







1、数据倾斜定义
数据分布不均,造成大量数据集中到一点,造成数据热点。
2、数据倾斜的表现
在执行任务的时候,任务进度长时间维持在99%左右;
查看stage的执行情况时,卡在最后1-2个task长时间不动,查看task监控页面,发现某个或某两三个task运行的时间远远大于其他task的运行时间,这些task处理的数据量也远远大于其他task。
注:一个spark任务的运行时间是由最后一个执行成功的task决定的,如果某个task发生了数据倾斜,会拖慢整个spark任务执行效率,即便其他没有倾斜的task已经执行完毕,甚至会导致OOM
3、查看数据倾斜方法
在yarn界面查看是否产生数据倾斜:
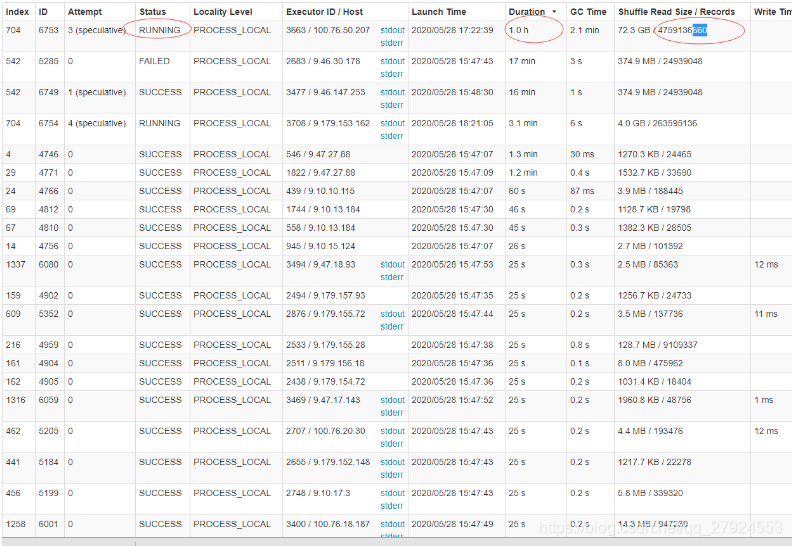
上图是yarn界面task的监控页面,从上图可以看出大部分task的执行时间是25s,处理记录数为几万到几十万不等(处理数据量大部分为几兆到几十兆),但是有一个task处理时间为1小时处理数据量高达72G且还没执行完,此时可以推断数据发生了倾斜,可以通过group by或者抽样找出倾斜key。
4、数据倾斜条件
数据计算时发生了shuffle,即对数据进行了重新分区。
| 关键词 | 情形 | 后果 |
|---|---|---|
| join | 某个或某几个key比较集中,或者存在大量null key | 分发到某一个或者某几个Reduce上的数据远高于平均值 |
| group by | 维度过小,某值的数量过多 | 某个维度或者某几个维度且这些维度的数据量特别大,集中在一个reduce |
5、数据倾斜的解决方案
5.1、特殊情形处理
①同数据类型关联产生数据倾斜
-
情形:比如用户表中user_id字段为int,log表中user_id字段string类型。当按照user_id进行两个表的Join操作时。
-
解决方式:把数字类型转换成字符串类型
select * from users a
left outer join logs b
on a.usr_id = cast(b.user_id as string)
②null key不参与关联
select
a.*
from(
select
*
from log
where user_id is not null
) a
join
users b on a.user_id = b.user_id
union all
select
*
from log where user_id is null
③数据加盐:赋予null值随机值
1. select *
2. from log a
3. left outer join users b
4. on case when a.user_id is null then concat('hive',rand() ) else a.user_id end = b.user_id;
- 两种方式优缺点比较
方法2比方法1效率更好,不但io少了,而且作业数也少了。
解决方法1中 log读取两次,jobs是2。解决方法2 job数是1 ;
这个优化适合无效 id (比如 -99 , ’’, null 等) 产生的倾斜问题。
把空值的 key 变成一个字符串加上随机数,就能把倾斜的数据分到不同的reduce上 ,解决数据倾斜问题。
