






深度学习基本原理:梯度下降公式,将损失函数越来越小,最终预测值和实际值误差比较小。
交叉熵:-p(x)logq(x),p(x)是one-hot形式。如果不使用softmax计算交叉熵,是不行的。损失函数可能会非常大,或者预测的概率是[-0.1,0.3,0.5],log不接收负值。pytorch默认给你加softmax。
如果softmax改成sigmoid也不行,如sigmoid过完以后,[0.9,0.99,0.99],计算以后0.99的影响会被忽略,得到的结果是不正确。
adam和sgd区别:adam会考虑之前的计算,自动调节学习率,在通过上一步计算出来的梯度(放在m_t-1里)和梯度平方(放在v_t-1里)控制学习率的调节,让训练可以比较平稳又可以加速。
transformer和rnn(或lstm)区别:长距离依赖问题,rnn越远影响越弱。
lstm有四个参数,输入门,输出门,记忆门,
调参经验:batch_size,max_length,学习率增大batch_size应该怎么调整,加数据量,打乱数据顺序。
训练词向量:将one-hot乘以一个矩阵进行训练,cbow多个词预测中间一个词,skip-gram一个词预测周围词,共现矩阵,keans聚类。
也可以参考损失函数,用到的损失函数有余弦值、三元组等。用余弦值训练的话,两个相似的词向量,cos值接近1。用余弦值损失函数时,将相似的两个词作为正样本,如你好和您好是输入,真实输出是1,负样本真实输出是-1,来训练模型参数,最后得到词向量数据库。
语言模型:PPL评价语言模型,不能成句也可能PPL比较低,所以PPL评价不太好。
传统方法和预训练方法:
Transformer里的dk是hidden_size/ head_num,是实验结果。
数据稀疏问题:标注更多数据,大模型生成更多数据,换模型,调整阈值,召回率换准确率。重新定义类别,减少类别,增加规则弥补。
文本匹配:表示型,直接计算,交互型,速度慢,更准确。文本向量化:文本和句子分别过一个模型,优化模型,使文本和句子相似,如果是句子和句子可以用相同模型,最后得到的参数作为向量数据库。表示型:一个句子直接向量化,交互型:必须进入两个句子算得分。
向量数据库查找:KD树。
序列标注:crf会用维特比解码,bean search在大模型里使用,n * D *B,复杂度小很多
ner:加标点任务。
序列标注重复:多个模型,生成式任务,输出两个标记。
自回归语言模型:下三角mask,预测下一个词。
teacher-forcing,使用真实标签预测,提高效率。
采样策略:topk,topp,bean-size,temperature(大模型)。
bert变体:albert跨层参数共享,嵌入参数化进行因式分解,nsp任务(相邻句子就是正样本)改成sop任务,sop任务提高训练难度。roberta(动态mask,去掉nsp任务),spanbert:mask掉多个连续的
stf用于大模型问答,相当于encoder-decoder,bert是encoder,通过mask可以实现decoder自回归语言模型(文本生成)。
旋转位置编码:解决词嵌入位置编码长度外推性,找到映射f,满足
< f_q(x_m,m), f_k(x_n,n)> = g(x_m, x_n, m - n)。初始条件m = 0, f(q,0) = q。
https://zhuanlan.zhihu.com/p/580739696

qm(1),qm(2)是原来的Wq和xm相乘的局部结果,即xm.dot(Wq)
余弦值位置编码中:固定i,则pos的改变会使位置编码有周期性,固定pos修改i,则一开始周期较小,容易捕捉相邻字的差别,随着i变大,周期越来越长
moe专家模型(一个MLP层就是一个专家),deepseek使用共享专家。deepseek在qkv计算的过程中,q和k拆成两部分,其中一部分注入rope位置信息,另一部分不处理。减少运算量。deepseek还使用了GRPO,在训练奖励模型RM时,奖励指标是硬规则,即要么是要么不是,而且每次输入多个输入输出,一次性训练。
LLM模型先进行sft训练,如果是PPO的话,就还需要训练一个奖励模型即RM模型。然后第三步进行RL强化训练,这里将sft训练得到的模型叫做reference模型,然后复制出来模型,叫做RL模型,或者演员模型,这个演员模型就是最后训练出来的模型,那么损失函数的构成就是RM模型减去演员模型和reference模型组成的KL散度。整个过程可以理解成是对stf训练进行微调,即保证演员模型不会和stf偏离的太远,又让奖励模型得分尽可能高,这样符合人类偏好,所以PPO叫近端策略优化,也可以看做人类偏好优化。
bbpe:解决多语种,不用统计词,既不是中文词表也不是英文词表,具有跨语种的优点,大语言模型用的词表就是采用bbpe。bpe是基于字符,bbpe是转化为unicode编码,然后合并,是基于字节的。
知识图谱:方法一是基于模板+文本匹配,类似于faq库问答,相似度可以用bm25,jaccard距离,或者余弦距离。方法二:拆解成多个分类或抽取问题处理。方法三:利用大语言LLM的生成能力
推荐系统:基于相似用户、相似物品的推荐。
import torch
import math
import numpy as np
from transformers import BertModel
'''
通过手动矩阵运算实现Bert结构
模型文件下载 https://huggingface.co/models
'''
bert = BertModel.from_pretrained(r"/Users/mac/Documents/bert-base-chinese", return_dict=False)
# print(bert)
state_dict = bert.state_dict()
bert.eval()
x = np.array([2450, 15486, 102, 2110]) #假想成4个字的句子
torch_x = torch.LongTensor([x])
seqence_output, pooler_output = bert(torch_x)
print(seqence_output.shape, pooler_output.shape)
# torch.Size([1, 4, 768]) torch.Size([1, 768])
print(bert.state_dict().keys()) #查看所有的权值矩阵名称
#softmax归一化
def softmax(x):
return np.exp(x)/np.sum(np.exp(x), axis=-1, keepdims=True)
#gelu激活函数
def gelu(x):
return 0.5 * x * (1 + np.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * np.power(x, 3))))
class DiyBert:
#将预训练好的整个权重字典输入进来
def __init__(self, state_dict):
self.num_attention_heads = 12
self.hidden_size = 768
self.num_layers = 1 #注意这里的层数要跟预训练config.json文件中的模型层数一致
self.load_weights(state_dict)
def load_weights(self, state_dict):
self.word_embeddings = state_dict["embeddings.word_embeddings.weight"].numpy()
self.position_embeddings = state_dict["embeddings.position_embeddings.weight"].numpy()
self.token_type_embeddings = state_dict["embeddings.token_type_embeddings.weight"].numpy()
self.embeddings_layer_norm_weight = state_dict["embeddings.LayerNorm.weight"].numpy()
