



前言
记录学习中遇到的难点
一、最小树形图
出自《图论的算法与程序设计》
P
27
P27
P27步骤
3
3
3只告诉了我们性质没有证明,现做笔记如下:
把环收缩
C
i
C_i
Ci收缩成点
U
i
U_i
Ui还是很好理解的,但是在收缩后的图中为什么要改变收缩点为终点的边的权值?
记原图为 D 0 D_0 D0,收缩后的图记为 D 1 D_1 D1。
首先如果要构成树形图,那么必然不能有圈,因此我们必然要在圈 C i C_i Ci上去掉一条弧,不妨设被去掉的弧叫做 A t A_t At,而 A t A_t At原来指向的顶点是 V s V_s Vs,此时 V s V_s Vs没有前继了,这样 V s V_s Vs就不能称为树形图的节点了,因为树形图上除了根 V 1 V_1 V1,其他节点都有前继。
所以我们必须从指向 U i U_i Ui的众多弧中选择一条,并且这条弧在展开 U i U_i Ui后也要指向 V s V_s Vs,不妨设这条弧就是 A k A_k Ak,在 D 1 D_1 D1中对这些弧的权值做调整: L D 1 ( A k ) = L D 0 ( A k ) − L D 0 ( A t ) L_{D_1}(A_k)=L_{D_0}(A_k)-L_{D_0}(A_t) LD1(Ak)=LD0(Ak)−LD0(At)。那么如果 D 1 D_1 D1中选择 A k A_k Ak作为树形图的弧,那么无论是在 D 1 D_1 D1中观察,还是在展开圈 C i C_i Ci中观察(展开后要取掉 A t A_t At),总的权值相同,这一点很重要因为我们可以把 D 0 D_0 D0上的最小树形图问题转化到 D 1 D_1 D1上的最小树形图问题。
如果我们在
D
1
D_1
D1中找到了根节点为
V
1
V_1
V1的最小树形图,那么把
U
i
U_i
Ui展开,也就是在
D
D
D中加入
D
1
D_1
D1中选择的最优的
A
k
A_k
Ak,然后再
C
i
C_i
Ci中去掉对应的
A
t
A_t
At。就可以得到
D
0
D_0
D0中的最小树形图。
我们从
D
0
D_0
D0破圈成树形图的各种操作来看待上述说法:
1.
D
0
D_0
D0中的最小树形图还需要去掉了圈
C
i
C_i
Ci中的弧
A
p
A_p
Ap再加入指向
U
i
U_i
Ui的弧
A
q
A_q
Aq,但是
L
D
0
(
A
q
)
−
L
D
0
(
A
p
)
≥
0
L_{D_0}(A_q)-L_{D_0}(A_p)\ge0
LD0(Aq)−LD0(Ap)≥0,显然会导致总权值增加。
2.并且由于在
D
1
D_1
D1中我们的算法选择了
m
i
n
{
L
D
1
(
A
k
)
}
min\{L_{D_1}(A_k)\}
min{LD1(Ak)},因此
L
D
0
(
A
k
)
−
L
D
0
(
A
t
)
≤
L
D
0
(
A
q
)
−
L
D
0
(
A
p
)
L_{D_0}(A_k)-L_{D_0}(A_t)\le L_{D_0}(A_q)-L_{D_0}(A_p)
LD0(Ak)−LD0(At)≤LD0(Aq)−LD0(Ap),如果不选
A
k
A_k
Ak加入而去选
A
q
A_q
Aq加入,那么总的权值一定会增加的。
3.我们之加入
A
k
A_k
Ak并去掉
A
t
A_t
At,显然已经能够得到一棵树形图。
第二点书上提到如果
D
1
D_1
D1中没有
V
1
V_1
V1为根的最小树形图,那么
D
0
D_0
D0中也不会有。
如果
D
1
D_1
D1中没有最小树形图只能说明
V
1
V_1
V1不能延某条路径道道某节点,该节点要么是缩点
U
i
U_i
Ui,要么是普通节点(
D
0
D_0
D0有的点),无论如何从
D
0
D_0
D0的角度看就是
V
1
V_1
V1到某节点通不了。
这样就理解了算法的原理,主要有三个要点:
1.缩点后在新图上指向
U
i
U_i
Ui的弧要进行权值调整
2.如果新图找不到最小树形图则原图也找不到
3.如果新图找到了最小树形图则通过上面的展开步骤可以得到原图的最小树形图
二、DFS树
出自《图论的算法与程序设计》
4.2
4.2
4.2节,感觉DFS树的概念非常重要。
图的DFS是仿照树的先序遍历顺序去访问每一条边
(
U
,
W
)
(U,W)
(U,W)的。加入我们已经访问了顶点
U
U
U,现在正在访问
U
U
U的儿子
W
W
W并且
W
W
W以前还未访问过,则
(
U
,
W
)
(U,W)
(U,W)就是树枝。在DFS过程中顶点和树枝构成树,叫做DFS树。
一般为了处理一些问题,我们按照每个顶点第一次访问到的顺序给顶点一个顺序索引叫做: d f n [ U ] dfn[U] dfn[U]。
