







 该博客详细介绍了如何使用PyTorch构建U-Net模型,包括DoubleConv、Down、Up和OutConv等关键模块的实现,以及自定义数据集的读取方法。同时,提到了Dice损失函数在语义分割任务中的应用。代码示例展示了网络结构和数据预处理过程。
该博客详细介绍了如何使用PyTorch构建U-Net模型,包括DoubleConv、Down、Up和OutConv等关键模块的实现,以及自定义数据集的读取方法。同时,提到了Dice损失函数在语义分割任务中的应用。代码示例展示了网络结构和数据预处理过程。
目录
【视频讲解】:使用Pytorch搭建U-Net网络并基于DRIVE数据集训练(语义分割)
U-Net 模型
使用双线性插值代替原论文的转置卷积。
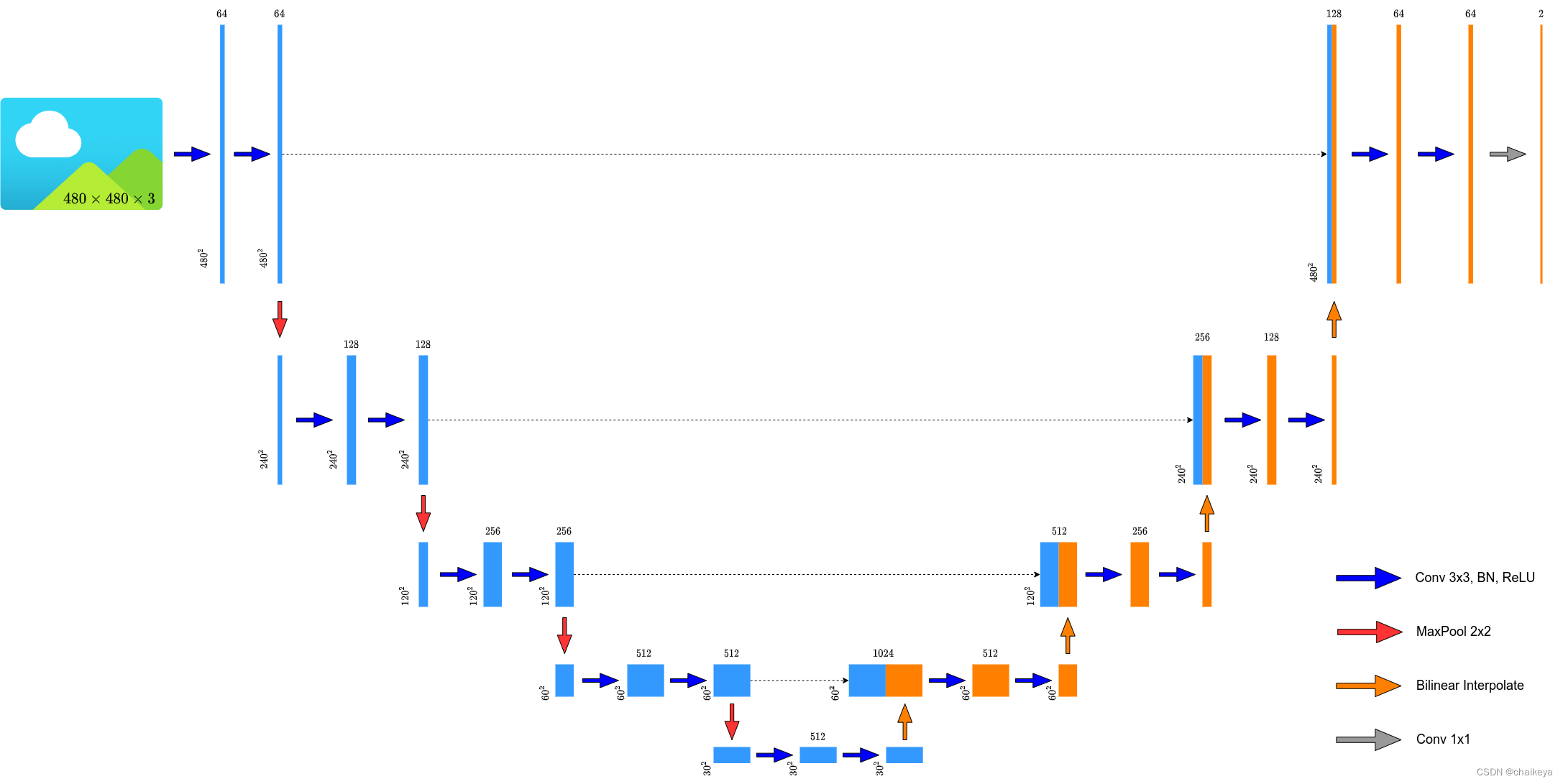
unet.py 网络的搭建
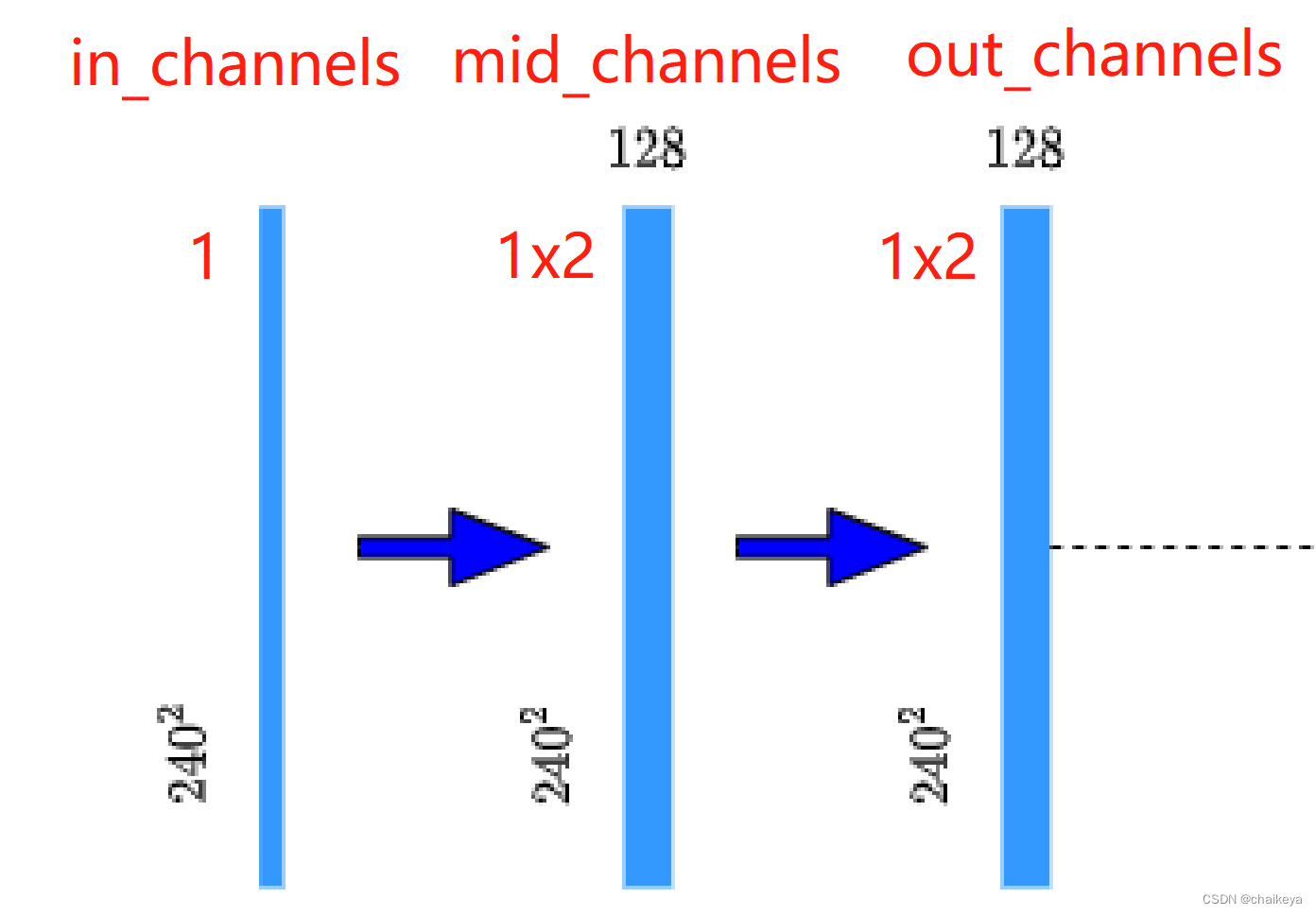
1、首先,定义一个DoubleConv模块,里面包含两个(卷积+BN+Relu)的组合。
参数:in_channels,out_channels,还有一个中间参数mid_channels;
对应网络中两个蓝箭头的操作。
contracting path:
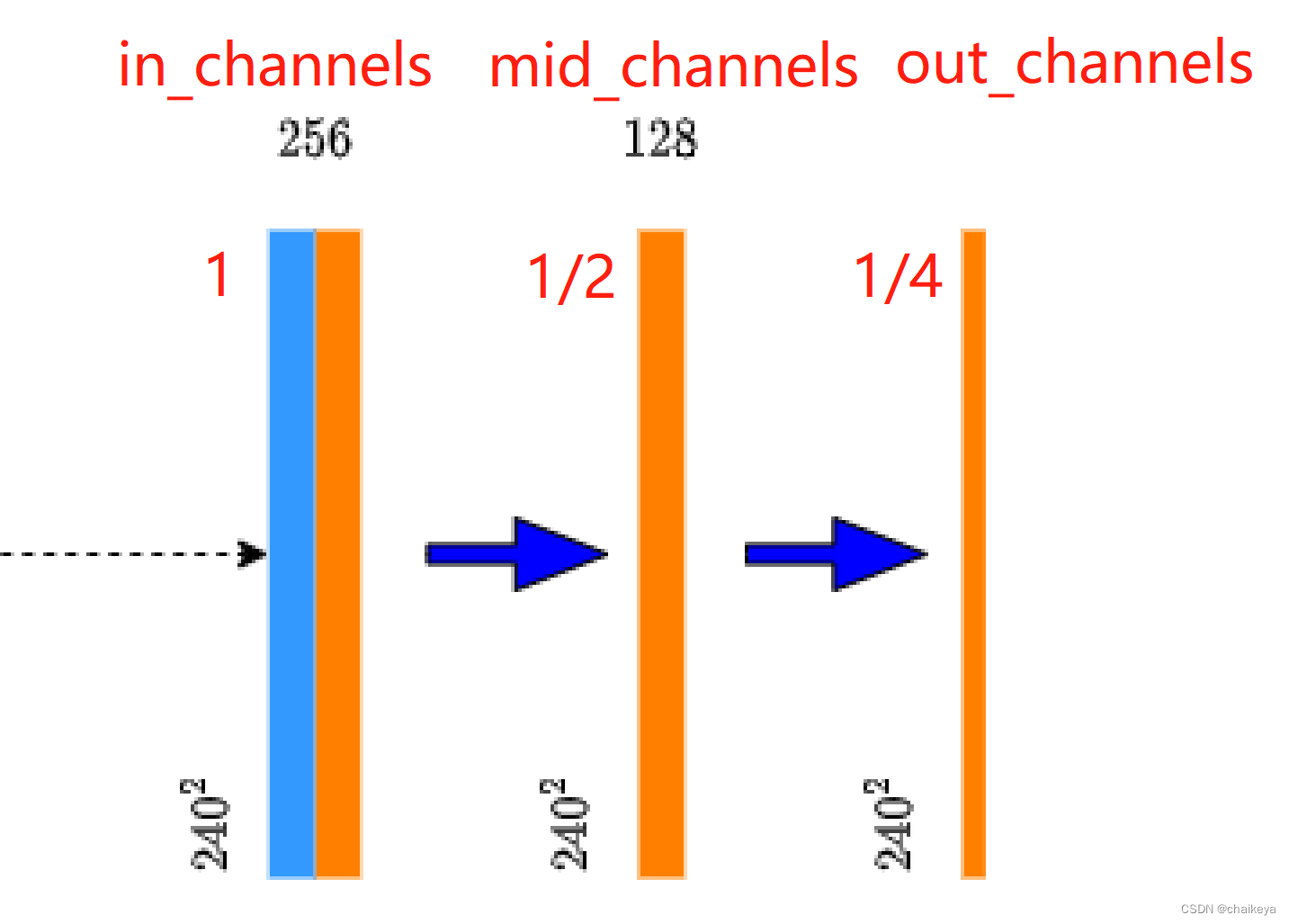
expanding path:
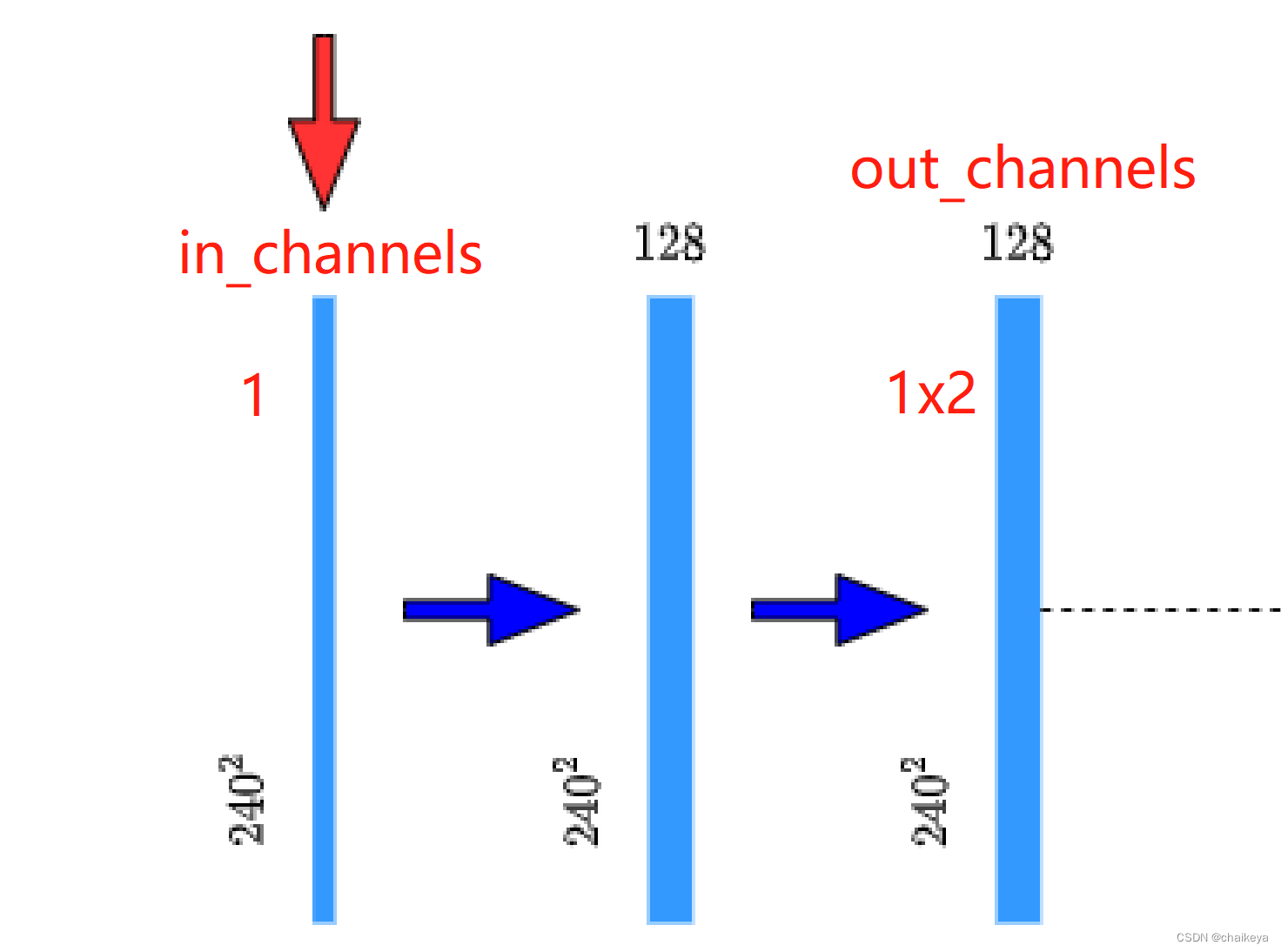
