







深度学习基础知识
一、ReLU函数
激活函数
不是用来激活什么,而是把特征保留并映射到对应的分类标签上
![]()
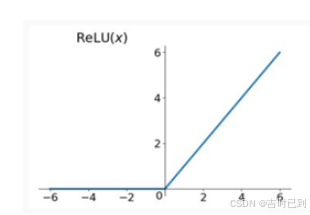
个人理解就是一个二极管,用来对数据进行分类
把大于0的数据都保留,而小于0的数据直接清零
二、卷积和反卷积(上采样)
可以把相对应的图像特征提取出来,如图像的边缘特征、纹理特征
3×3卷积核对图片的卷积过程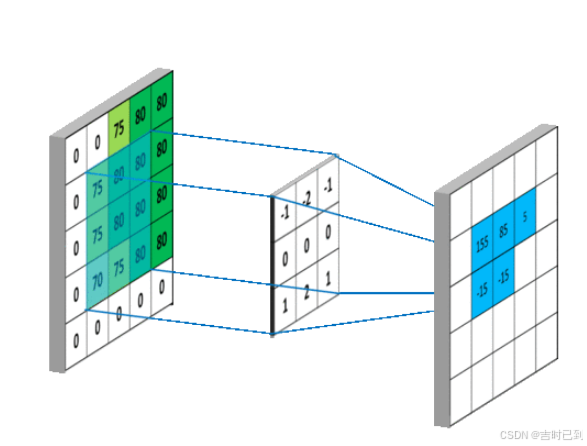
为什么卷积可以把相对应的图像特征提取出来,如图像的边缘特征、纹理?
为什么卷积能够提取图像的特征?看完此文应该能够给你一个答案;_卷积为什么能提取特征-优快云博客 https://blog.youkuaiyun.com/charleswangzi/article/details/82733016
https://blog.youkuaiyun.com/charleswangzi/article/details/82733016
卷积核实际上就是一系列具有特定分布的权重矩阵
图像经过卷积后得到的新的图像特征,然后根据新的图像特征就可以判断出原图的权重(相似程度)分布
卷积的相关参数
卷积层的参数主要包括
卷积核(filter)
步长(stride):卷积核滑动的步数,影响输出尺寸
填充(padding):在输入数据边界添加额外值,防止输出尺寸过小
输入输出通道数(in_channel/out_channel):输入数据的通道数和卷积操作后生成的特征图的通道数
卷积核的大小
卷积核大小不同,所得到的卷积结果不同

反卷积
是特殊的卷积(也就是full卷积),将原图扩大,增大原图的分辨率

反卷积只能恢复尺寸,不能恢复数值
反卷积为什么能被称作转置卷积
对图像进行反卷积也称为对图像进行“上采样”(放大图像)
三、池化层(下采样)
主要是用来减少参数,类似与反卷积
个人理解就是,将图像进行缩小
常用的池化层,有两种 最大池化,平均池化