图在DFS过程中除了会产生树枝以外还有一些被访问的边是非树枝的边。
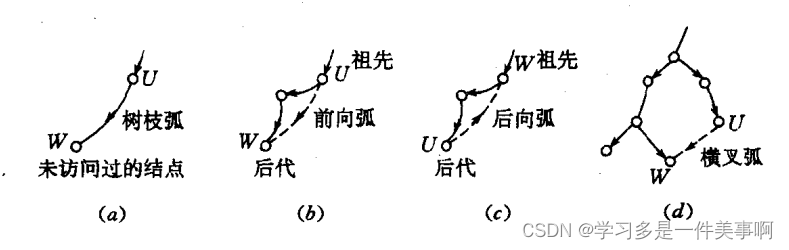
有向图的DFS过程只能产生四种类型的弧:树枝、前向弧、后向弧、横叉弧。
(
a
)
(a)
(a)如果访问了
U
U
U,紧接着访问了
U
U
U的儿子
W
W
W,并且
W
W
W未被访问过,则
(
U
,
W
)
(U,W)
(U,W)是DFS树的树枝,显然
d
f
n
[
W
]
>
d
f
n
[
U
]
dfn[W]>dfn[U]
dfn[W]>dfn[U]。
(
b
)
(b)
(b)如果访问了
U
U
U,后来遍历了
U
U
U的一棵子树,并且子树中包含
W
W
W(不为根节点),如果在未来的某个时刻从
U
U
U开始找新子树遍历的时候发现了
U
U
U的儿子
W
W
W(从图角度看),我们会发现
W
W
W已经被访问多了,此时
(
U
,
W
)
(U,W)
(U,W)不能说是树枝,只能就叫做前向弧,此时也有
d
f
n
[
W
]
>
d
f
n
[
U
]
dfn[W]>dfn[U]
dfn[W]>dfn[U]。
(
c
)
(c)
(c)如果访问了
W
W
W,后来正在遍历
W
W
W的一棵子树,并且子树中包含
U
U
U(不为根节点),在对
U
U
U进行DFS搜索时,发现
U
U
U的一个儿子是
W
W
W(从图的角度看),此时
(
U
,
W
)
(U,W)
(U,W)是后向弧,此时
d
f
n
[
W
]
<
d
f
n
[
U
]
dfn[W]<dfn[U]
dfn[W]<dfn[U]。
(
d
)
(d)
(d)如果已经访问了某顶点,后来先遍历了一棵子树,该子树包含
W
W
W(不为根节点),再后来正在遍历令一棵子树,该子树包含
U
U
U(不为根节点),在对
U
U
U进行DFS搜索时发现
U
U
U的一个儿子是
W
W
W(从图的角度看),则
U
U
U和
W
W
W没有直系亲属关系,弧
(
U
,
W
)
(U,W)
(U,W)被称为横叉弧,此时
d
f
n
[
W
]
<
d
f
n
[
U
]
dfn[W]<dfn[U]
dfn[W]<dfn[U]。
根据我们DFS先序遍历的顺序, ( d ) (d) (d)中的横叉弧只能是从 U U U指向 W W W的。
并且可以想到如果图是无向图的话是不可能存在横叉弧的情况的。
无向图的DFS过程只能产生三种类型的弧:树枝、前向弧、后向弧。也就是如果无向图中有边
(
U
,
W
)
(U,W)
(U,W),则
U
U
U和
W
W
W,必有一个是祖先一个是后代,无向图的DFS树中不会产生图
(
d
)
(d)
(d)的情况。
三、无向图的割顶
如果
U
U
U是割顶,则:
1.如果
U
U
U是根节点,则只要它的儿子多于一个就一定是割顶
2.如果
U
U
U不是根节点,则如果它有一棵子树,该子树中没有到
U
U
U的祖先的后向边,那么
U
U
U也是割顶
无向图中判断是不是后向边非常容易,从DFS树可以看出只要 d f n [ W ] < d f n [ U ] dfn[W]<dfn[U] dfn[W]<dfn[U]那么 ( U , W ) (U,W) (U,W)就是后向边。
设函数 L O W ( S ) LOW(S) LOW(S)表示在DFS树上,顶点 S S S以及 S S S的后代通过后向边能够返回的最早的祖先(每个顶点可用 d f n dfn dfn标记),显然在DFS树上要返回祖先只能通过后向边。
从 ( a ) (a) (a)可以看到,如果 U U U有一个儿子 S S S使得 L O W ( S ) ≥ d f n [ U ] LOW(S)\ge dfn[U] LOW(S)≥dfn[U],那么 S S S以及 S S S的后代无法返回比 U U U更早的祖先,那么 U U U就是割顶了。
我们想要在DFS过程中更新个点的
L
O
W
LOW
LOW,它的递归结构如下:
L
O
W
(
U
)
=
{
d
f
n
[
U
]
第一次访问
U
,
m
i
n
{
L
O
W
(
U
)
,
d
f
n
[
W
]
}
检测到后向边
(
U
,
W
)
,
m
i
n
{
L
O
W
(
U
)
,
L
O
W
(
S
)
}
U
的所有儿子
S
均处理完之后
,
LOW(U)=\left\{ \begin{align} &&dfn[U]&&第一次访问U,\\ &&min\{LOW(U),dfn[W]\}&&检测到后向边(U,W),\\ &&min\{LOW(U),LOW(S)\}&&U的所有儿子S均处理完之后, \end{align} \right.
