







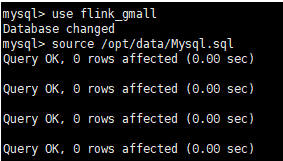
1、Mysql数据准备
(1)创建实时同步数据库
create database flink_gmall
(2)将Mysql.sql文件导入到Mysql中
source /opt/data/Mysql.sql
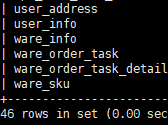
(3)查看数据库表
show tables;
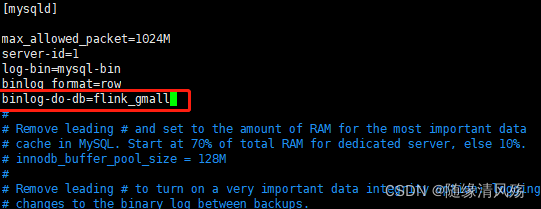
2、开启数据库的binlog
(1)在mysql中对需要进行实时数据监测的库开启binlog
sudo vim /etc/my.cnf
#添加数据库的binlog
server-id=1
log-bin=mysql-bin
binlog_format=row
binlog-do-db=flink_gmall
#重启MySQL服务
sudo systemctl restart mysqld
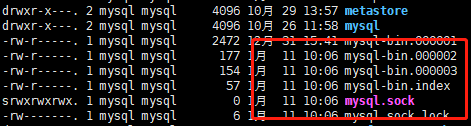
(2)查询生成日志
cd /var/lib/mysql
3、编写脚本
(1)创建项目
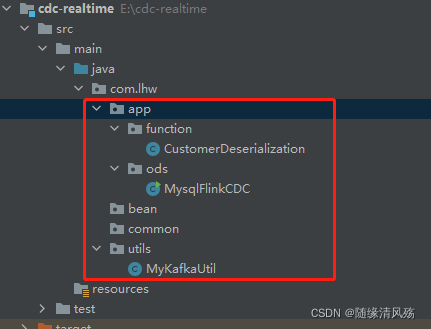
- 项目目录详述
| 目录 | 作用 |
|---|---|
| app | 产生各层的flink任务 |
| bean | 数据对象 |
| common | 公共常量 |
| utils | 工具类 |
(2)编写ODS代码
- 创建topic
bin/kafka-topics.sh --zookeeper hadoop102:2181/kafka --create --replication-factor 3 --partitions 6 --topic ods_behavior_db
- 工具类MyKafkaUtil
package com.lhw.utils;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
public class MyKafkaUtil {
public static FlinkKafkaProducer<String> getKafkaProducer(String topic){
return new FlinkKafkaProducer<String>("hadoop102:9092,hadoop103:9092,hadoop104:9092",topic,new SimpleStringSchema());
