







 本文介绍了如何使用字典树数据结构解决单词查询问题,包括输入字典大小、查询单词列表,以及如何通过递归实现查找、插入操作。通过实例展示了查找和不存在单词的输出结果,同时概述了字典树在文本处理、排序和统计中的应用。
本文介绍了如何使用字典树数据结构解决单词查询问题,包括输入字典大小、查询单词列表,以及如何通过递归实现查找、插入操作。通过实例展示了查找和不存在单词的输出结果,同时概述了字典树在文本处理、排序和统计中的应用。
Description
遇到单词不认识怎么办? 查字典啊,已知字典中有n个单词,假设单词都是由小写字母组成。现有m个不认识的单词,询问这m个单词是否出现在字典中。
Input
含有多组测试用例。
第一行输入n,m (n>=0&&n<=100000&&m>=0&&m<=100000)分别是字典中存在的n个单词和要查询的m个单词.
紧跟着n行,代表字典中存在的单词。
然后m行,要查询的m个单词
n=0&&m=0 程序结束
数据保证所有的单词都是有小写字母组成,并且长度不超过10
Output
若存在则输出Yes,不存在输出No .
Sample
Input
3 2 aab aa ad ac ad 0 0
Output
No Yes
| Time Limit | 2000 ms |
| Mem. Limit | 131072 KiB |
| Source | gyx |
Hint
字典树的简单介绍
又称单词查找树,Trie树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,它的核心思想是空间换时间,空间消耗大但是插入和查询有着很优秀的时间复杂度。
先回顾一下树形结构
树形结构-- 一对多的关系
数据结构中,使用树形结构表示数据表素之间一对多的关系,树形结构是一种非线型结构。
定义:
树(Tree)是n(n≥0)个相同数据类型的数据元素的集合.树中的数据元素称为节点(Node).。n=0的树称为空树(Empty Tree);对于n>0的任意非空树T有:
(1)有且仅有一个特殊的结点称为树的根(Root)结点,根没有前驱结点;
(2)若n>1,则除根结点外,其余结点被分成了m(m>0)个互不相交的集合T1,T2,…,Tm,其中每一个集合Ti(1≤i≤m)本身又是一棵树。树T1,T2,…,Tm称为这棵树的子树(Subtree)。
由树的定义可知,树的定义是递归的,用树来定义树。因此,树(以及二叉树)的许多算法都使用了递归。
树的形式定义为:树(Tree)简记为T,是一个二元组,
T = (D, R)
其中:D是结点的有限集合;
R是结点之间关系的有限集合。
树具有下面两个特点:
(1)树的根结点没有前驱结点,除根结点之外的所有结点有且只有一个前驱结点。
(2)树中的所有结点都可以有零个或多个后继结点。
实际上,第(1)个特点表示的就是树形结构的“一对多关系”中的“一”,第(2)特点表示的是“多”。