LOW(U)=⎩
⎨
⎧dfn[U]min{LOW(U),dfn[W]}min{LOW(U),LOW(S)}第一次访问U,检测到后向边(U,W),U的所有儿子S均处理完之后,
对于顶点
U
U
U,如果在程序执行过程中,一旦某个儿子
S
S
S使得
L
O
W
(
S
)
≥
d
f
n
[
U
]
LOW(S)\ge dfn[U]
LOW(S)≥dfn[U]就可以判断
U
U
U是割顶,不用等到所有的儿子的
L
O
W
(
S
)
LOW(S)
LOW(S)值都出来。然后接着继续进行DFS,直到对根节点DFS完成之后才停止算法,这样就找出了全部的割顶了。
书上开始用了一个式子: L O W ( U ) = m i n { d f n [ U ] , L O W [ S ] , d f n [ W ] } LOW(U)=min\{dfn[U],LOW[S],dfn[W]\} LOW(U)=min{dfn[U],LOW[S],dfn[W]},我们在完整的DFS树上来理解这件事:
首先 U U U是自己的祖先,然后 U U U通过儿子们能够回到的最早祖先是 L O W [ S ] LOW[S] LOW[S], U U U通过后向边 ( U , W ) (U,W) (U,W)能够返回的祖先是dfn[W],在里面找一个 d f n dfn dfn号最小的祖先就是能够返回的最早的祖先了。另外 d f n [ U ] dfn[U] dfn[U]也是必须的,比如 U U U无法通过后两个途径返回祖先,那么只好让 L O W ( U ) = d f n [ U ] LOW(U)=dfn[U] LOW(U)=dfn[U],总不能乱写吧, L O W ( U ) LOW(U) LOW(U)也有可能被其他顶点递归调用呢。
如果想要输出块,则可以这样处理,每个顶点再第一次访问的时候都入栈,如果出现了
L
O
W
(
S
)
≥
d
f
n
[
U
]
LOW(S)\ge dfn[U]
LOW(S)≥dfn[U],则
U
U
U是割顶:
1.如果
U
U
U不是根节点,则把儿子
S
S
S以及儿子上面的顶点(其实就是以
S
S
S为根的DFS树中成块的部分)作为块弹出,可以附加上割顶
U
U
U指示是通过哪个割顶分割得到的块。每个儿子都可以这样处理。
2.如果
U
U
U是根节点,则把它的每个儿子
S
S
S以及栈中
S
S
S以上的节点一同依次弹出可以附加上割顶
U
U
U作为指示。
四、强连通分量
每一个强连通分量在DFS树上看都是以最小 d f n dfn dfn开始的节点为根节点 r i r_i ri的树。
该树在这个强连通分量中,因此树上的某个顶点 U U U一定能够通过树枝、前向弧、后向弧、横叉弧返回到树根 r i r_i ri上。
假设某强连通分量在DFS树上以 r i r_i ri为根节点,用 L O W L I N K ( U ) LOWLINK(U) LOWLINK(U)表示 U U U能够在DFS树上返回的 d f n dfn dfn最小顶点的 d f n dfn dfn值。那么如果从 r i r_i ri开始做DFS,DFS返回后必然会发现 L O W L I N K ( r i ) = d f n [ r i ] LOWLINK(r_i)=dfn[r_i] LOWLINK(ri)=dfn[ri]。
书上用 L O W L I N K ( U ) = m i n { d f n [ U ] , d f n [ W ] } LOWLINK(U)=min\{dfn[U],dfn[W]\} LOWLINK(U)=min{dfn[U],dfn[W]},其中 W W W表示在DFS树上从 U U U及其后代出发能够返回的 d f n dfn dfn最小的顶点。
其递归定义如下:
L
O
W
L
I
N
K
(
U
)
=
{
d
f
n
[
U
]
第一次访问
U
,
m
i
n
{
L
O
W
L
I
N
K
(
U
)
,
d
f
n
[
W
]
}
检测到当前树中后向弧
(
U
,
W
)
,
m
i
n
{
L
O
W
L
I
N
K
(
U
)
,
d
f
n
[
W
]
}
检测到当前树中横叉弧
(
U
,
W
)
,
m
i
n
{
L
O
W
L
I
N
K
(
U
)
,
L
O
W
L
I
N
K
(
S
)
}
U
的所有儿子
S
均处理完之后
,
LOWLINK(U)=\left\{ \begin{align} &&dfn[U]&&第一次访问U,\\ &&min\{LOWLINK(U),dfn[W]\}&&检测到当前树中后向弧(U,W),\\ &&min\{LOWLINK(U),dfn[W]\}&&检测到当前树中横叉弧(U,W),\\ &&min\{LOWLINK(U),LOWLINK(S)\}&&U的所有儿子S均处理完之后, \end{align} \right.
