标出了有物体的地方我们需要基于稀疏的标注框为密集预测的结果产生真值,这个过程称为匹配(Assignment)
得到结果:C+1维分类概率和四维偏移量(xywh)
匹配
对于每个标注框,在特征图上找到与其最接近的位置(可以不止一个),该位置的分类真值设置为对应的物体
位置的接近程度,通常基于中心位置或者与基准框的 loU判断
其余位置真值为无物体
采样:选取一部分正、负样本计算 Loss (例如可以不计算真值框边界位置的loss)
推理(集合非背景框+NMS)
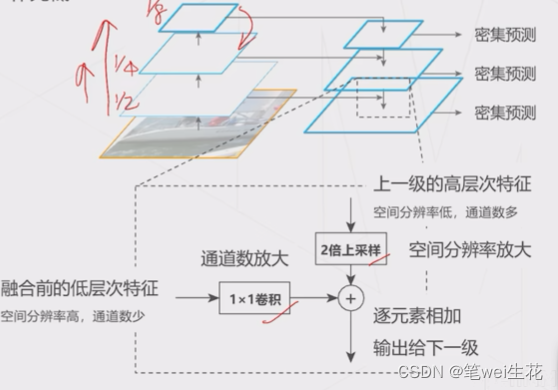
多尺度检测
多个锚框:大中小锚框
图像金字塔:将图像变为不同大小
基于层次化(特征金字塔):低层次特征抽象级别不够,预测困难,融入高层特征(特征求和)
单阶段
Region Proposal Network : 初步筛选出图像中包含物体的位置
基于IOU的匹配:
1.将所有的框设置为背景
2.将背景框的iou设置为0
3.临近的框相似,则合并,最接近的ground truth大于正样本的iou阈值
4.将所有的背景框合并
Yolo:
计算边界框回归损失、置信度回归损失、C个类别概率的回归损失
多阶段
SSD:single shot multibox detector
RetinaNet:引入了FPN
Focal Loss: 解决正负样本不均衡问题
无锚框检测器
锚框:解决重叠物体
FCOS: Fully convolutional one-stage

CenterNet

















 1221
1221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