④提高reduce并行度
设置reduce个数:set mapred.reduce.tasks=15,可以通过改参数提高reduce端并行度,从而缓解数据倾斜的情况。
1>未优化前,假设key1、key2、key3、key4的数据量都是50w,key5是10w,此时key1和key3shuffle到了一个reduce,key2和key4shuffle到了一个reduce,导致有两个reduce task需要处理100w数据,而有一个task只需要处理10w数据,此时数据出现了10倍的倾斜。
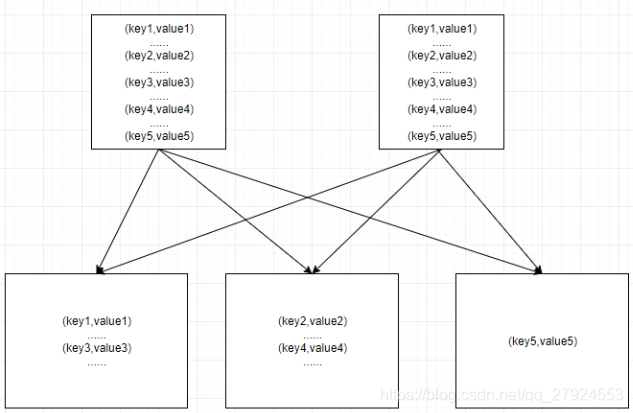
2>优化后,如图所示,为优化前reduce的并行度为3,单个task处理的最大数据量为100w,现在将并行度提高到5,单个task处理的最大数据量为50w,相比之前缓解了5倍的倾斜程度。此方案适合倾斜的程度不是很严重,并有两个以上的倾斜key到shuffle到了同一个reduce。
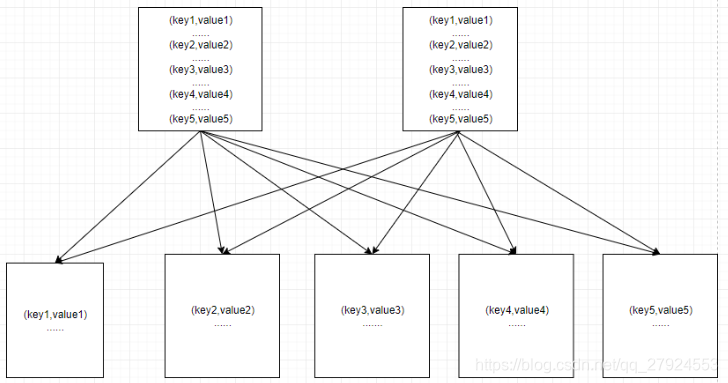
5.2、group by导致的数据倾斜
①开启负载均衡
②group by 双重聚合
当使用group by进行聚合统计时,如果存在某个或某几个key发生了倾斜,会导致某个倾斜key shuffle到一个reduce。
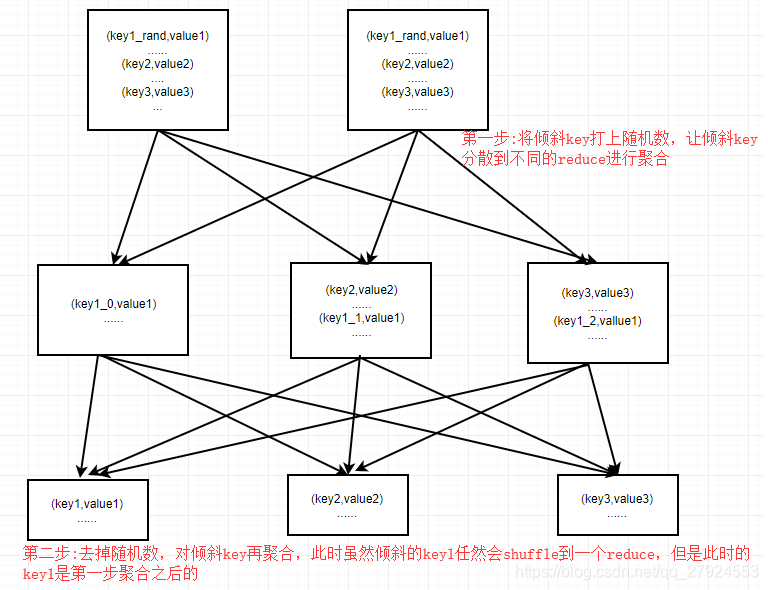
select
split(sp_app_id,'_')[0] sp_app_id
,sum(pv)
from
(
select
sp_app_id||'_'||CAST(CAST(MOD(rand() * 10000,10) AS BIGINT) AS STRING) sp_app_id
,sum(nvl(op_cnt, 1)) pv
from t1
group by sp_app_id||'_'||CAST(CAST(MOD(rand() * 10000,10) AS BIGINT) AS STRING)
) group by split(sp_app_id,'_')[0]
5.3、join导致的数据倾斜
①reduce join 转换成 map join(此方案适合小表join大表的时候)
select /*+ mapjoin(t2)*/ column from table
②过滤倾斜join单独进行join
所以如果把倾斜key过滤出来单独去join,这个倾斜key就会分散到多个task去进行join操作,最后union all。
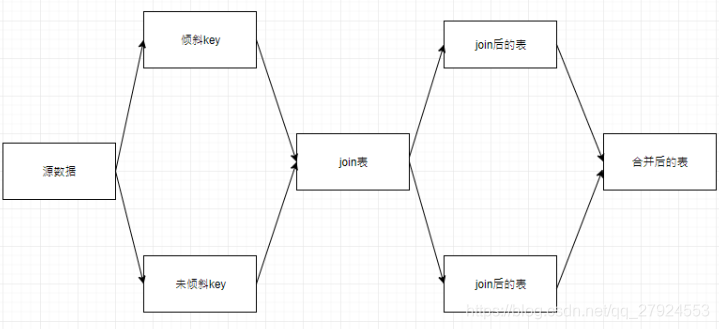
select
*
from
(
select
*
from t1
where rowkey <> '123456789'
) a1 join a2 on a1.rowkey = a2.rowkey
union all
select
*
from
(
select
*
from t1
where rowkey = '123456789'
)a1 join a2 on a1.rowkey = a2.rowkey



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