LOWLINK(U)=⎩
⎨
⎧dfn[U]min{LOWLINK(U),dfn[W]}min{LOWLINK(U),dfn[W]}min{LOWLINK(U),LOWLINK(S)}第一次访问U,检测到当前树中后向弧(U,W),检测到当前树中横叉弧(U,W),U的所有儿子S均处理完之后,
当前树意思是,已经找到的连通分量已经输出,后续正在DFS的个点形成的树。
算法通过弹栈的方式输出强连通分量,这里理解一下:
首先想一下,我们正在对某根节点
r
i
r_i
ri进行DFS,每一个顶点再进行DFS前就进行入栈,如果先前已经对某点
T
T
T进行了DFS,并且返回时发现
L
O
W
L
I
N
K
(
T
)
=
d
f
n
[
T
]
LOWLINK(T)=dfn[T]
LOWLINK(T)=dfn[T],则栈中会弹出若干顶点,一致直到
T
T
T弹出为止,其实这些弹出的点就是以
T
T
T为根的连通分量。
所以要保证 ( U , W ) (U,W) (U,W)到底是在当前正在搜索的树中,只需要看 W W W在堆栈中的顶点就可以了。
这里说法可能还有些疑问,归纳假设一下:假设问题的规模小于连通分量 T T T,的时候上面的弹栈操作总能给出连通分量,首先当 T T T进行完DFS时有 L O W L I N K ( T ) = d f n [ T ] LOWLINK(T)=dfn[T] LOWLINK(T)=dfn[T],代表 T T T经过后代能够返回到 T T T,如果 T T T的子树中如果有节点不能返回 T T T怎么办呢?其实不用担心,假设 T T T中还包含不能到达 T T T的点,它们必定属于其他的强连通分量,树 T T T包含这些强连通分量的生成树,不妨设某连通分量的根为 T ′ T' T′,那么 T ′ T' T′的DFS完之后一定有 L O W L I N K ( T ’ ) = d f n [ T ′ ] LOWLINK(T’)=dfn[T'] LOWLINK(T’)=dfn[T′],此时连通分量 T ′ T' T′的规模小于连通分量 T T T的规模,因此弹栈直到 T ′ T' T′被弹出就等价于输出了强连通分量 T ′ T' T′。这时候会不会把强连通分量 T T T中的顶点带出来了呢?如果是那样那么两连通分量就属于同一连通分量了,和假设矛盾了。因此到 T T T的DFS完成之前,就已经把不在强连通分量 T T T中的点弹出了,所以到弹 T T T的时候弹出的顶点就是强连通分量 T T T了。当问题的规模降到一个顶点的时候显然成立,因此做法是正确的。
还有一个问题,在DFS的过程中来找后向弧和横叉弧有没有问题,其实因为这两种弧都要求 d f n [ W ] < d f n [ U ] dfn[W]<dfn[U] dfn[W]<dfn[U],所以访问新的顶点 U U U的时候只需要检查先前已经访问过点 W W W即可。
五、支配集、独立集、覆盖集
书上 P 54 P54 P54页只给出了支配集的两个性质:
1.若图 G G G中无零次顶点,则存在一个支配集 D D D,使得 G G G中除去 D D D后的其他顶点构成也是支配集。
说明一下这个事情:不妨设图 G G G是连通的,那么 G G G中存在生成树,祖宗(根节点)涂上黑色,二代目涂上白色,三代目涂上黑色……,则黑色点集合和白色点集合就是两个满足要求的支配集。
2.若图 G G G中无零次顶点, D 1 D_1 D1为极小支配集,则 G G G中除去 D 1 D_1 D1后其他顶点构成一个支配集。
为了叙述方便我们用
V
(
G
)
V(G)
V(G)表示
G
G
G的顶点集合
证明:假设
V
(
G
)
−
D
1
V(G)-D_1
V(G)−D1不是支配集,那么在
D
1
D_1
D1中至少存在一点
x
x
x,它不和
V
(
G
)
−
D
1
V(G)-D_1
V(G)−D1中的点相连,但是我们注意到这样的
x
x
x必须连接在
D
1
D_1
D1的其他点上的,否则由于它和
V
(
G
)
−
D
1
V(G)-D_1
V(G)−D1是不相连的,那么这个
x
x
x在图
G
G
G上就是孤立的(零次顶点了)。由于
x
x
x连接在
D
1
D_1
D1的其他点上的,显然
D
1
D_1
D1去掉
x
x
x之后还是支配集,因此
V
(
G
)
−
D
1
V(G)-D_1
V(G)−D1必须是支配集。
然后书上莫名其妙地给出了计算所有极小支配集的布尔运算公式:
φ
(
V
1
,
V
2
,
⋅
,
V
n
)
=
∏
i
=
0
n
(
V
i
+
∑
U
∈
N
(
V
i
)
U
)
\begin{align} \varphi(V_1,V_2,\cdot,V_n)=\prod_{i=0}^n \left(V_i+\sum_{U\in N(V_i)}U\right) \end{align}
φ(V1,V2,⋅,Vn)=i=0∏n
Vi+U∈N(Vi)∑U
然后我一脸懵逼,然后查看了资料,原来是这样理解的:
其中的累加号表示对所有
V
i
V_i
Vi的邻接点求和,这里的求和就是或运算,乘积就是与运算。把公式按照布尔运算展开成与或式,则每一个乘积项代表是一个极小支配集。
选取
V
i
V_i
Vi表示为
V
i
=
1
V_i=1
Vi=1,不选
V
i
V_i
Vi表示为
V
i
=
0
V_i=0
Vi=0。
比如某个图有四个顶点,并且我们按照公式计算得到:
φ
(
V
1
,
V
2
,
V
3
,
V
4
)
=
V
1
V
2
+
V
2
V
3
V
4
\begin{align} \varphi(V_1,V_2,V_3,V_4)=V_1V_2+V_2V_3V_4 \end{align}
φ(V1,V2,V3,V4)=V1V2+V2V3V4
然后我们指导要使
φ
(
V
1
,
V
2
,
V
3
,
V
4
)
=
1
\varphi(V_1,V_2,V_3,V_4)=1
φ(V1,V2,V3,V4)=1则有两种组合可以选择:
{
V
1
,
V
2
}
,
{
V
2
,
V
3
,
V
4
}
\{V_1,V_2\},\{V_2,V_3,V_4\}
{V1,V2},{V2,V3,V4}
这样就可以得到所有的极小支配集。
但是那么为什么这样做就是合理呢?