}
}
- 反序列化函数CustomerDeserialization
package com.lhw.app.function;
import com.alibaba.fastjson.JSONObject;
import com.ververica.cdc.debezium.DebeziumDeserializationSchema;
import io.debezium.data.Envelope;
import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.util.Collector;
import org.apache.kafka.connect.data.Field;
import org.apache.kafka.connect.data.Schema;
import org.apache.kafka.connect.data.Struct;
import org.apache.kafka.connect.source.SourceRecord;
import java.util.List;
public class CustomerDeserialization implements DebeziumDeserializationSchema<String> {
/**
* 封装的数据格式
* {
* "database":"",
* "tableName":"",
* "before":{"id":"","tm_name":""....},
* "after":{"id":"","tm_name":""....},
* "type":"c u d",
* //"ts":156456135615
* }
*/
@Override
public void deserialize(SourceRecord sourceRecord, Collector<String> collector) throws Exception {
//1.创建JSON对象用于存储最终数据
JSONObject result = new JSONObject();
//2.获取库名&表名
String topic = sourceRecord.topic();
String[] fields = topic.split("\\.");
String database = fields[1];
String tableName = fields[2];
Struct value = (Struct) sourceRecord.value();
//3.获取"before"数据
Struct before = value.getStruct("before");
JSONObject beforeJson = new JSONObject();
if (before != null) {
Schema beforeSchema = before.schema();
List<Field> beforeFields = beforeSchema.fields();
for (Field field : beforeFields) {
Object beforeValue = before.get(field);
beforeJson.put(field.name(), beforeValue);
}
}
//4.获取"after"数据
Struct after = value.getStruct("after");
JSONObject afterJson = new JSONObject();
if (after != null) {
Schema afterSchema = after.schema();
List<Field> afterFields = afterSchema.fields();
for (Field field : afterFields) {
Object afterValue = after.get(field);
afterJson.put(field.name(), afterValue);
}
}
//5.获取操作类型 CREATE UPDATE DELETE
Envelope.Operation operation = Envelope.operationFor(sourceRecord);
String type = operation.toString().toLowerCase();
if ("create".equals(type)) {
type = "insert";
}
//6.将字段写入JSON对象
result.put("database", database);
result.put("tableName", tableName);
result.put("before", beforeJson);
result.put("after", afterJson);
result.put("type", type);
//7.输出数据
