



 本文深入讲解K近邻(KNN)算法原理,通过实例分析展示如何根据特征空间中最近的K个样本判断未知样本的类别。探讨了K值选择对分类精度的影响及应用场景。
本文深入讲解K近邻(KNN)算法原理,通过实例分析展示如何根据特征空间中最近的K个样本判断未知样本的类别。探讨了K值选择对分类精度的影响及应用场景。
K近邻又称KNN算法
那什么是KNN算法
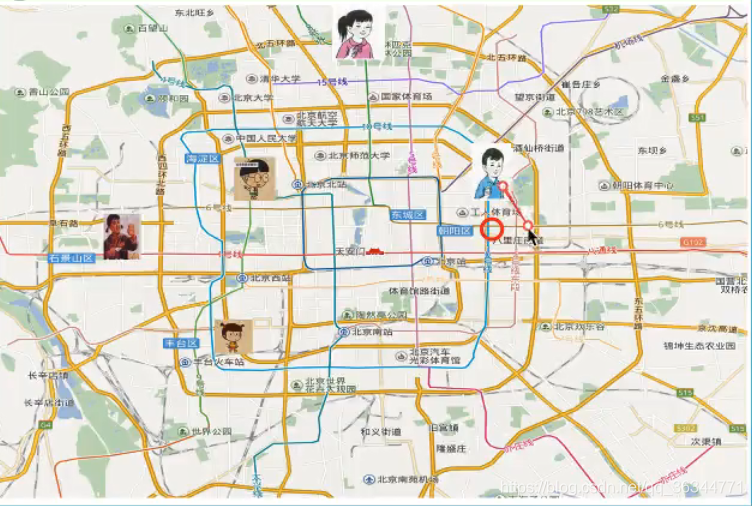
假如我现在在北京,可我不知道我在哪个区。
但是我知道我离其他区是什么距离。
核心算法:根据我的邻居判断我在什么位置
K——近邻算法(KNN)原理
K Nearest Neighbor 算法又叫KNN算法,这个算法是机器学习里面一个比较经典的算法,总体来说KNN算法是相对比较容易理解的算法那
定义:如果一个样本在特征空间中的K个最相似(即特征空间中最邻近)的样本中的大多数属于一个类别,则该样本也属于这个类别。
k=1 容易受到异常点的影响
如何确定谁是我的邻居
计算距离:
距离公式(欧氏距离)
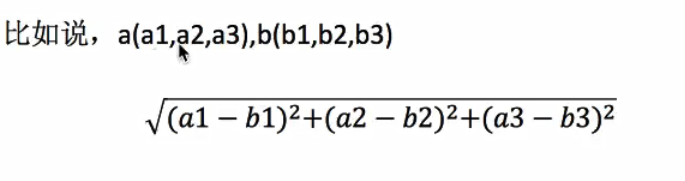
曼哈顿距离——绝对值距离
明可夫斯基距离——
电影实例分析
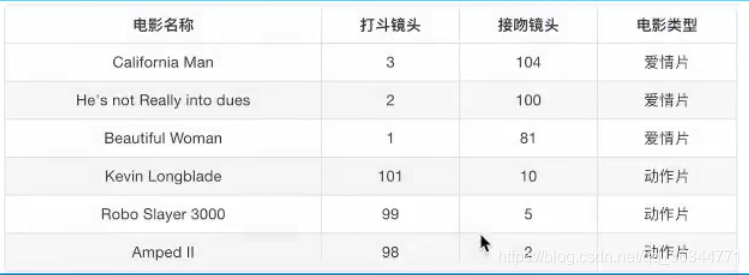
现在有六个样本,有打斗镜头和接吻镜头是两个特征,电影类型是目标值

现在有一个测试样本,想要判断这个电影是动作还是爱情
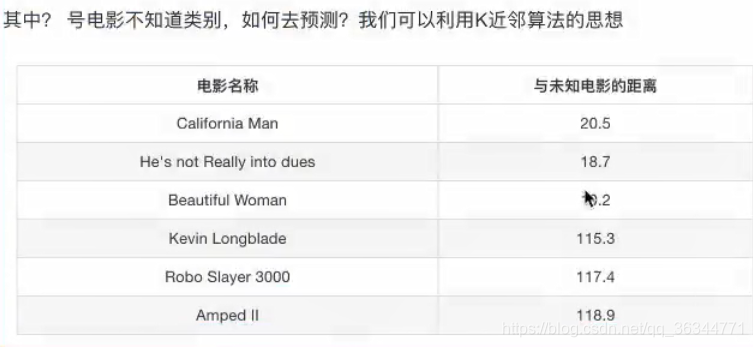
当k =1 那么爱情片离其最近
k =2 也是这样
当k=6时? 无法确定
k=7 动作片
当我们k取值过大,容易分错,当样本不均衡的时候
k取值过小,容易受到异常点的影响。
结合前面的约会对象数据,分析k-邻近算法需要做什么样的处理
需要做无量纲化的处理
具体用标准化,比较稳定 归一化容易受到异常点的影响

第一个参数n_neighbors 相当于k
案列实践,鸢尾花种类预测

流程分析!
1)获取数据
2)从sklearn上面的数据一般都是整理好的,但是需要对数据进行测试与练习分类
3)特征工程 标准化 不需要降维(就4个特征)
4)KNN预估器流程
5)模型评估
K——近邻总结
优点: 简单,易于理解,易于实现,无需训练
缺点:懒惰算法,对测试样本分类时的计算量大,内存开销大
必须指定K值,K值选择不当则分类精度不能保证
使用场景:小数据场景,几千到几万场景, 具体场景具体业务去测试

















 630
630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