为了叙述方便,我们令
φ
i
=
V
i
+
∑
U
∈
N
(
V
i
)
U
\varphi_i=V_i+\sum_{U\in N(V_i)}U
φi=Vi+∑U∈N(Vi)U,则公式简写为
φ
=
∏
i
=
0
n
φ
i
\varphi=\prod_{i=0}^n \varphi_i
φ=∏i=0nφi。
假设我们已经选取了一个点集
{
V
i
}
\{V_i\}
{Vi}满足
φ
=
1
\varphi=1
φ=1的要求,不失一般性取图
G
G
G中的点
V
j
∉
{
V
i
}
V_j\notin\{V_i\}
Vj∈/{Vi},如果
V
j
V_j
Vj和点集
{
V
i
}
\{V_i\}
{Vi}间没有边相连,那么
φ
j
\varphi_j
φj中就不包含点集
{
V
i
}
\{V_i\}
{Vi},带入
{
V
i
}
\{V_i\}
{Vi}由于
φ
j
=
0
\varphi_j=0
φj=0,所以
φ
=
0
\varphi=0
φ=0,这样就和假设矛盾了。所以所有使得
φ
=
1
\varphi=1
φ=1的组合
{
V
i
}
\{V_i\}
{Vi}都是支配集。
同样假如我们选中点集
{
V
i
}
\{V_i\}
{Vi},但
φ
=
0
\varphi=0
φ=0,那么至少有一个
φ
j
=
0
\varphi_j=0
φj=0,等于是说
φ
j
\varphi_j
φj中的点和我们选中的点集
{
V
i
}
\{V_i\}
{Vi}之间没有连接,这样的话点集
{
V
i
}
\{V_i\}
{Vi}显然就不是支配集了。
所以我们知道了:
φ
=
1
⟺
{
V
i
}
\varphi=1\Longleftrightarrow \{V_i\}
φ=1⟺{Vi}是支配集。
最后从公式最后整理出来的与或式可以看出:任选一个乘积项将使得
φ
=
1
\varphi=1
φ=1,但乘积项中的点如果去除其中一个顶点(该顶点的值取
0
0
0)则
φ
=
0
\varphi=0
φ=0,因此乘积项就是极小支配集。
书上 P 58 P58 P58也给出了独立集、支配集、覆盖集之间的关系:
1.
I
I
I是极大独立集
⟺
\Longleftrightarrow
⟺
I
I
I是独立支配集。
极大独立集为
I
I
I中,不在
I
I
I中的点必然连接到
I
I
I上(否则加入这些点就能构成更大的独立集),所以
I
I
I也是一个支配集,又
I
I
I是独立的,因此
I
I
I就是独立支配集。
反过来如果
I
I
I是支配集,点
x
∈
V
(
G
)
−
I
x\in V(G)-I
x∈V(G)−I一定是通过边连接到
I
I
I中的,因此
I
+
{
x
}
I+\{x\}
I+{x}中有和
x
x
x邻接的顶点,但是加入
{
x
}
\{x\}
{x}就破坏了原来的独立性,因此
I
I
I又是极大独立集。
2.
I
I
I是独立集
⟺
\Longleftrightarrow
⟺
V
(
G
)
−
I
V(G)-I
V(G)−I就是覆盖集。
显然如果
I
I
I是独立集,则对于
I
I
I的任意点
{
x
}
\{x\}
{x}要么连接到
V
(
G
)
−
I
V(G)-I
V(G)−I中,要么孤立,也就是说所有说图
G
G
G中的所有的边都是都和
V
(
G
)
−
I
V(G)-I
V(G)−I中的点相关,因此
V
(
G
)
−
I
V(G)-I
V(G)−I是覆盖集。
反过来
V
(
G
)
−
I
V(G)-I
V(G)−I是覆盖集,所以所有的边至少有一个端点在
V
(
G
)
−
I
V(G)-I
V(G)−I中,因此任意一条边不能两个端点都在
I
I
I中,也就是
I
I
I是独立集的意思。
3.