collector.collect(result.toJSONString());
}
@Override
public TypeInformation<String> getProducedType() {
return BasicTypeInfo.STRING_TYPE_INFO;
}
}
- FlinkCDC的mainclass
package com.lhw.app.ods;
import com.lhw.app.function.CustomerDeserialization;
import com.lhw.utils.MyKafkaUtil;
import com.ververica.cdc.connectors.mysql.MySqlSource;
import com.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.ververica.cdc.debezium.DebeziumSourceFunction;
import com.ververica.cdc.debezium.StringDebeziumDeserializationSchema;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.time.Duration;
public class MysqlFlinkCDC {
public static void main(String[] args) throws Exception {
// 1、获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
// // 2、开启CK并指定状态后端为FS
// // 2.1、制定存储ck地址
// env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/flinkCDC"));
// // 2.2、指定ck储存触发间隔时间
// env.enableCheckpointing(5000);
// // 2.3、指定ck模式
// env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// // 2.4、指定超时时间
// env.getCheckpointConfig().setAlignmentTimeout(Duration.ofSeconds(1000));
// // 2.5、CK最小触发间隔时间
// env.getCheckpointConfig().setMaxConcurrentCheckpoints(2000);
// 3、通过FlinkCDC构建SourceFunction
DebeziumSourceFunction<String> mysqlSource = MySqlSource.<String>builder()
.hostname("hadoop102")
.port(3306)
.databaseList("flink_gmall") // set captured database
.tableList("flink_gmall.base_category1") // 如果不添加该参数,则消费指定数据库中的所有表
.username("root")
.password("123456")
.startupOptions(StartupOptions.initial())
.deserializer(new CustomerDeserialization())
.build();
// 4、使用CDC Source方式从mysql中读取数据
DataStreamSource<String> mysqlDS = env.addSource(mysqlSource);
// 5、打印数据并将数据输入到kafka
mysqlDS.print();
String sinkTopic = "ods_behavior_db";
mysqlDS.addSink(MyKafkaUtil.getKafkaProducer(sinkTopic));
// 5、执行任务
env.execute("flinkcdcmysql3");
}
}
(3)运行测试
- 本地IDEA打印输出 & kafka集群消费
bin/kafka-console-consumer.sh \--bootstrap-server hadoop102:9092 --topic ods_behavior_db

(4)检测变化
- Mysql进行增改删工作
#新增数据
insert into flink_gmall.base_category1 values(18,"奢侈品");
#修改数据
update flink_gmall.base_category1 set name="轻奢品" where id = 18;
#删除数据
delete from flink_gmall.base_category1 where id=18;
- IDEA检测变化 & Kakfa集群检测变化