2、定义一个Down模块,里面包含(下采样+DoubleConv)。
参数:in_channels,out_channels。
3、定义一个Up模块,里面包含(上采样+ context拼接+两个卷积层)
参数:in_channels,out_channels,默认bilinear=True(上采样时使用双线性插值替代转置卷积)
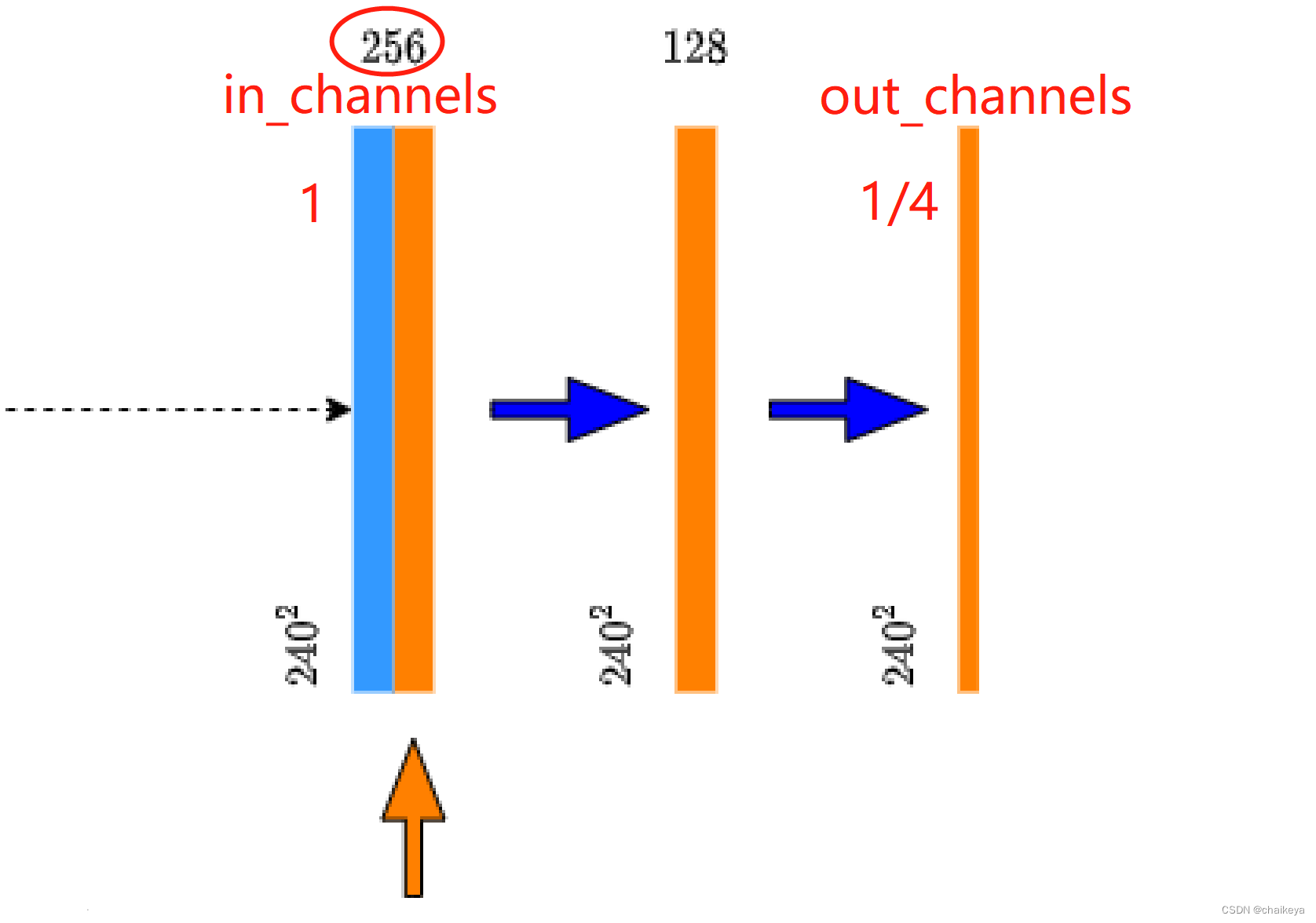
原论文上采样使用转置卷积的方法。
双线性插值:得到特征矩阵的channel(图中1)和context拼接的特征矩阵channel(图中2)一致。
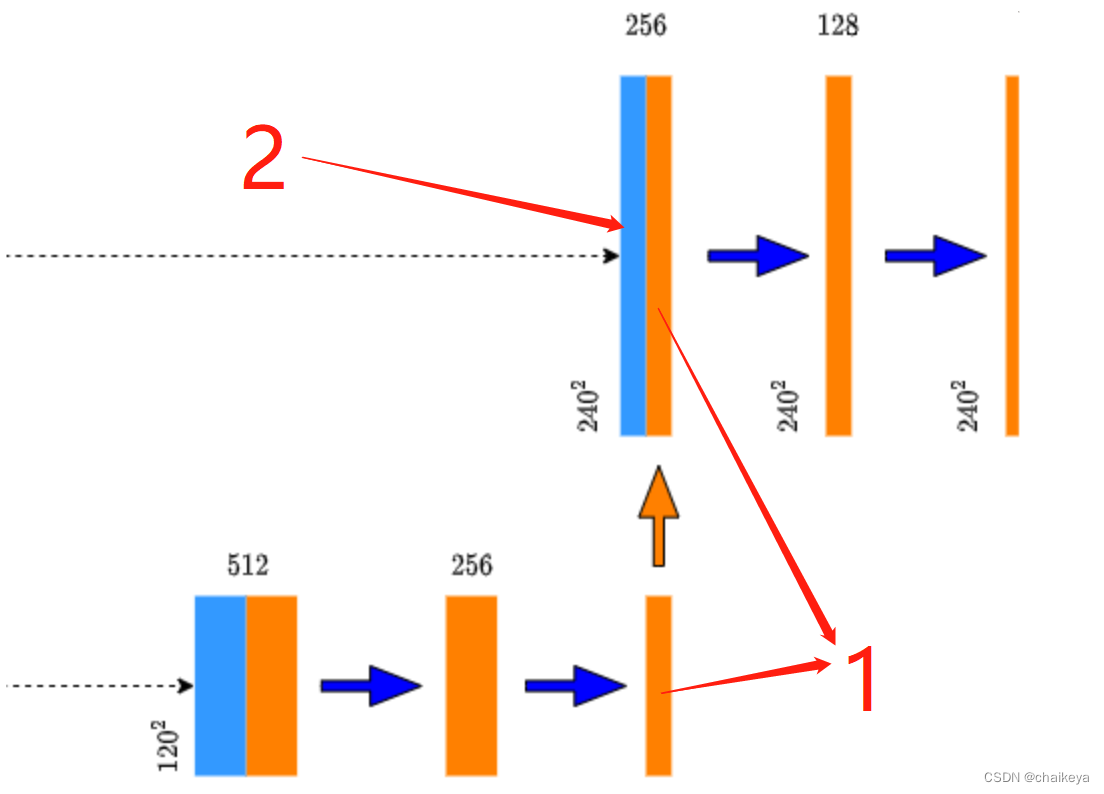
4、定义一个OutConv模块,包含一个1x1的卷积层,没有激活函数。
参数:in_channels,,num_classes(分割任务当中的分类类别个数)
5、定义UNet模型
初始化,赋值,DoubleConv,Down,Down,Down,Down,Up,Up,Up,Up,OutConv。
unet.py 代码
from typing import Dict
import torch
import torch.nn as nn
import torch.nn.functional as F
class DoubleConv(nn.Sequential):
def __init__(self, in_channels, out_channels, mid_channels=None):
if mid_channels is None: # 如果没有定义中间层channel则和输出层的channel一样
mid_channels = out_channels
# 调用父类方法中的initial方法。
# 加入BN层所以bias=0.
super(DoubleConv, self).__init__(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
class Down(nn.Sequential):
def __init__(self, in_channels, out_channels):