I
I
I是极大(最大)独立集
⟺
\Longleftrightarrow
⟺
V
(
G
)
−
I
V(G)-I
V(G)−I是极小(最小)覆盖集。
首先由性质
2
2
2可以看出
V
(
G
)
−
I
V(G)-I
V(G)−I已经是覆盖集,由
1
1
1可知
I
I
I同时也是支配集,所以存在边
(
x
,
y
)
(x,y)
(x,y),其中
x
∈
I
x\in I
x∈I,
y
∈
V
(
G
)
−
I
y\in V(G)-I
y∈V(G)−I。显然去掉
V
(
G
)
−
I
V(G)-I
V(G)−I中的点
y
y
y则
V
(
G
)
−
I
V(G)-I
V(G)−I没有点能够成为
(
x
,
y
)
(x,y)
(x,y)端点。因此
V
(
G
)
−
I
V(G)-I
V(G)−I就是极小覆盖集。
反过来由
2
2
2可以看出
I
I
I是独立的,又
V
(
G
)
−
I
V(G)-I
V(G)−I是极小覆盖集,如果在
V
(
G
)
−
I
V(G)-I
V(G)−I中去掉一点
x
x
x后,就存在有一条边
(
x
,
y
)
(x,y)
(x,y)就不以
V
(
G
)
−
I
−
{
x
}
V(G)-I-\{x\}
V(G)−I−{x}中的点为端点,也就是存在一条边它的两个端点都在
I
+
{
x
}
I+\{x\}
I+{x}中,也就是
I
I
I加入点
x
x
x之后有了相邻点,此时就它不是独立集了,因此
I
I
I是极大独立集。
我们就得到了:
I
I
I是极大独立集
⟺
\Longleftrightarrow
⟺
V
(
G
)
−
I
V(G)-I
V(G)−I是极小覆盖集。括号中的最大怎么解释呢?由于
I
I
I和
V
(
G
)
−
I
V(G)-I
V(G)−I中顶点个数总和等于图
G
G
G顶点个数,因此如果
I
I
I的顶点数取最大等价于
V
(
G
)
−
I
V(G)-I
V(G)−I的顶点数取最少,反之亦然。
这样就证明了这条性质。
4.极大独立集必为极小支配集。
极大独立集
I
I
I一定是支配集,并且是独立的,因此
I
I
I中的任意顶点
{
x
}
\{x\}
{x}和
I
−
{
x
}
I-\{x\}
I−{x}中的顶点没有边连接,即
I
−
{
x
}
I-\{x\}
I−{x}不是支配集,也就是
I
I
I是极小支配集。
5.如果
I
I
I是独立集,则
I
I
I是极大独立集
⟺
\Longleftrightarrow
⟺
I
I
I极小支配集等价。
这个可以由性质
1
1
1和性质
4
4
4结合看出来。
然后书上又是给出了一个极小覆盖集的公式:
φ
(
V
1
,
V
2
,
⋅
,
V
n
)
=
∏
i
=
0
n
(
V
i
+
∏
U
∈
N
(
V
i
)
U
)
\begin{align} \varphi(V_1,V_2,\cdot,V_n)=\prod_{i=0}^n \left(V_i+\prod_{U\in N(V_i)}U\right) \end{align}
φ(V1,V2,⋅,Vn)=i=0∏n
Vi+U∈N(Vi)∏U
注意最里面是连乘号。
我们仿照极小支配集的思路来理解以下公式,极小这个事情显然可以通过最后的与或式来说明的,这里就不啰嗦了。我们来证明这个
φ
=
1
\varphi=1
φ=1等价于选取的点集
{
V
i
}
\{V_i\}
{Vi}是极小覆盖。
同样我们记
φ
i
=
V
i
+
∏
U
∈
N
(
V
i
)
U
\varphi_i=V_i+\prod_{U\in N(V_i)}U
φi=Vi+∏U∈N(Vi)U,那么公式简写为
φ
=
∏
i
=
0
n
φ
i
\varphi=\prod_{i=0}^n \varphi_i
φ=∏i=0nφi。
假设我们选取了点集
{
V
i
}
\{V_i\}
{Vi},并且使得
φ
=
1
\varphi=1
φ=1,假设有一条边
(
V
j
,
V
k
)
(V_j,V_k)
(Vj,Vk)没有被覆盖,则
V
j
,
V
k
V_j,V_k
Vj,Vk不属于点集
{
V
i
}
\{V_i\}
{Vi},那么
φ
j
\varphi_j
φj中的
∏
U
∈
N
(
V
j
)
U
=
0
\prod_{U\in N(V_j)}U=0
∏U∈N(Vj)U=0,因为
V
k
V_k
Vk是
V
j
V_j
Vj的邻接点,乘积就包含了
V
k
V_k
Vk,而
V
k
∉
{
V
i
}
V_k\notin\{V_i\}
Vk∈/{Vi},即
V
k
=
0
V_k=0
Vk=0,同理有
V
j
=
0
V_j=0
Vj=0,因此
φ
j
=
0
\varphi_j=0
φj=0,这就导致
φ
=
0
\varphi=0
φ=0,和假设矛盾了。因此使得使得
φ
=
1
\varphi=1
φ=1的点集
{
V
i
}
\{V_i\}
{Vi}一定是极小覆盖。
同样假如我们选中点集
{
V
i
}
\{V_i\}
{Vi},但
φ
=
0
\varphi=0
φ=0,那么至少有一个
φ
j
=
0
\varphi_j=0
φj=0,等于是说
{
V
i
}
\{V_i\}
{Vi}不包含
V
j
V_j
Vj,且
V
j
V_j
Vj的邻接点中至少有一个顶点
V
k
V_k
Vk不属于
{
V
i
}
\{V_i\}
{Vi},因此
(
V
j
,
V
k
)
(V_j,V_k)
(Vj,Vk)两个端点都不属于
{
V
i
}
\{V_i\}
{Vi},因此
{
V
i
}
\{V_i\}
{Vi}不是覆盖集。
所以我们知道了:
φ
=
1
⟺
{
V
i
}
\varphi=1\Longleftrightarrow \{V_i\}
φ=1⟺{Vi}是覆盖集。
六、最大网络流
比较困惑的地方在于,流
F
F
F是网络
D
D
D的一个流,如果不存在
V
s
V_s
Vs到
V
t
V_t
Vt的关于
F
F
F的可改进路
P
P
P,那么
F
F
F一定是一个最大流?