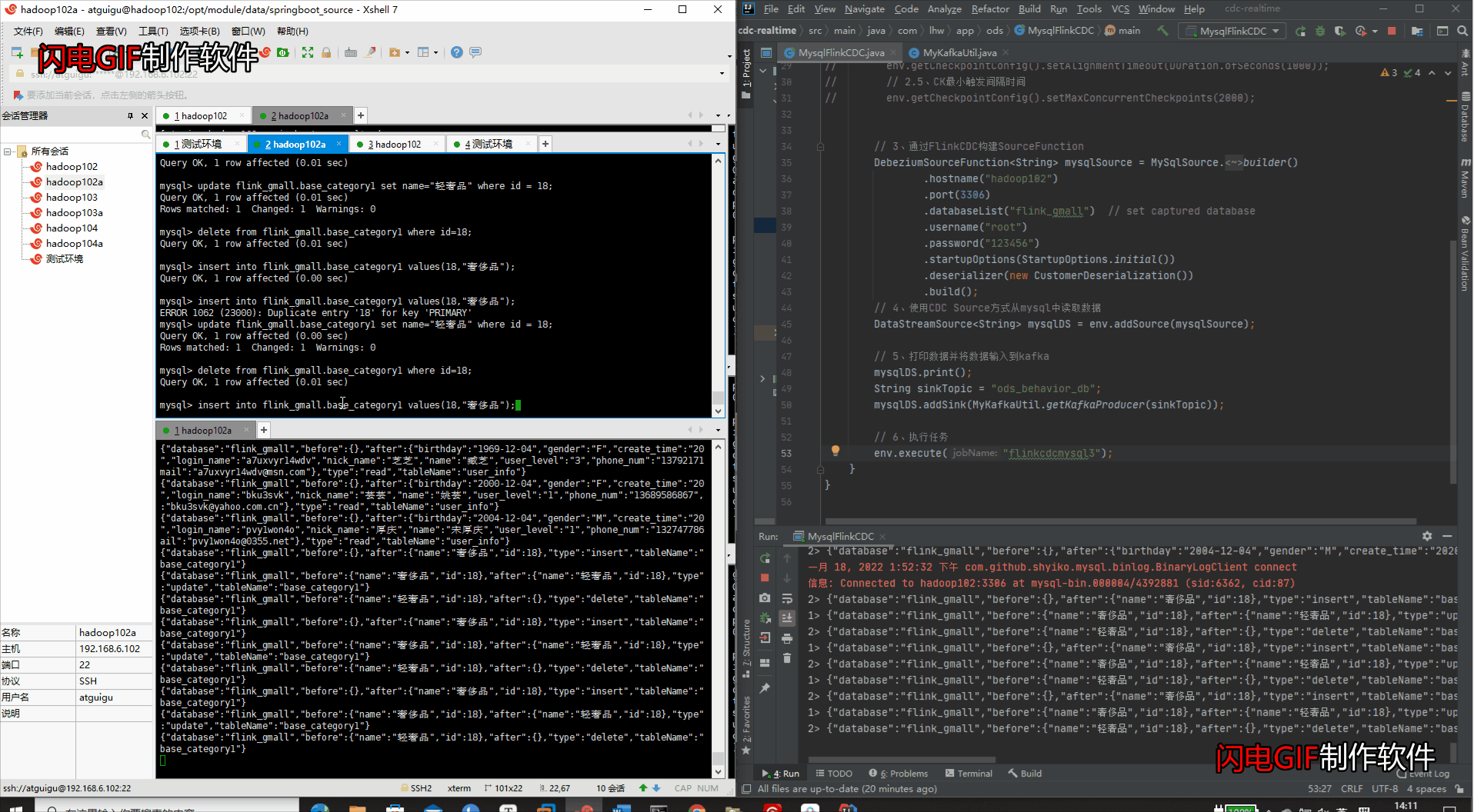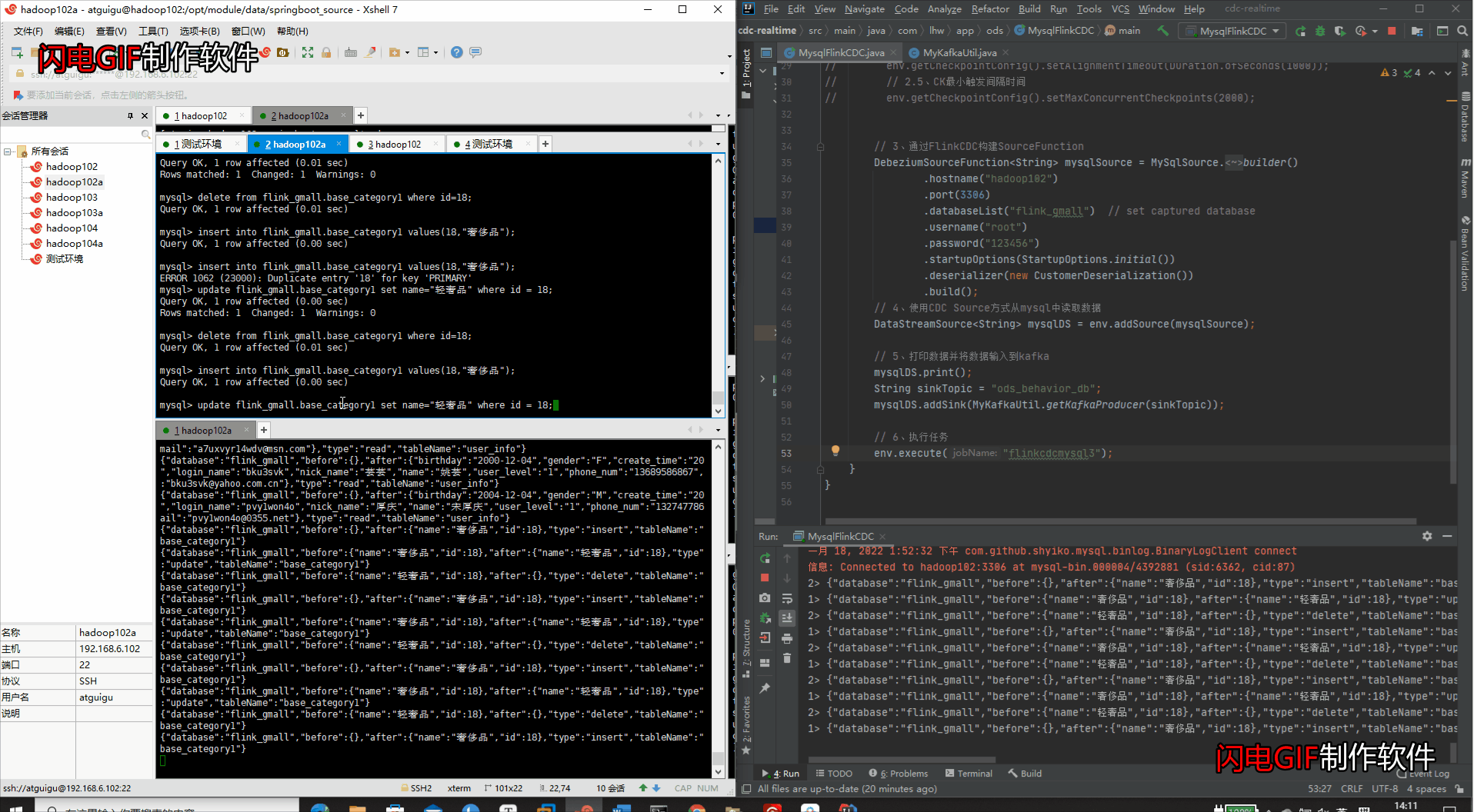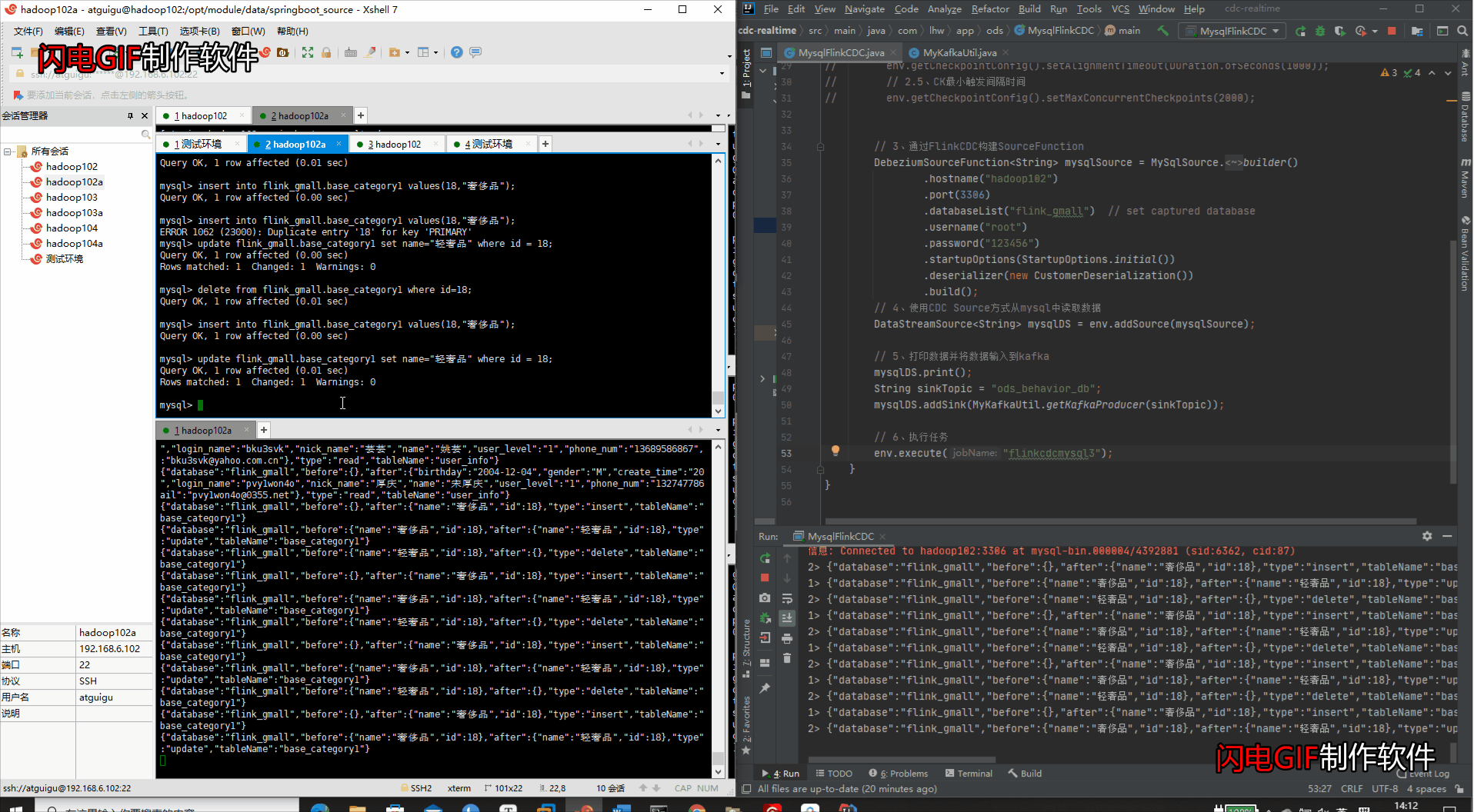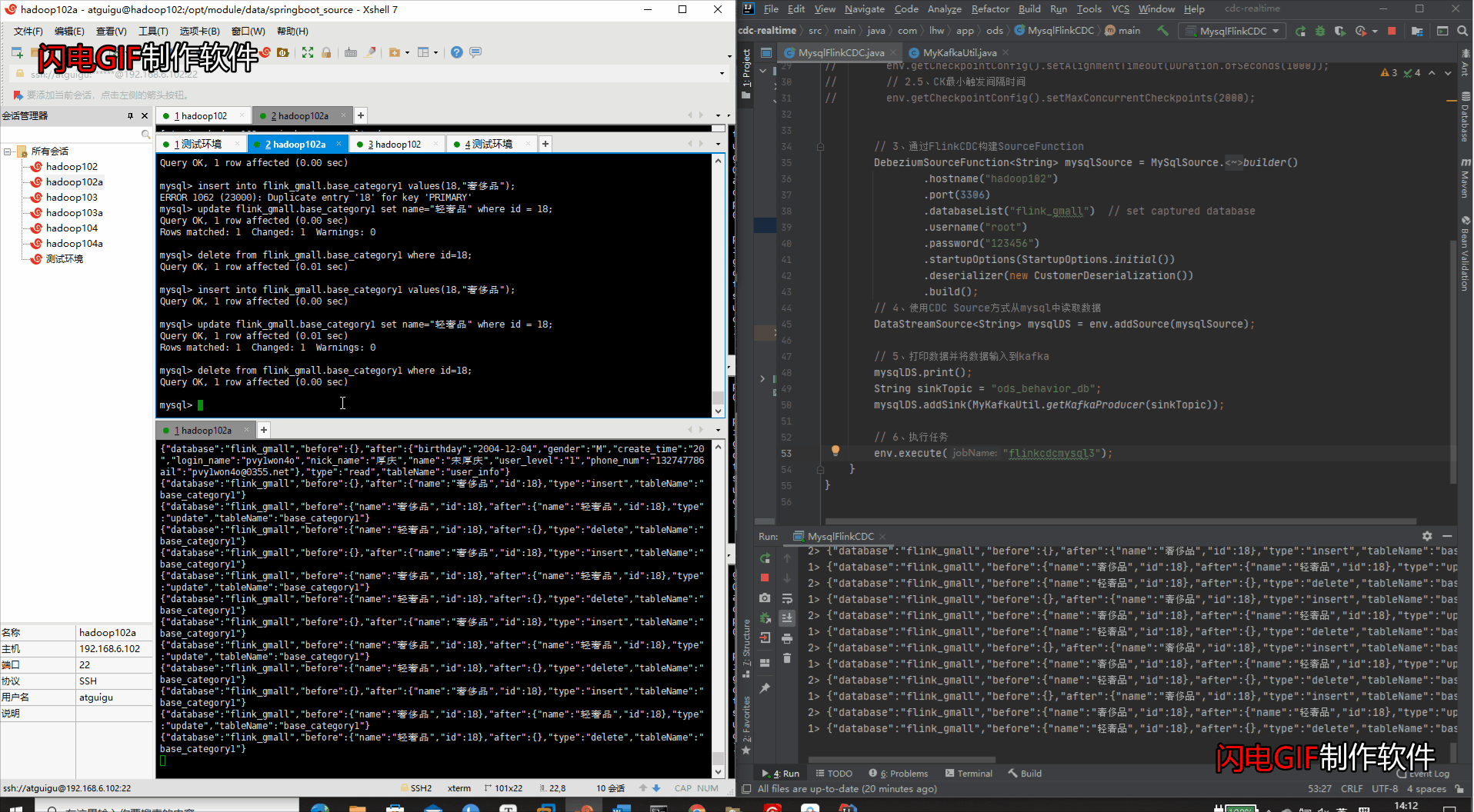
(5)模拟数据生成(检测整个库的变化)
①文件上传并运行
#文件上传
rz
application.properties
gmall2020-mock-db-2020-11-27.jar
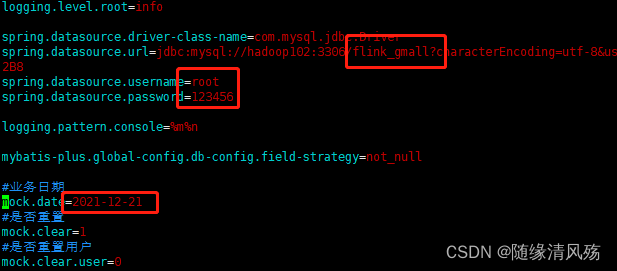
②修改配置文件
修改对应的库名,用户名&密码
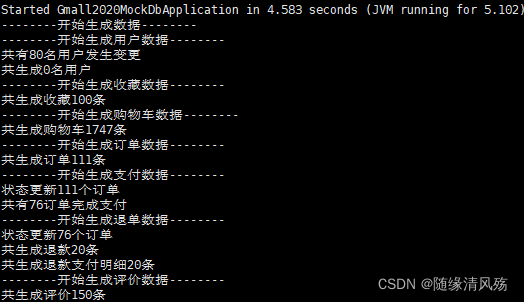
③运行数据生成项目文件
java -jar gmall2020-mock-db-2020-11-27.jar
④IDEA检测变化 & kafka消费数据变化
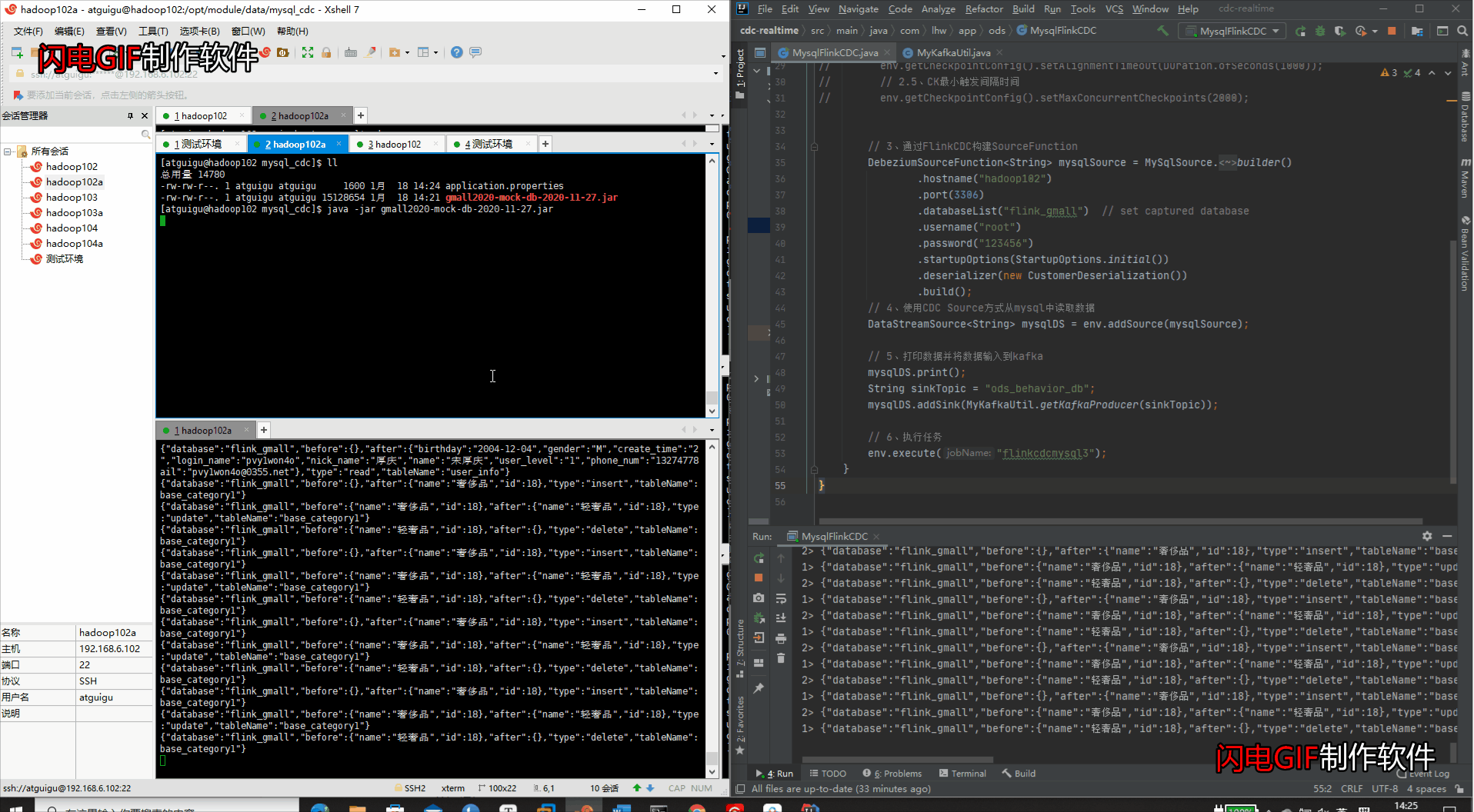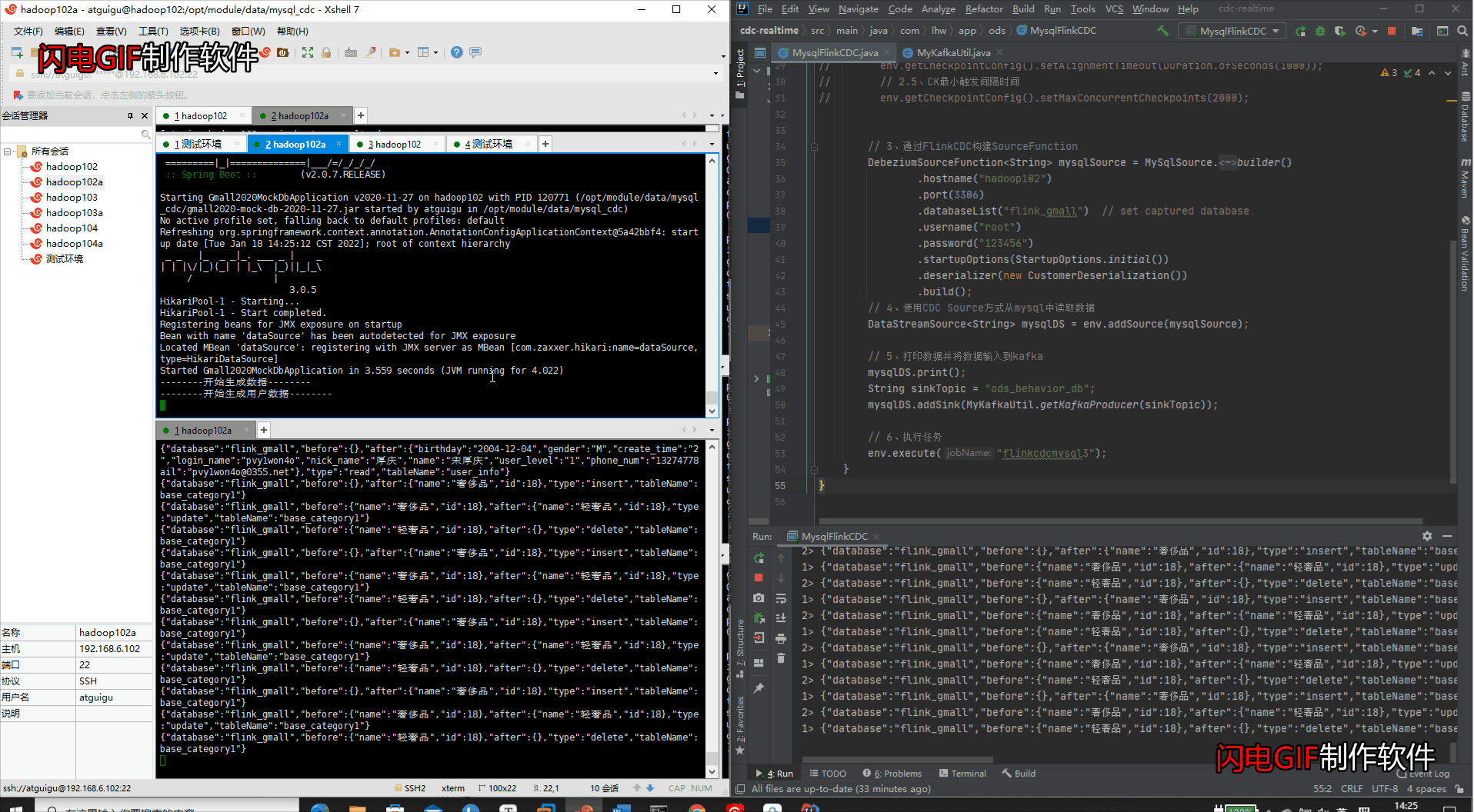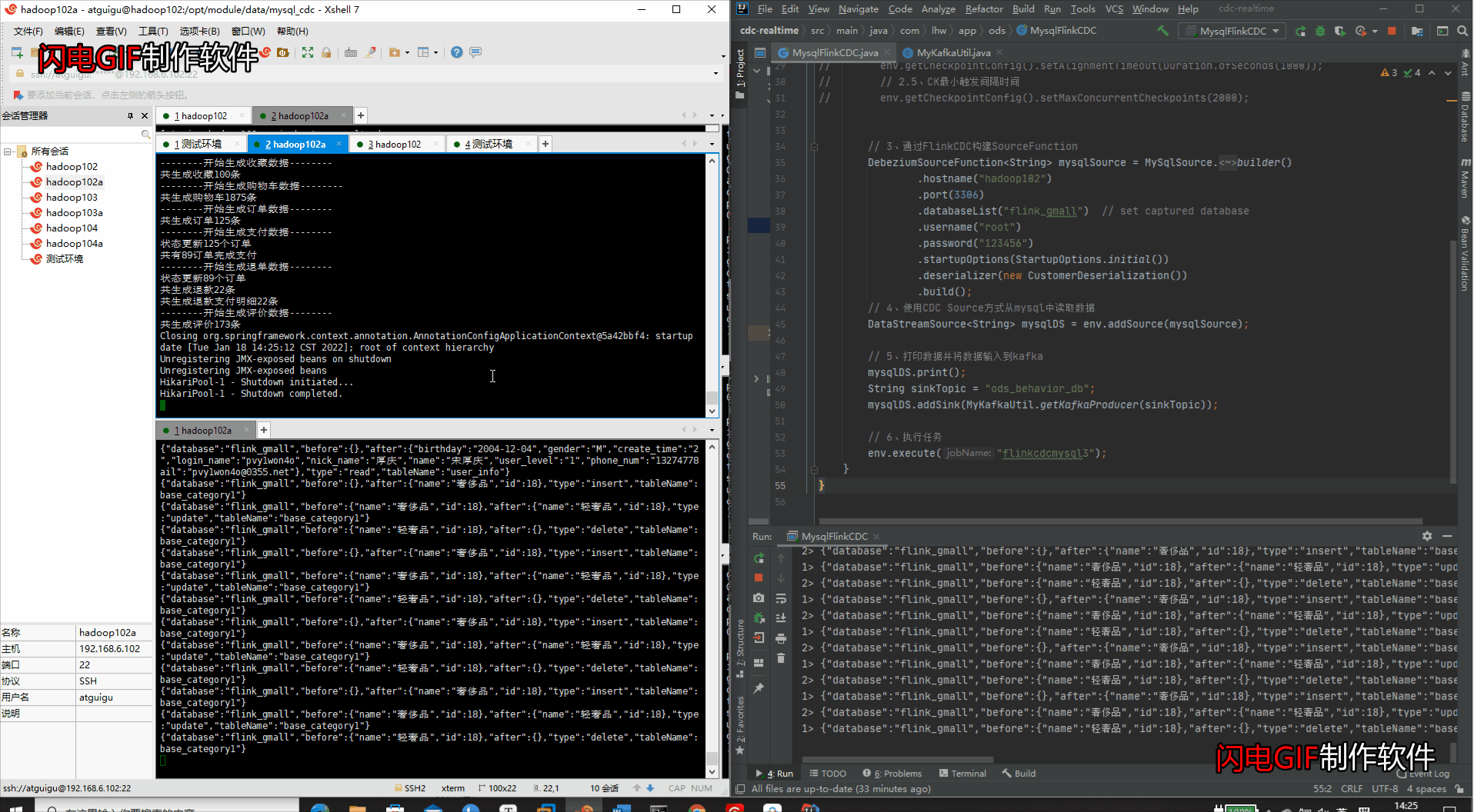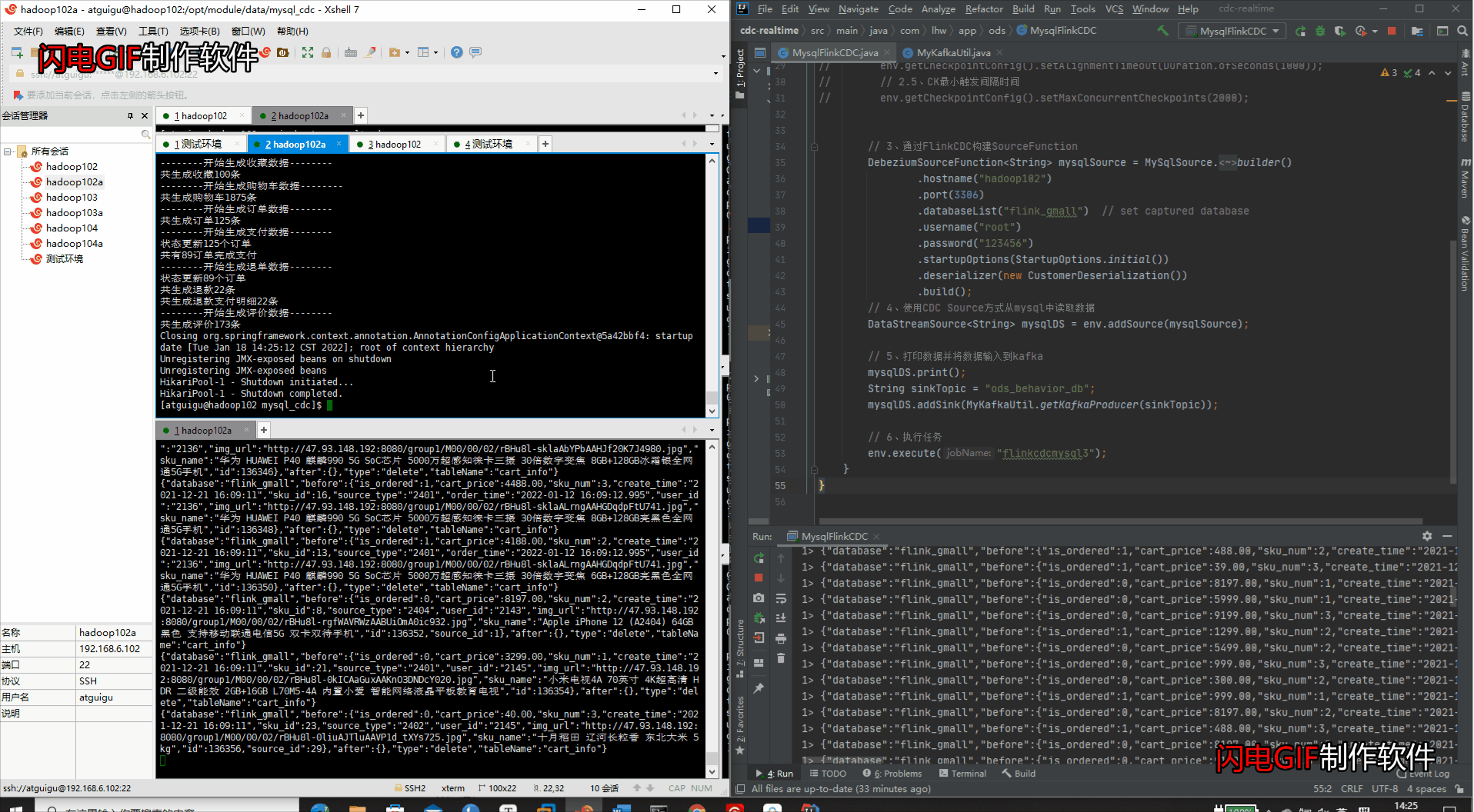
4、打包部署
(1)修改代码
- 添加CK保存位置
package com.lhw.app.ods;
import com.lhw.app.function.CustomerDeserialization;
import com.lhw.utils.MyKafkaUtil;
import com.ververica.cdc.connectors.mysql.MySqlSource;
import com.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.ververica.cdc.debezium.DebeziumSourceFunction;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.time.Duration;
public class MysqlFlinkCDC {
public static void main(String[] args) throws Exception {
// 1、获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
// 2、开启CK并指定状态后端为FS