# 下采样maxpool,kernel_size=2,stride=2.
super(Down, self).__init__(
nn.MaxPool2d(2, stride=2),
DoubleConv(in_channels, out_channels)
)
# 上采样 + context拼接 + 两个卷积层
class Up(nn.Module):
# in_channels对应context拼接后的特征层个数,bilinear是否使用双线性插值替代转置卷积
def __init__(self, in_channels, out_channels, bilinear=True):
super(Up, self).__init__()
if bilinear: # 双线性插值,得到特征矩阵的channel和context拼接的特征矩阵channel一致
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else: # 转置卷积
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
# x2:拼接的特征层
def forward(self, x1: torch.Tensor, x2: torch.Tensor) -> torch.Tensor:
x1 = self.up(x1)
# [N, C, H, W]
diff_y = x2.size()[2] - x1.size()[2] # 高度方向上的差值
diff_x = x2.size()[3] - x1.size()[3] # 宽度方向上的差值
# pad保证上采样后的图片和context拼接图片的高和宽相等,且是16的整数倍
# padding_left, padding_right, padding_top, padding_bottom
x1 = F.pad(x1, [diff_x // 2, diff_x - diff_x // 2,
diff_y // 2, diff_y - diff_y // 2])
x = torch.cat([x2, x1], dim=1)
x = self.conv(x)
return x
class OutConv(nn.Sequential):
def __init__(self, in_channels, num_classes):
super(OutConv, self).__init__(
nn.Conv2d(in_channels, num_classes, kernel_size=1)
)
class UNet(nn.Module):
def __init__(self,
in_channels: int = 1, # 实例化时,传入彩色图片=3
num_classes: int = 2, # 分割任务当中的分类类别个数
bilinear: bool = True, # bilinear是否使用双线性插值替代转置卷积
base_c: int = 64): # 第一个卷积层所采用的卷积核的个数
super(UNet, self).__init__()
self.in_channels = in_channels
self.num_classes = num_classes
self.bilinear = bilinear
self.in_conv = DoubleConv(in_channels, base_c)
self.down1 = Down(base_c, base_c * 2)
self.down2 = Down(base_c * 2, base_c * 4)
self.down3 = Down(base_c * 4, base_c * 8)
# bilinear=true,bilinear=2,双线性插值法:第四个down模块输入和输出channel不变
# bilinear=false,bilinear=1,转置卷积法:第四个down模块输出channel是输入的两倍
factor = 2 if bilinear else 1
self.down4 = Down(base_c * 8, base_c * 16 // factor)
self.up1 = Up(base_c * 16, base_c * 8 // factor, bilinear)
self.up2 = Up(base_c * 8, base_c * 4 // factor, bilinear)
self.up3 = Up(base_c * 4, base_c * 2 // factor, bilinear)
self.up4 = Up(base_c * 2, base_c, bilinear)
self.out_conv = OutConv(base_c, num_classes)
def forward(self, x: torch.Tensor) -> Dict[str, torch.Tensor]:
x1 = self.in_conv(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.out_conv(x) # 1x1卷积
return {"out": logits} # 字典的形式返回
my_dataset.py 自定义数据集读取
import os
from PIL import Image
import numpy as np
from torch.utils.data import Dataset
class DriveDataset(Dataset):
# root:指向根目录。//train:布尔类型,ture,载入training下的数据,false.载入test下的数据。//transforms:数据预处理方式
def __init__(self, root: str, train: bool, transforms=None):
super(DriveDataset, self).__init__()
self.flag = "training" if train else "test"
data_root = os.path.join(root, "DRIVE", self.flag)
# 判断当前路径是否存在,如果不存在会报错
assert os.path.exists(data_root), f"path '{data_root}' does not exists."
self.transforms = transforms
# 遍历目录下的 images图片,如果是以.tif结尾的话就保留它。得到每张图片的名称,并不是路径
img_names = [i for i in os.listdir(os.path.join(data_root, "images")) if i.endswith(".tif")]
# 遍历每张图片的名称+根目录就可以得到每张图片的路径。
self.img_list = [os.path.join(data_root, "images", i) for i in img_names]
# 得到 manual文件夹下每个图片的路径
self.manual = [os.path.join(data_root, "1st_manual", i.split("_")[0] + "_manual1.gif")
for i in img_names]
# check files,看 manual文件夹下每张图片是否存在。
for i in self.manual:
if os.path.exists(i) is False:
raise FileNotFoundError(f"file {i} does not exists.")
# 得到 mask文件夹下每个图片的路径
self.roi_mask = [os.path.join(data_root, "mask", i.split("_")[0] + f"_{self.flag}_mask.gif")
for i in img_names]
# check files,看 mask文件夹下每张图片是否存在。
for i in self.roi_mask:
if os.path.exists(i) is False:
raise FileNotFoundError(f"file {i} does not exists.")
def __getitem__(self, idx):
# 打开images文件夹下的图片,convert成RGB图片。
img = Image.open(self.img_list[idx]).convert('RGB')
# 打开manual文件夹下的图片,convert成灰度图片。
manual = Image.open(self.manual[idx]).convert('L')