首先必要性是显然的,如果
F
F
F是最大流一定不能再改进,也就不可能找到可改进路
P
P
P了。
充分性的证明比较困难,需要系统学习一下切割的知识。
把图
G
G
G中的点分成两个阵营,一个包含原点
V
s
V_s
Vs记为
S
S
S,一个包含汇点
V
t
V_t
Vt记为
T
T
T,显然两则互补即:
S
ˉ
=
T
\bar S=T
Sˉ=T
从
S
S
S到
T
T
T的弧的集合就叫做一个割,简记为:
K
=
(
S
,
T
)
K=(S,T)
K=(S,T)
定义割的容量:
c
(
K
)
=
∑
a
∈
K
c
(
a
)
c(K)=\sum_{a\in K} c(a)
c(K)=a∈K∑c(a)
如果网络流为
f
f
f,而整个网络流的值为
f
s
,
t
f_{s,t}
fs,t,而
(
S
,
T
)
(S,T)
(S,T)是网络的一个割,则有:
f
s
,
t
=
∑
a
∈
(
S
,
T
)
f
(
a
)
−
∑
a
′
∈
(
T
,
S
)
f
(
a
′
)
f_{s,t}=\sum_{a\in (S,T)} f(a)-\sum_{a'\in (T,S)}f(a')
fs,t=a∈(S,T)∑f(a)−a′∈(T,S)∑f(a′)
通常也简记为:
f
s
,
t
=
f
(
S
,
T
)
−
f
(
T
,
S
)
f_{s,t}=f (S,T)-f (T,S)
fs,t=f(S,T)−f(T,S)
它的意义很直观,就是流到汇点那边的流量的减去流回源点这边的流量=净流量。
下面来证明一下:
由流函数
f
f
f的性质:
f
[
V
s
,
V
(
G
)
]
−
f
[
V
(
G
)
,
V
s
]
=
f
s
,
t
f[V_s,V(G)]-f[V(G),V_s]=f_{s,t}
f[Vs,V(G)]−f[V(G),Vs]=fs,t
f
[
V
i
,
V
(
G
)
]
−
f
[
V
(
G
)
,
V
i
]
=
0
f[V_i,V(G)]-f[V(G),V_i]=0
f[Vi,V(G)]−f[V(G),Vi]=0, 其中
V
i
不为源点和汇点
V_i不为源点和汇点
Vi不为源点和汇点
f
[
V
t
,
V
(
G
)
]
−
f
[
V
(
G
)
,
V
t
]
=
−
f
s
,
t
f[V_t,V(G)]-f[V(G),V_t]=-f_{s,t}
f[Vt,V(G)]−f[V(G),Vt]=−fs,t
在割
K
=
(
S
,
T
)
K=(S,T)
K=(S,T)中有:
∑
V
k
∈
S
{
f
[
V
k
,
V
(
G
)
]
−
f
[
V
(
G
)
,
V
k
]
}
=
f
s
,
t
\sum_{V_k\in S}\{f[V_k,V(G)]-f[V(G),V_k]\}=f_{s,t}
Vk∈S∑{f[Vk,V(G)]−f[V(G),Vk]}=fs,t
简记为:
f
[
S
,
V
(
G
)
]
−
f
[
V
(
G
)
,
S
]
=
f
s
,
t
f[S,V(G)]-f[V(G),S]=f_{s,t}
f[S,V(G)]−f[V(G),S]=fs,t。
由于
V
(
G
)
=
S
∪
S
ˉ
V(G)=S\cup \bar S
V(G)=S∪Sˉ,所以
f
[
S
,
V
(
G
)
]
=
f
(
S
,
S
)
+
f
(
S
,
S
ˉ
)
f[S,V(G)]=f(S,S)+f(S,\bar S)
f[S,V(G)]=f(S,S)+f(S,Sˉ),
同理
f
[
V
(
G
)
,
S
]
=
f
(
S
,
S
)
+
f
(
S
ˉ
,
S
)
f[V(G),S]=f(S,S)+f(\bar S,S)
f[V(G),S]=f(S,S)+f(Sˉ,S),所以有:
f
(
S
,
S
ˉ
)
−
f
(
S
ˉ
,
S
)
=
f
s
,
t
f(S,\bar S)-f(\bar S,S)=f_{s,t}
f(S,Sˉ)−f(Sˉ,S)=fs,t,这个式子就是我们要的结论:
f
s
,
t
=
f
(
S
,
T
)
−
f
(
T
,
S
)
f_{s,t}=f (S,T)-f (T,S)
fs,t=f(S,T)−f(T,S)。
显然如果对于任意一个割
K
=
(
S
,
T
)
K=(S,T)
K=(S,T)的容量来看,
f
(
S
,
T
)
−
f
(
T
,
S
)
≤
c
(
K
)
f (S,T)-f (T,S)\le c(K)