U-net学习理解
用于医学图像分割,可以实现图片像素的定位,该网络对图像中的每一个像素点进行分类,最后输出的是根据像素点的类别而分割好的图像
输出特征图边长公式
H×W(高度和宽度),卷积核的尺寸为 K×K,填充(padding)为 P,步长(stride)为 S
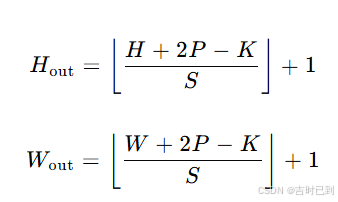
u-net架构
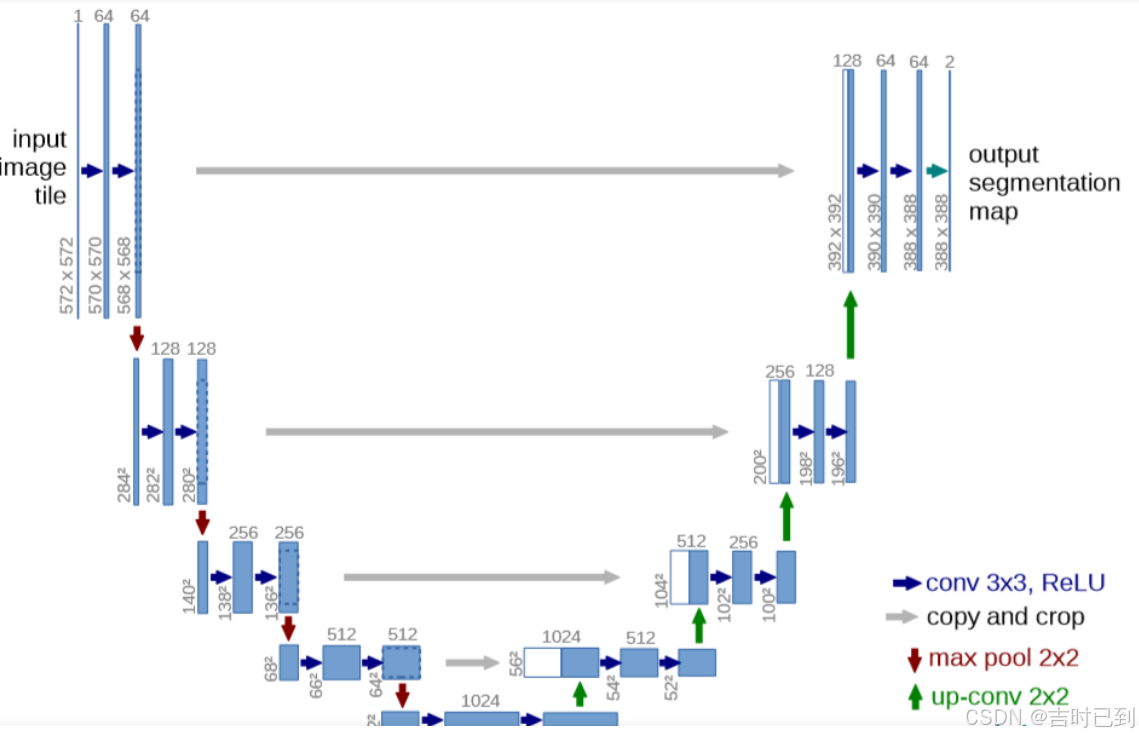
为什么要有跳跃拼接(Skip Connection)中的“Copy and Crop”操作?
进行拼接,可以对低级特征进行保留(编码器的过程中),通过拼接直接传递到解码器,避免了信息丢失
这个拼接是在chanel层面进行拼接
经过反卷积后,图像尺寸扩大,通道缩小(卷积核缩小)
输入一张572×572×1的图片,因为chanel从1变成了64,所以可以知道使用了64个3×3的卷积核进行卷积,再通过ReLU函数后得到64个570×570×1的特征通道
每下采样一层,都会把图片减小一半,卷积核数目增加一倍
最终下采样部分的结果是28×28×1024,也就是一共有1024个特征层,每一层的特征大小为28×28
最后上采样的结果是388×388×64,也就是一共有64个特征层,每一层的特征大小为388×388
在最后一步中,选择了2x1x1的卷积核把64个特征通道变成2个,也就是最后的388×388×2,其实这里就是一个二分类的操作,把图片分成背景和目标两个类别
第一个通道表示每个像素属于背景类的概率
第二个通道表示每个像素属于目标类的概率
生成对抗网络GAN
模型通过框架中(至少)两个模块:生成模型(Generative Model)和判别模型(Discriminative Model)的互相博弈学习产生相当好的输出。
GAN算法流程原理

判别模型和生成模型
生成模型(Generative Model):生成模型是给定某种隐含信息,来随机产生观测数据
给一系列猫的图片,生成一张新的猫咪
判别模型(Discriminative Model):判别模型需要输入变量 ,通过某种模型来预测
给定一张图,判定图中的动物是什么类别
在训练过程中,G(Generative )和D(Discriminative )构成了一个动态的“博弈过程”
生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而D的目标就是尽量把G生成的图片和真实的图片分别开来
生成器

判别器

GAN 的训练

1.在噪声数据分布中随机采样,输入生成模型,得到一组假数据,记为D(z) 2.在真实数据分布中随机采样,作为真实数据,记做x; 将前两步中某一步产生的数据作为判别网络的输入(因此判别模型的输入为两类数据,真/假),判别网络的输出值为该输入属于真实数据的概率,real为1,fake为0. 3.然后根据得到的概率值计算损失函数; 4.根据判别模型和生成模型的损失函数,可以利用反向传播算法,更新模型的参数。(先更新判别模型的参数,然后通过再采样得到的噪声数据 更新生成器的参数)

















 2223
2223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