# 在语义分割任务当中,背景为0,前景(目标)要从1开始。
# 在DRIVE数据集中原本前景血管255,背景0。但是只有一个前景,就把它转化为numpy再除以255,这样前景像素值为1,背景还是为0.
manual = np.array(manual) / 255
roi_mask = Image.open(self.roi_mask[idx]).convert('L')
# 感兴趣的区域变成0,不感兴趣的区域变成255,计算损失时将像素值为255的区域忽略掉。
roi_mask = 255 - np.array(roi_mask)
mask = np.clip(manual + roi_mask, a_min=0, a_max=255)
# 这里转回PIL的原因是,transforms中是对PIL数据进行处理
mask = Image.fromarray(mask)
if self.transforms is not None:
img, mask = self.transforms(img, mask)
return img, mask
# 返回当前数据集中数据的一个数目。
def __len__(self):
return len(self.img_list)
@staticmethod
def collate_fn(batch):
images, targets = list(zip(*batch))
batched_imgs = cat_list(images, fill_value=0)
batched_targets = cat_list(targets, fill_value=255)
return batched_imgs, batched_targets
def cat_list(images, fill_value=0):
max_size = tuple(max(s) for s in zip(*[img.shape for img in images]))
batch_shape = (len(images),) + max_size
batched_imgs = images[0].new(*batch_shape).fill_(fill_value)