树的相关术语:
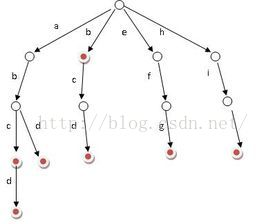
1、结点(Node):表示树中的数据元素,由数据项和数据元素之间的关系组成。在图中,共有10个结点。
2、结点的度(Degree of Node):结点所拥有的子树的个数,在图中,结点A的度为3。
3、树的度(Degree of Tree):树中各结点度的最大值。在图5.1中,树的度为3。
4、叶子结点(Leaf Node):度为0的结点,也叫终端结点。在图5.1中,结点E、F、G、H、I、J都是叶子结点。
5、分支结点(Branch Node):度不为0的结点,也叫非终端结点或内部结点。在图5.1中,结点A、B、C、D是分支结点。
6、孩子(Child):结点子树的根。在图中,结点B、C、D是结点A的孩子。
7、双亲(Parent):结点的上层结点叫该结点的双亲。在图中,结点B、C、D的双亲是结点A。
8、祖先(Ancestor):从根到该结点所经分支上的所有结点。在图中,结点E的祖先是A和B。
9、子孙(Descendant):以某结点为根的子树中的任一结点。在图中,除A之外的所有结点都是A的子孙。
10、兄弟(Brother):同一双亲的孩子。在图5.1中,结点B、C、D互为兄弟。
11、结点的层次(Level of Node):从根结点到树中某结点所经路径上的分支数称为该结点的层次。根结点的层次规定为1,其余结点的层次等于其双亲结点的层次加1。
12、堂兄弟(Sibling):同一层的双亲不同的结点。在图中,G和H互为堂兄弟。
13、树的深度(Depth of Tree):树中结点的最大层次数。在图5.1中,树的深度为3。
14、无序树(Unordered Tree):树中任意一个结点的各孩子结点之间的次序构成无关紧要的树。通常树指无序树。
15、有序树(Ordered Tree):树中任意一个结点的各孩子结点有严格排列次序的树。二叉树是有序树,因为二叉树中每个孩子结点都确切定义为是该结点的左孩子结点还是右孩子结点。
16、森林(Forest):m(m≥0)棵树的集合。自然界中的树和森林的概念差别很大,但在数据结构中树和森林的概念差别很小。从定义可知,一棵树有根结点和m个子树构成,若把树的根结点删除,则树变成了包含m棵树的森林。当然,根据定义,一棵树也可以称为森林。
树的逻辑表示
字典树它有3个基本性质:
1,根结点不包含任何字符信息;
2,如果字符的种数为n,则每个结点的出度为n(这样必然会导致浪费很多空间,这也是trie的缺点);
3,查找,插入复杂度为O(n),n为字符串长度。
基本操作
其基本操作有:查找、插入和删除,当然删除操作比较少见。
搜索字典项目的方法为:
(1) 从根结点开始一次搜索; (2) 取得要查找关键词的第一个字母,并根据该字母选择对应的子树并转到该子树继续进行检索; (3) 在相应的子树上,取得要查找关键词的第二个字母,并进一步选择对应的子树进行检索。 (4) 迭代过程…… (5) 在某个结点处,关键词的所有字母已被取出,则读取附在该结点上的信息,即完成查找。 其他操作类似处理
字典树的应用:
1.串的快速检索
给出N个单词组成的熟词表,以及一篇全用小写英文书写的文章,请你按最早出现的顺序写出所有不在熟词表中的生词。 在这道题中,我们可以用数组枚举,用哈希,用字典树,先把熟词建一棵树,然后读入文章进行比较,这种方法效率是比较高的。
2.“串”排序
给定N个互不相同的仅由一个单词构成的英文名,让你将他们按字典序从小到大输出 用字典树进行排序,采用数组的方式创建字典树,这棵树的每个结点的所有儿子很显然地按照其字母大小排序。对这棵树进行先序遍历即可。
3.最长公共前缀
对所有串建立字典树,对于两个串的最长公共前缀的长度即他们所在的结点的公共祖先个数,于是,问题就转化为当时公共祖先问题。
这里补充一下,其实对于查找单词和统计前缀出现次数时也可以用map函数,但当要统计的单词数目较大时就会TLE。但map函数还是很实用的一种函数,建议大家私下去学习了解一下,这里我就不细讲了。
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
//静态字典树,模拟字典树的动态内存分配
struct node{
int data;//记录出现了几次,这个字符串
struct node *next[26];//26个字母,二十六个孩子
}roots[1000000];//静态内存//适合数据特别多时,申请动态链表会超时内存
int top;
struct node *create(){
struct node *root;
root = &roots[top++];
int i;
//root = (struct node*)malloc(sizeof(struct node));
for(i = 0; i < 26; i++){
root -> next[i] = NULL;
}
root -> data = 0;
return root;
}
void insert(struct node *root, char word[]){
int lword;
int pos;
int i;
lword = strlen(word);
for(i = 0; i < lword; i++){//将字符串的字符一个一个放入字典树的结点中
pos = word[i] - 'a';//下标,0到25分别对应这二十六个字母
if(root -> next[pos] == NULL){
root -> next[pos] = create(root -> next[pos]);//如果对应下标的孩子结点是空,创造一个
//create(root -> next[pos]);
}
root = root -> next[pos];//否则就继续
}
root -> data++;//让字符串中最后一个字符,对应的结点的data值++,记录该字符串出现了几次
return root;
}
int find(struct node *root, char checkword[]){
int i;
int lcheckword;
int pos;
lcheckword = strlen(checkword);
for(i = 0; i < lcheckword; i++){
pos = checkword[i] - 'a';//下标,0到25分别对应这二十六个字母
if(root -> next[pos] == NULL){//如果是空,代表没有一样的字符串return 0,也就是没有找到
return 0;
}
root = root -> next[pos];//否则继续
}
return root -> data;//字符串循环成功走完,代表有它的母串,或者一样的,如果是母串就返回0,如果一样就返回出现了几次
}
int main(){
int n, m;
while(~scanf("%d %d", &n, &m) && n && m){
top = 0;//用来控制使用静态内存
char word[11];
char checkword[11];
int i;
struct node *root;
root = create();//先建好字典树的根,空的字典树
for(i = 0; i < n; i++){
scanf("%s", word);//输入字符串
insert(root, word);//构建字典树
}
while(m--){
scanf("%s", checkword);
if(find(root, checkword)){
printf("Yes\n");//如果不是0
}
else{
printf("No\n");
}
}
}
return 0;
}


















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