// 2.1、制定存储ck地址
env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/flinkCDC/flinkcdc-gmall-db"));
// 2.2、指定ck储存触发间隔时间
env.enableCheckpointing(5000);
// 2.3、指定ck模式
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 2.4、指定超时时间
env.getCheckpointConfig().setAlignmentTimeout(Duration.ofSeconds(1000));
// 2.5、CK最小触发间隔时间
env.getCheckpointConfig().setMaxConcurrentCheckpoints(2000);
// 3、通过FlinkCDC构建SourceFunction
DebeziumSourceFunction<String> mysqlSource = MySqlSource.<String>builder()
.hostname("hadoop102")
.port(3306)
.databaseList("flink_gmall") // set captured database
.username("root")
.password("123456")
.startupOptions(StartupOptions.initial())
.deserializer(new CustomerDeserialization())
.build();
// 4、使用CDC Source方式从mysql中读取数据
DataStreamSource<String> mysqlDS = env.addSource(mysqlSource);
// 5、打印数据并将数据输入到kafka
mysqlDS.print();
String sinkTopic = "ods_behavior_db";
mysqlDS.addSink(MyKafkaUtil.getKafkaProducer(sinkTopic));
// 6、执行任务
env.execute("flinkcdcmysql3");
}
}
(2)打全量包
- maven–>package
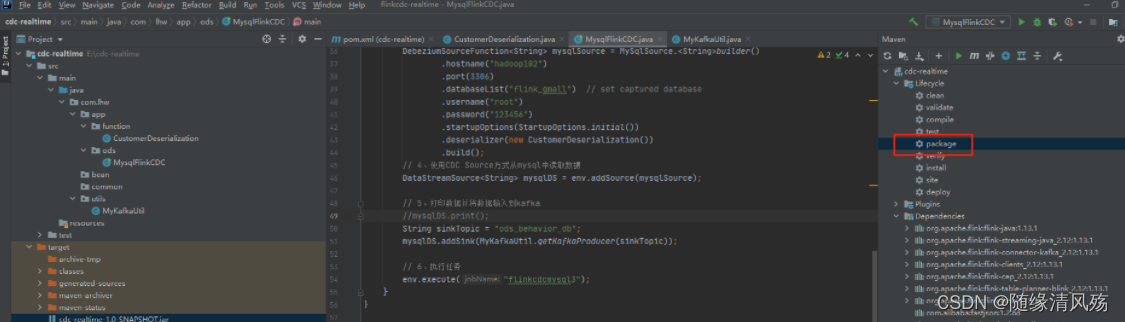
(3)上传脚本并运行