for img, pad_img in zip(images, batched_imgs):
pad_img[..., :img.shape[-2], :img.shape[-1]].copy_(img)
return batched_imgs
Dice loss 损失计算
Dice similarity coefficient用于度量两个集合的相似性:
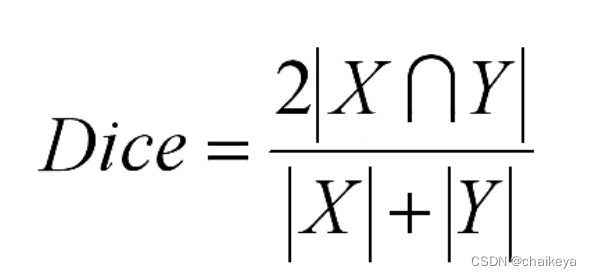
在语义分割任务当中X和Y的范围都是[0,1],那么Dice的范围也是[0,1]。
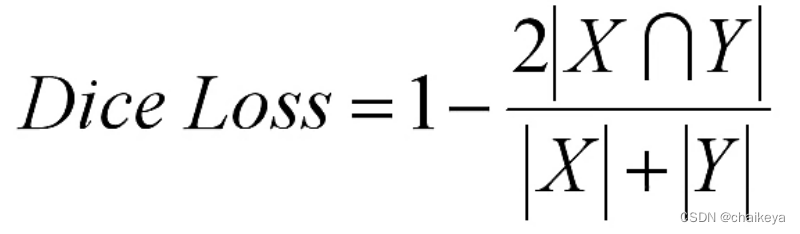
前景的Dice计算:
先预测前景概率,然后得到前景GT标签。
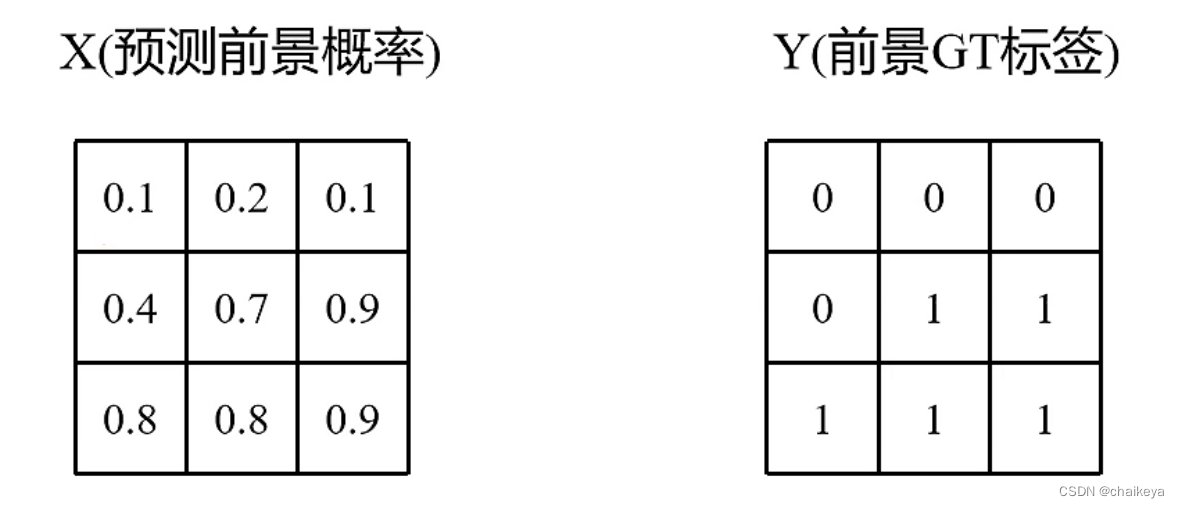
分子:相应元素相乘再相加
分母:两个矩阵分别求和再相加
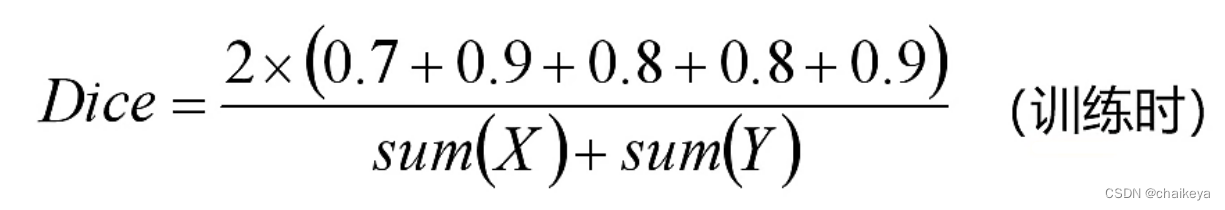
总的Dice计算:
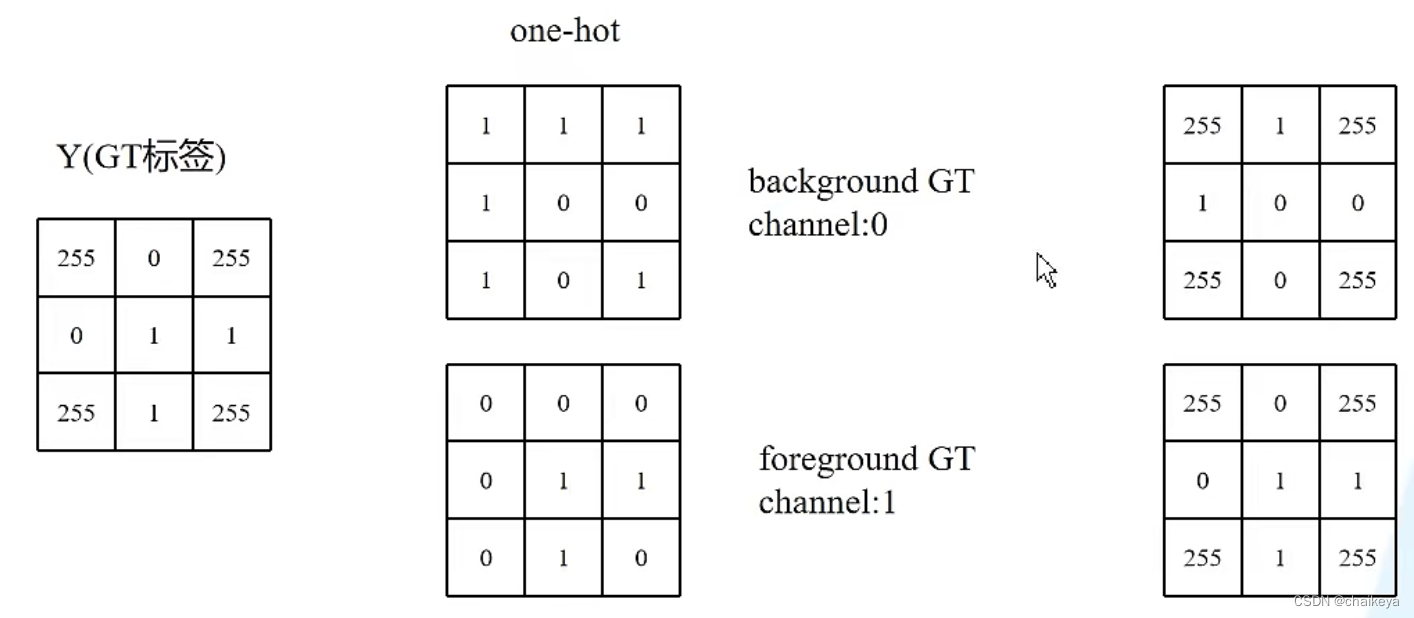
1、将255的区域变为0.
255:要忽略的区域。 //1:前景,要分割的区域(血管),计算的区域。 //0:背景。
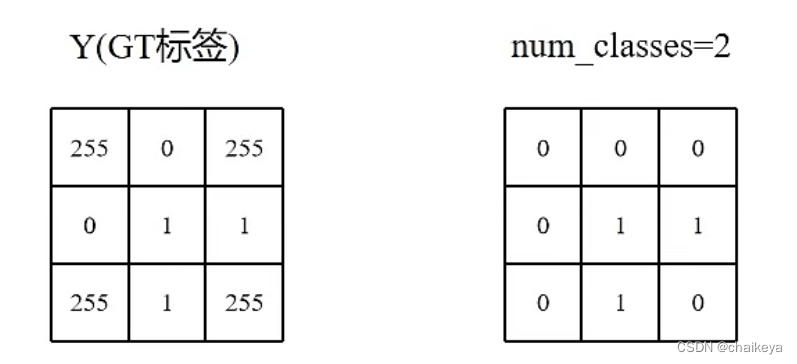
2、原始GT转化为每个类别的GT。
每个类别分别计算Dice系数,然后取均值,one-hot编码的形式为每个类别构建GT。
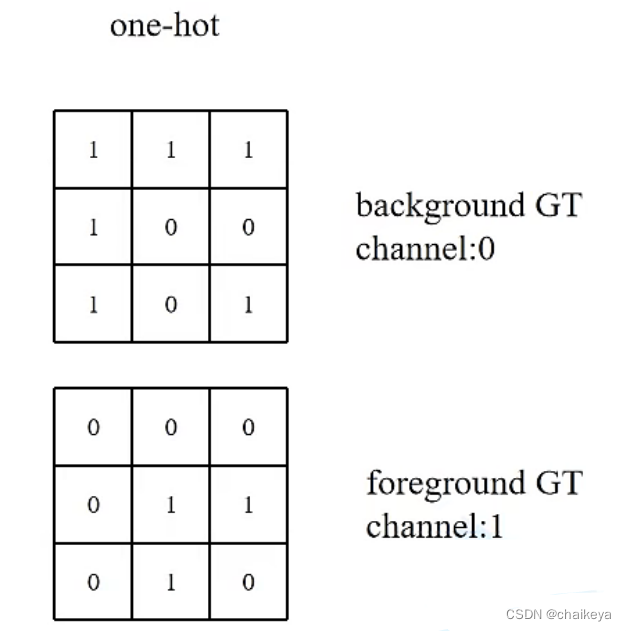
3、将255对应的区域重新填回去。
计算每个类别的Dice similarity coefficient时只计算非255的区域。
nn.Sequential
简而言之,nn.Sequential()可以将一系列的操作打包,这些操作可以包括Conv2d()、ReLU()、Maxpool2d()等,打包后方便调用吧,就相当于是一个黑箱,forward()时调用这个黑箱就行了。

















 1515
1515

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









