



7B 指的是模型的参数量化大约有 70 亿。
7,000,000,000 * 32bit = 224000000000 bit
224000000000 / 8byte = 28000000000 B
28000000000 byte / 2^30 = 26.0770320892334 GB
模型一般由 bf16 保存
fp16

fp16

即模型大小为
7,000,000,000 * 16bit = 112000000000 bit
224000000000 / 8byte = 14000000000 B
14000000000 byte / 2^30 = 13.0385160446167 GB
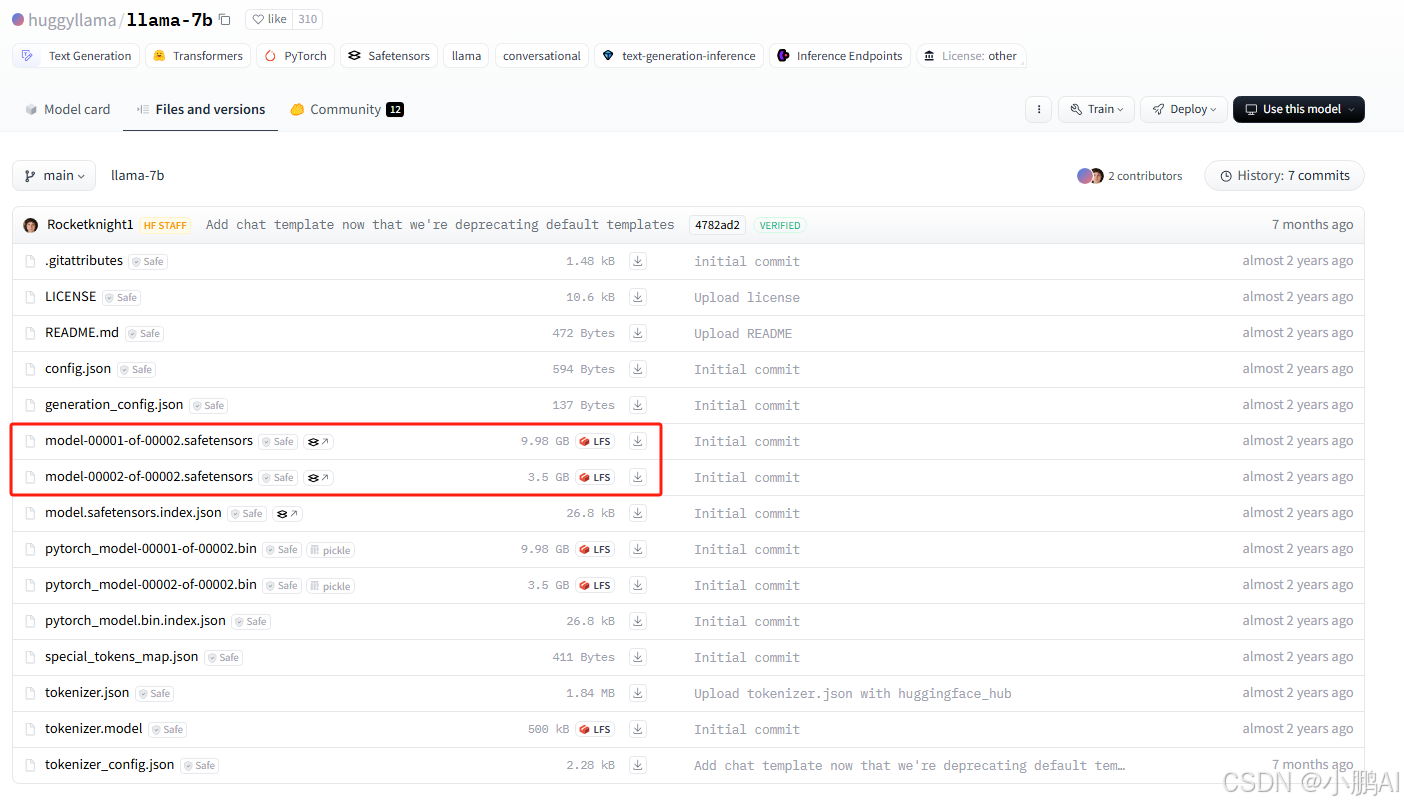
权重文件(safetensors->pt格式)
model-00001-of-00002.safetensors
model-00001-of-00002.safetensors
权重文件(bin格式)
model-00001-of-00002.bin
model-00001-of-00002.bin


















 7494
7494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