bin/flink run -m hadoop102:8081 -c com.lhw.MysqlFlinkCDC /opt/data/gmall-flinkcdc-mysql.jar
- 查看运行结果
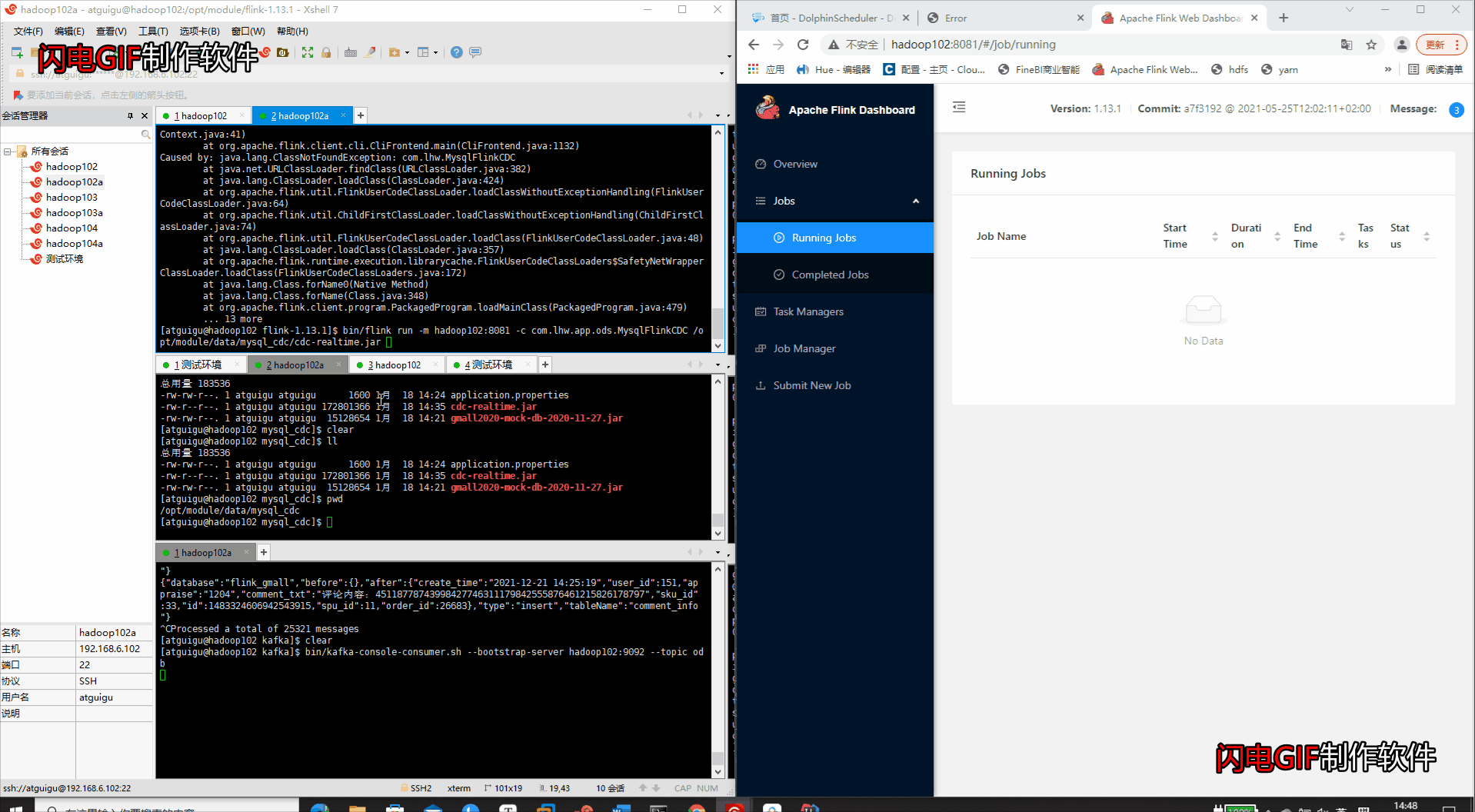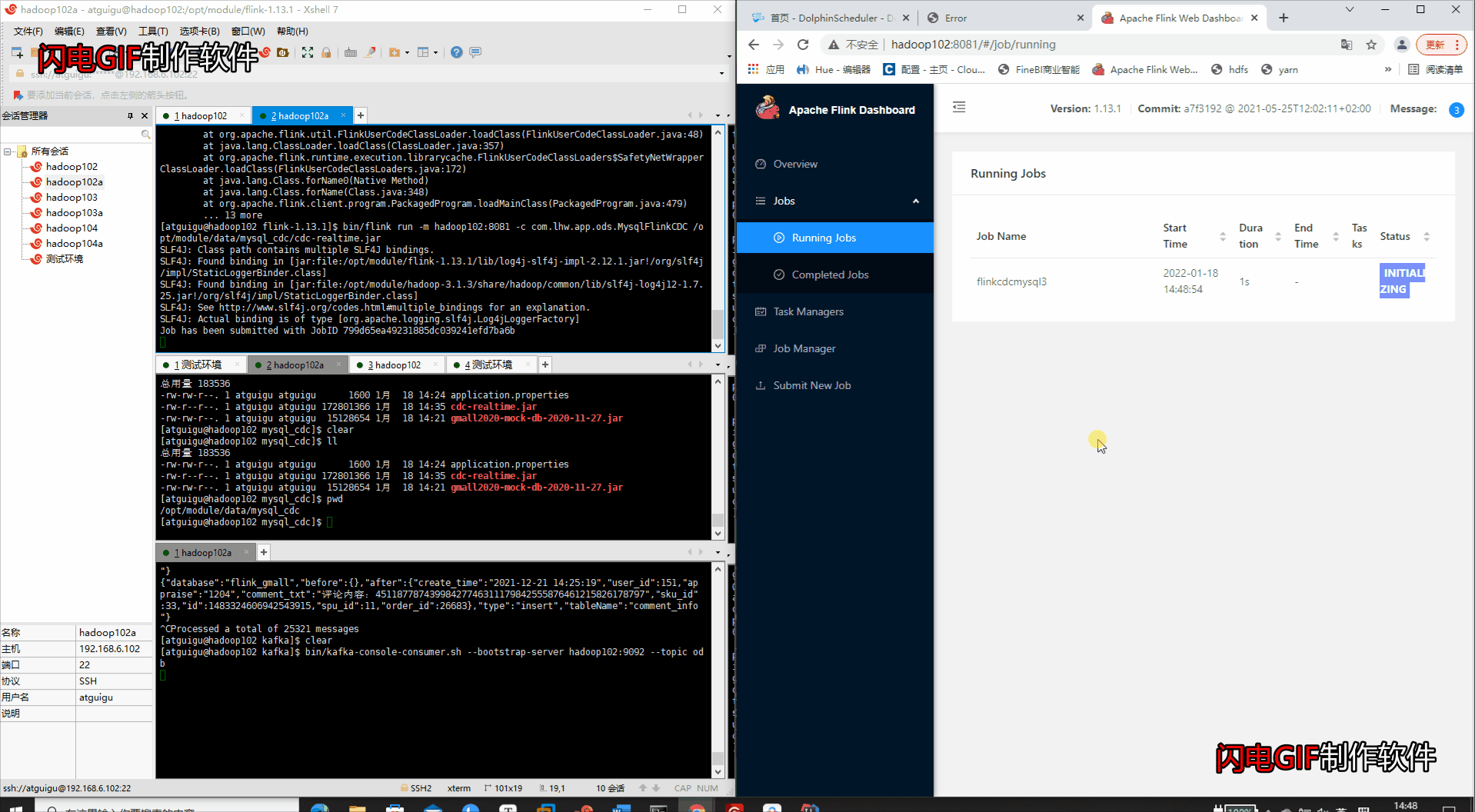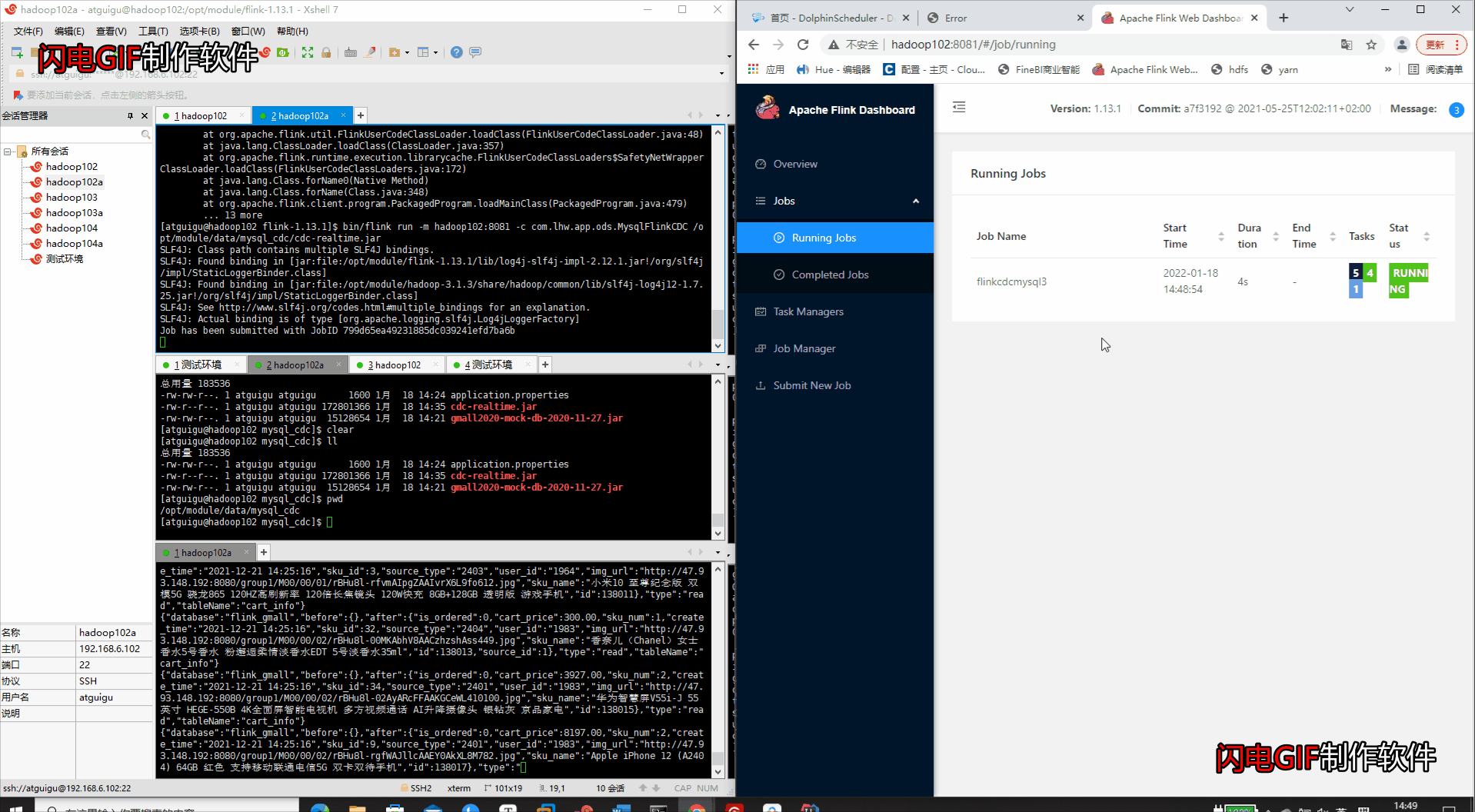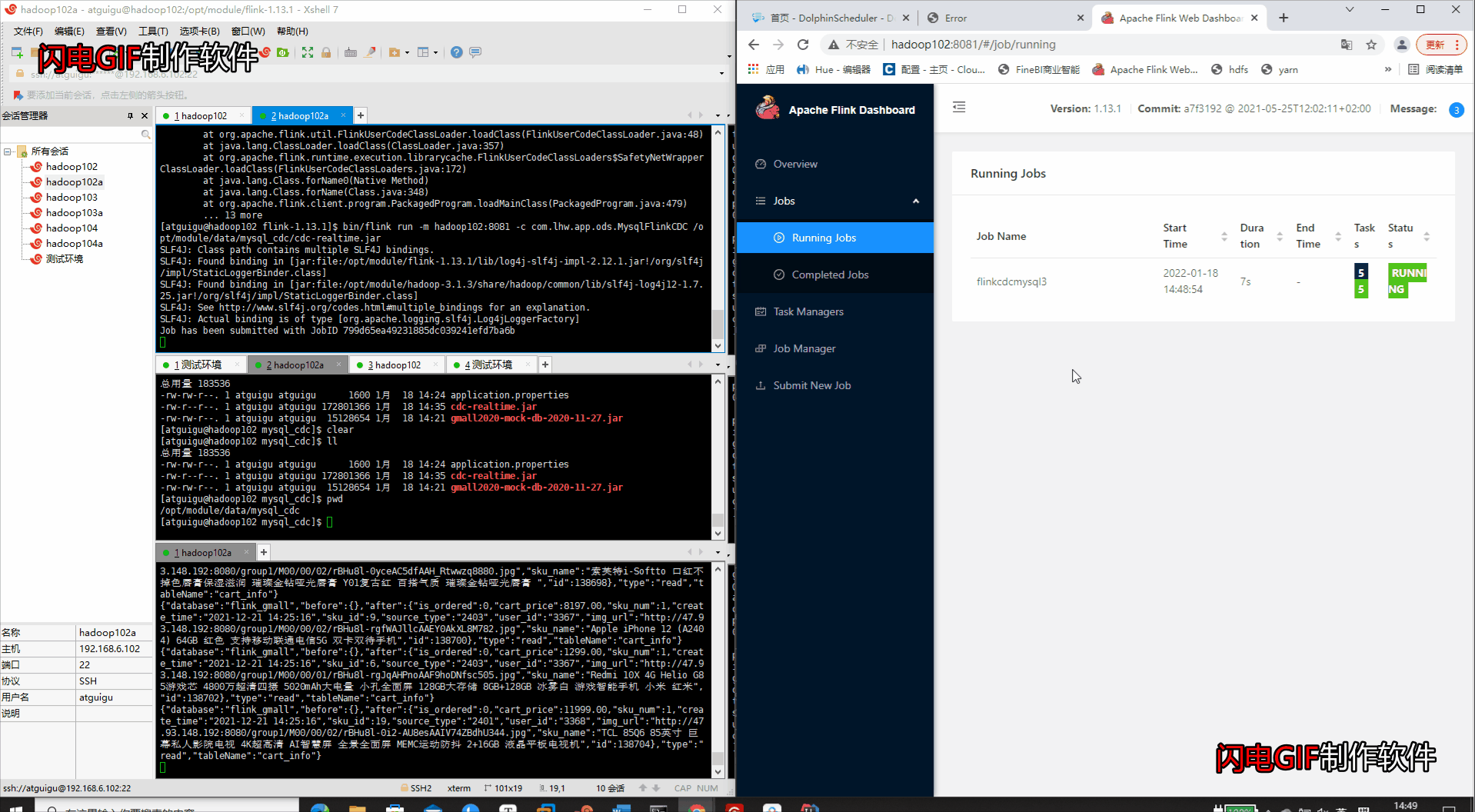
-
查看WEB端的打印输出
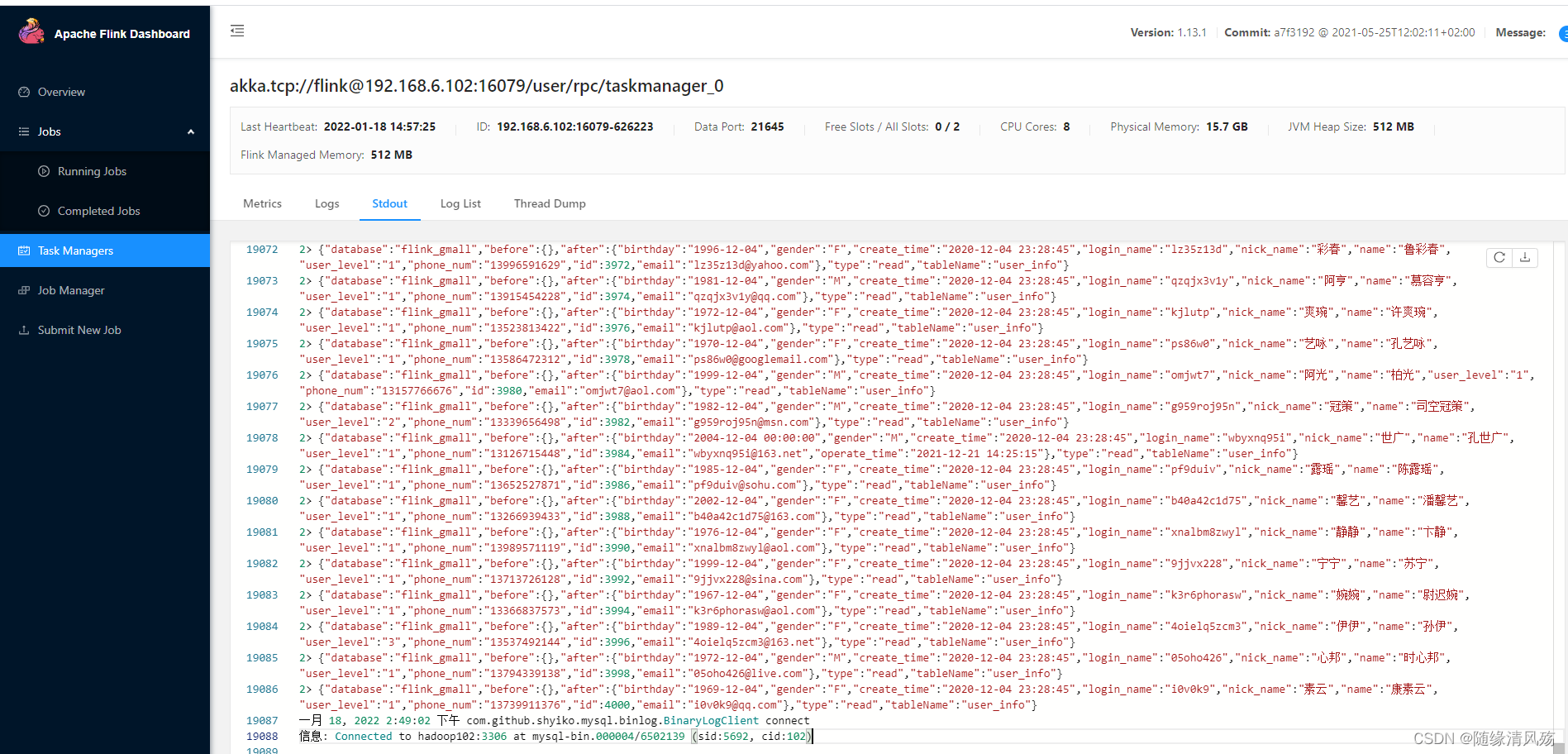
(4)变更业务数据 -
运行业务数据的变更包
java -jar gmall2020-mock-db-2020-11-27.jar
- 查看运行结果(WEB端运行状态 & Kafka消费者消费消息)
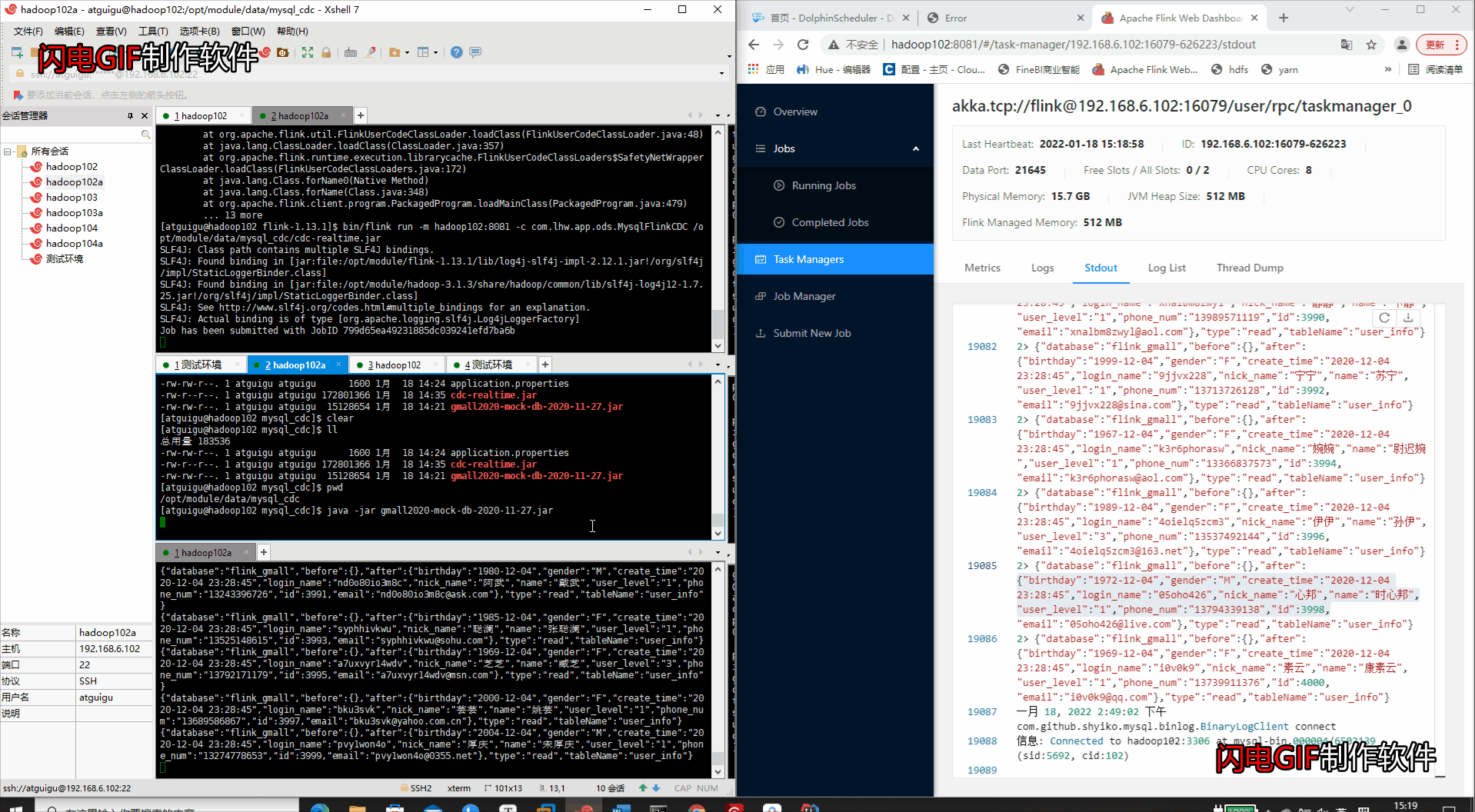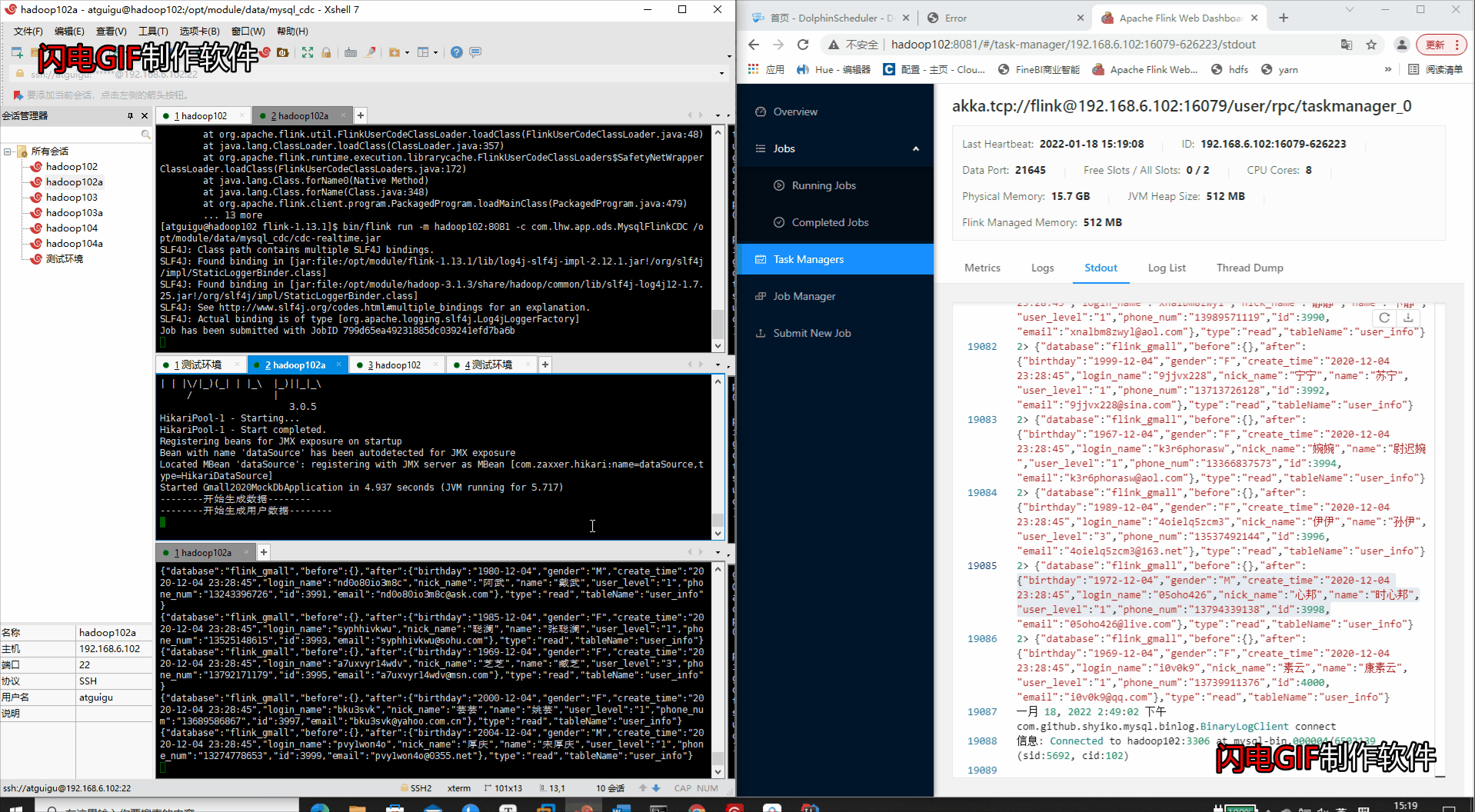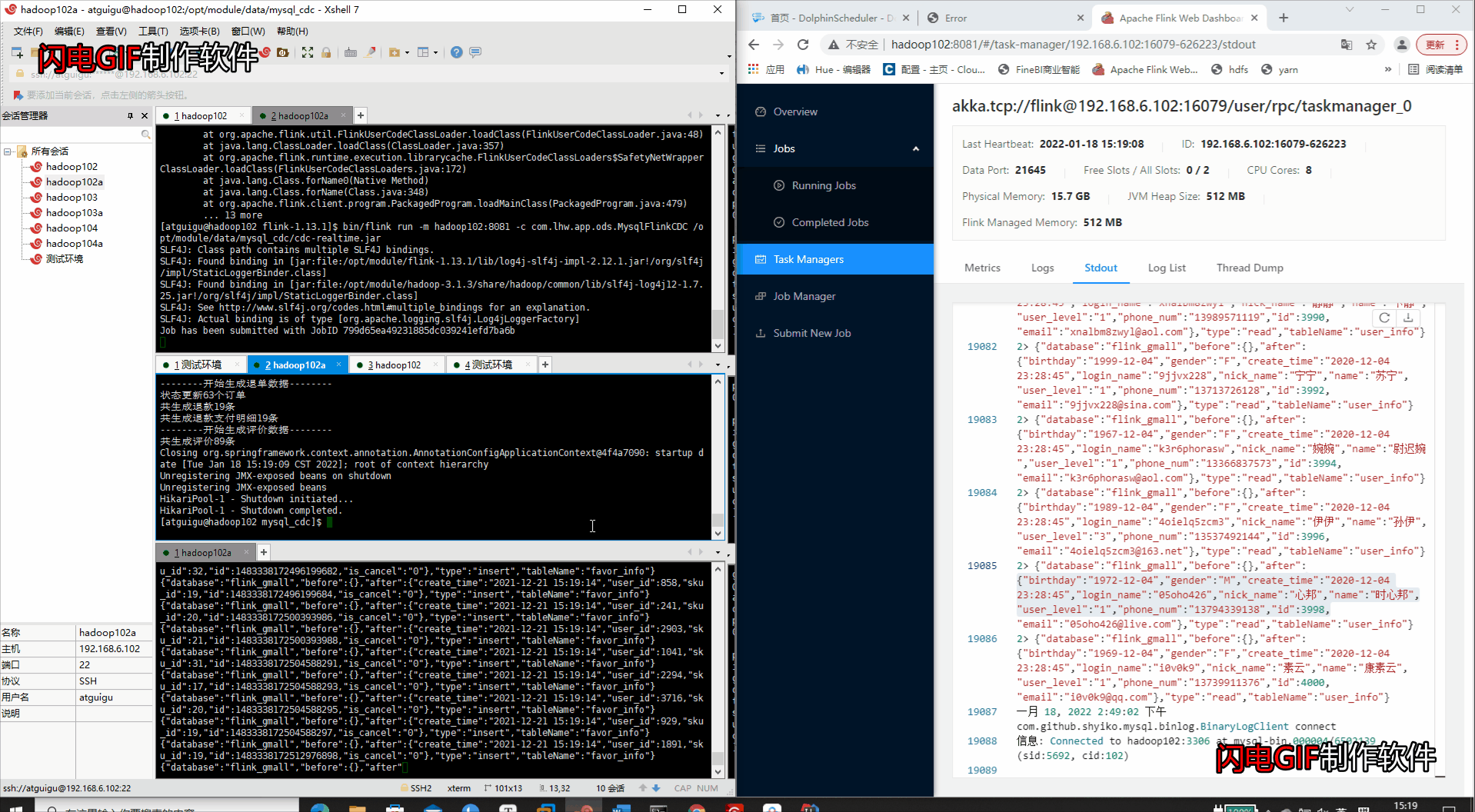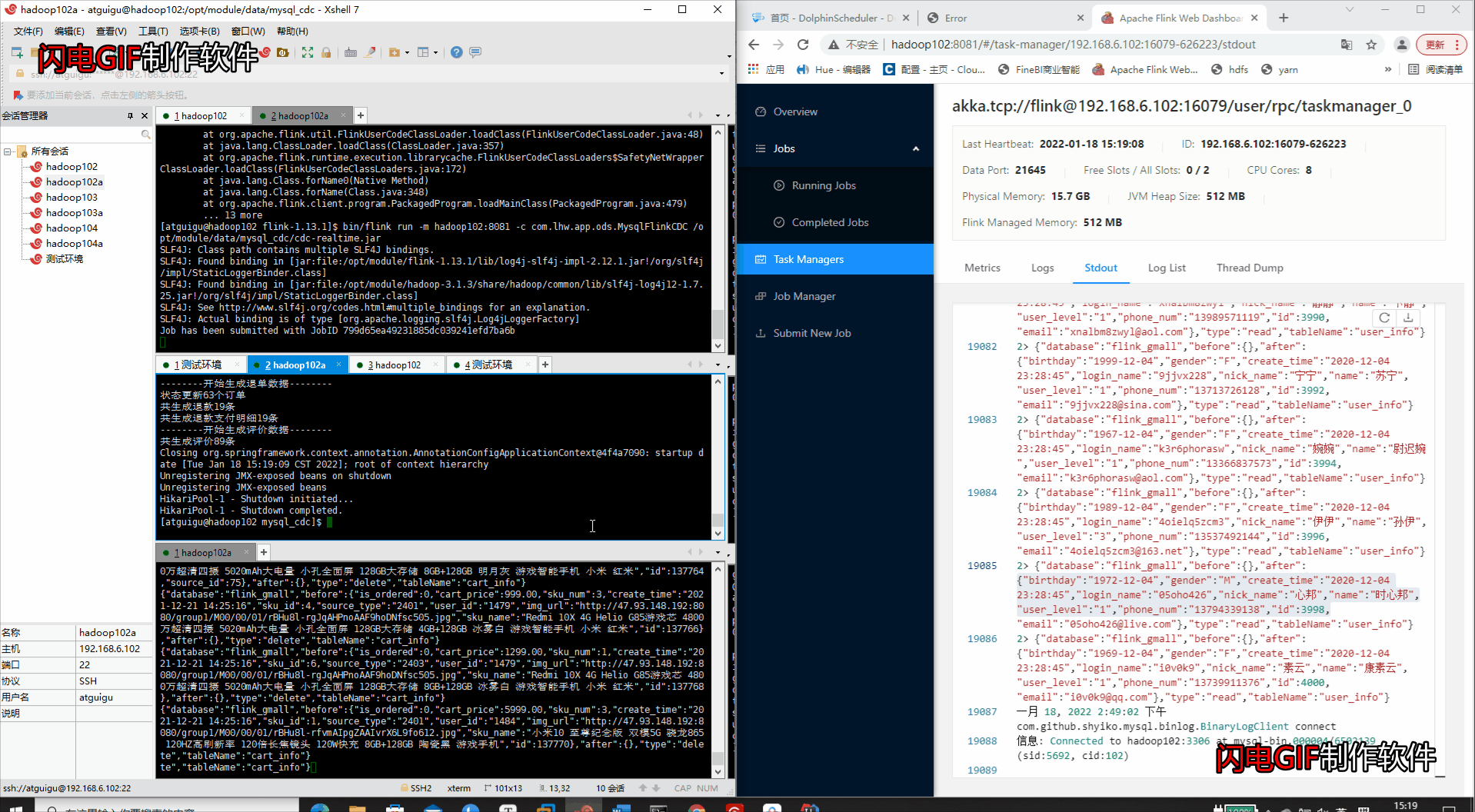
- 查看WEB端的打印输出
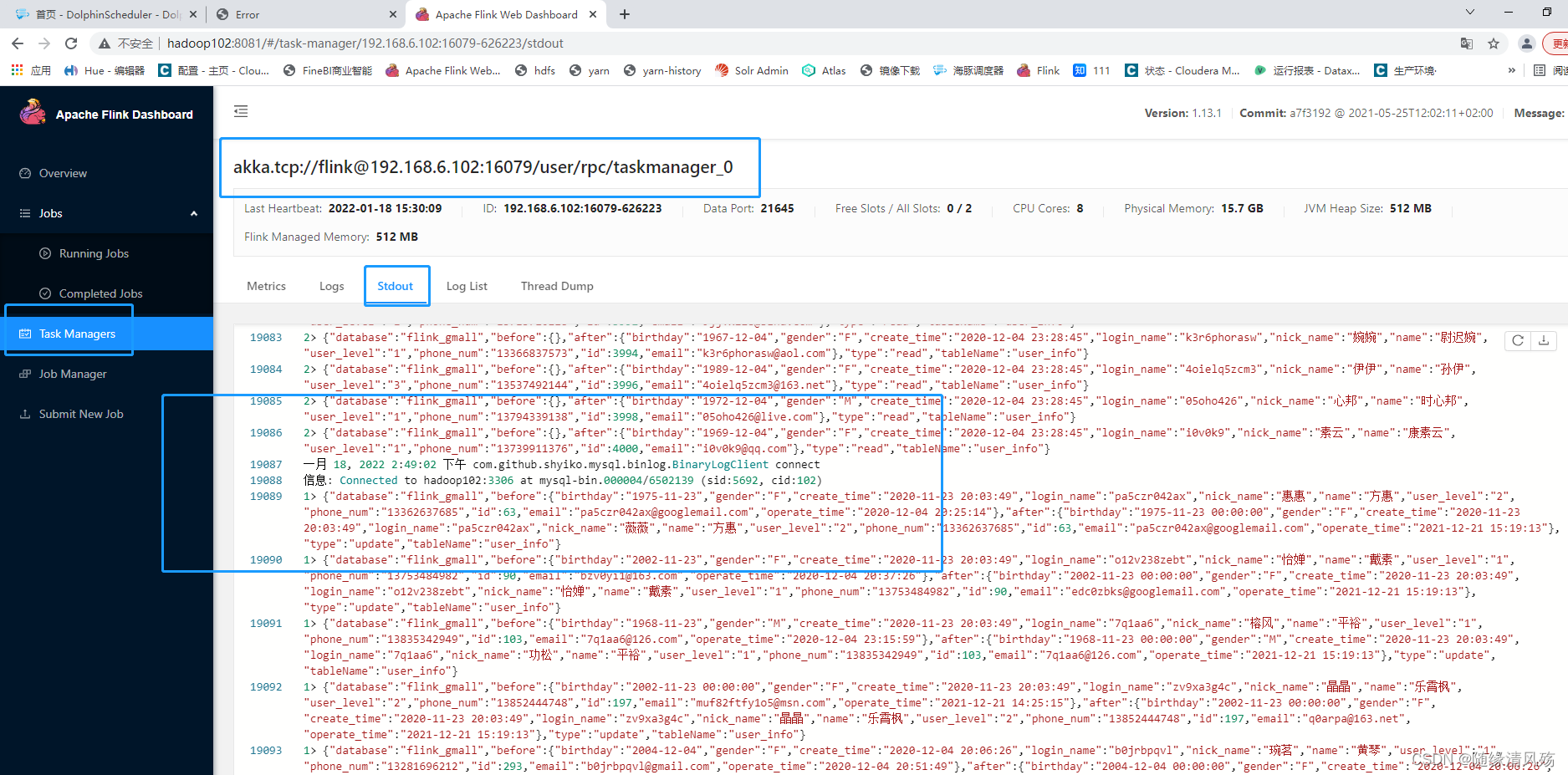
5、代码运行步骤
- 代码路径: /opt/module/data/mysql_cdc

- 启动步骤
#1、启动Flink
bin/start-culter
#2、启动kafka消费者
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic ods_behavior_db
#3、启动flink的WEB端
http://hadoop102:8081/
#4、启动flink任务
bin/flink run -m hadoop102:8081 -c com.lhw.MysqlFlinkCDC /opt/data/gmall-flinkcdc-mysql.jar
- 运行界面
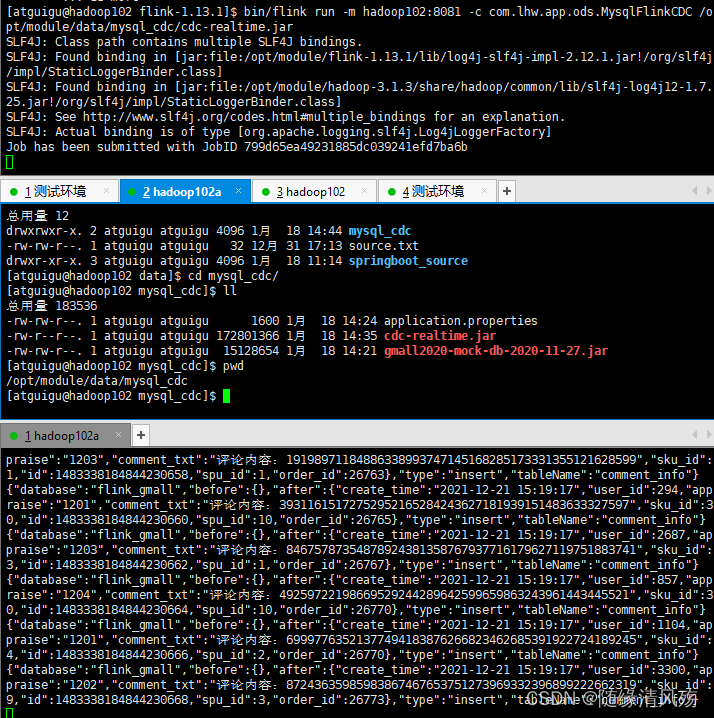
6、源码&资料下载
链接:https://pan.baidu.com/s/1mVRzQ4G5wqKkCAW74IzDOA
提取码:eni1




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