f(S,T)−f(T,S)≤c(K)
于是得到一个推论:
f
m
a
x
≤
c
m
i
n
(
K
)
f_{max}\le c_{min}(K)
fmax≤cmin(K)
最大流最小割定理:
这个就非常重要了,它的意思是
f
m
a
x
=
c
m
i
n
(
K
)
f_{max} = c_{min}(K)
fmax=cmin(K)。
假设
f
f
f是一个最大流,我们来通过它定义各个割,采用逐步生成的方法来构造
S
S
S。
首先
V
s
∈
S
V_s\in S
Vs∈S,这样
S
S
S就不是空集了,然后对于顶点
i
∈
S
i\in S
i∈S,如果
f
(
i
,
j
)
<
c
(
i
,
j
)
f(i,j)<c(i,j)
f(i,j)<c(i,j)或者
f
(
j
,
i
)
>
0
f(j,i)>0
f(j,i)>0,则把
j
j
j加入到
S
S
S中。
理解一下这件事情,首先从无向图的观点看所有的加入点都能通过一系列的边连通到点 V s V_s Vs,并且每一次 S S S向外拓展必然是加入了一条不饱和的弧( f ( i , j ) < c ( i , j ) f(i,j)<c(i,j) f(i,j)<c(i,j)代表了弧的方向是从 S S S指向外面的,而 f ( j , i ) > 0 f(j,i)>0 f(j,i)>0反映弧是从外面指向 S S S的)。
显然
V
t
∉
S
V_t\notin S
Vt∈/S,否者按照前面扩展
S
S
S的方式,随着
S
S
S的扩张就会出现一条从
V
s
V_s
Vs到
V
t
V_t
Vt的路,并且这条路上的弧
都是不饱和的弧,因此就出现了一条可改进路,这样
f
f
f就不是最大流了。
所以
V
t
∈
S
ˉ
V_t\in \bar S
Vt∈Sˉ,所以
(
S
,
S
ˉ
)
(S,\bar S)
(S,Sˉ)构成了一个割。
我们考察一条边从
S
S
S到
S
ˉ
\bar S
Sˉ的边
(
V
i
,
V
j
)
(V_i,V_j)
(Vi,Vj),如果
f
(
V
i
,
V
j
)
<
c
(
V
i
,
V
j
)
f(V_i,V_j)<c(V_i,V_j)
f(Vi,Vj)<c(Vi,Vj),那么按照
S
S
S的生成方法就有
V
j
∈
S
V_j\in S
Vj∈S,这样就矛盾了,因此必须有
f
(
V
i
,
V
j
)
=
c
(
V
i
,
V
j
)
f(V_i,V_j)=c(V_i,V_j)
f(Vi,Vj)=c(Vi,Vj)。
同理我们考察一条边从
S
ˉ
\bar S
Sˉ到
S
S
S的边
(
V
j
,
V
i
)
(V_j,V_i)
(Vj,Vi),如果
f
(
V
j
,
V
i
)
>
0
f(V_j,V_i)>0
f(Vj,Vi)>0,那么又会导致
V
j
∈
S
V_j\in S
Vj∈S,这样就矛盾了,因此必须有
f
(
V
j
,
V
i
)
=
0
f(V_j,V_i)=0
f(Vj,Vi)=0。
因此对于最大流 f f f必有 f s , t = c ( S , S ˉ ) f_{s,t}=c(S,\bar S) fs,t=c(S,Sˉ),先前我们知道了 f m a x ≤ c m i n ( K ) f_{max}\le c_{min}(K) fmax≤cmin(K),现在我们来看总是可以取一些特殊的割使得最大流等于这个割,因此我们立刻就知道了,刚才构造的割其实是最小割,并且我们有: f m a x = c m i n ( K ) f_{max}= c_{min}(K) fmax=cmin(K)。
现在我们来看可改进路和最大流的充分关系了。
假设经某算法的操作得到了流
f
f
f,并且目前已经找不到可改进路了,此时我们按照定理证明过程中那样构造
S
S
S,那么显然
V
t
∉
S
V_t\notin S
Vt∈/S,否则按照上面的推理就会出现可改进路。而定理的证明其实就是通过构造
S
S
S直接得到最小割
c
m
i
n
(
K
)
c_{min}(K)
cmin(K),因此此时的流
f
=
c
m
i
n
(
K
)
f=c_{min}(K)
f=cmin(K),根据定理这个流就是最大流。

















 2084
2084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