self.embeddings_layer_norm_bias = state_dict["embeddings.LayerNorm.bias"].numpy()
self.transformer_weights = []
#transformer部分,有多层
for i in range(self.num_layers):
q_w = state_dict["encoder.layer.%d.attention.self.query.weight" % i].numpy()
q_b = state_dict["encoder.layer.%d.attention.self.query.bias" % i].numpy()
k_w = state_dict["encoder.layer.%d.attention.self.key.weight" % i].numpy()
k_b = state_dict["encoder.layer.%d.attention.self.key.bias" % i].numpy()
v_w = state_dict["encoder.layer.%d.attention.self.value.weight" % i].numpy()
v_b = state_dict["encoder.layer.%d.attention.self.value.bias" % i].numpy()
attention_output_weight = state_dict["encoder.layer.%d.attention.output.dense.weight" % i].numpy()
attention_output_bias = state_dict["encoder.layer.%d.attention.output.dense.bias" % i].numpy()
attention_layer_norm_w = state_dict["encoder.layer.%d.attention.output.LayerNorm.weight" % i].numpy() # 做残差时的线性层
attention_layer_norm_b = state_dict["encoder.layer.%d.attention.output.LayerNorm.bias" % i].numpy()
intermediate_weight = state_dict["encoder.layer.%d.intermediate.dense.weight" % i].numpy() # 前馈网络的处理
intermediate_bias = state_dict["encoder.layer.%d.intermediate.dense.bias" % i].numpy() # 前馈网络的处理
output_weight = state_dict["encoder.layer.%d.output.dense.weight" % i].numpy() # 前馈网络的处理
output_bias = state_dict["encoder.layer.%d.output.dense.bias" % i].numpy() # 前馈网络的处理
ff_layer_norm_w = state_dict["encoder.layer.%d.output.LayerNorm.weight" % i].numpy()
ff_layer_norm_b = state_dict["encoder.layer.%d.output.LayerNorm.bias" % i].numpy()
self.transformer_weights.append([q_w, q_b, k_w, k_b, v_w, v_b, attention_output_weight, attention_output_bias,
attention_layer_norm_w, attention_layer_norm_b, intermediate_weight, intermediate_bias,
output_weight, output_bias, ff_layer_norm_w, ff_layer_norm_b])
#pooler层
self.pooler_dense_weight = state_dict["pooler.dense.weight"].numpy()
self.pooler_dense_bias = state_dict["pooler.dense.bias"].numpy()
#bert embedding,使用3层叠加,在经过一个Layer norm层
def embedding_forward(self, x):
# x.shape = [max_len]
we = self.get_embedding(self.word_embeddings,x) # shpae: [max_len, hidden_size]
# position embeding的输入 [0, 1, 2, 3]
pe = self.get_embedding(self.position_embeddings, np.array(list(range(len(x))))) # shpae: [max_len, hidden_size]
# token type embedding,单输入的情况下为[0, 0, 0, 0]
te = self.get_embedding(self.token_type_embeddings, np.array([0] * len(x))) # shpae: [max_len, hidden_size]
embedding = we + pe + te
# 加和后有一个归一化层
embedding = self.layer_norm(embedding, self.embeddings_layer_norm_weight, self.embeddings_layer_norm_bias)
return embedding
#embedding层实际上相当于按index索引,或理解为onehot输入乘以embedding矩阵
def get_embedding(self, embedding_matrix, x):
return np.array([embedding_matrix[index] for index in x]) #不是从0开始的,是每个词对应的位置
#归一化层
def layer_norm(self, x, w, b):
x = (x - np.mean(x, axis=1, keepdims=True)) / np.std(x, axis=1, keepdims=True)
x = x * w + b
return x
#执行全部的transformer层计算
def all_transformer_layer_forward(self, x):
for i in range(self.num_layers):
x = self.single_transformer_layer_forward(x, i)
return x
#执行单层transformer层计算
def single_transformer_layer_forward(self, x, layer_index):
weights = self.transformer_weights[layer_index]
#取出该层的参数,在实际中,这些参数都是随机初始化,之后进行预训练
q_w, q_b, \
k_w, k_b, \
v_w, v_b, \
attention_output_weight, attention_output_bias, \
attention_layer_norm_w, attention_layer_norm_b, \
intermediate_weight, intermediate_bias, \
output_weight, output_bias, \
ff_layer_norm_w, ff_layer_norm_b = weights
#self attention层
attention_output = self.self_attention(x,
q_w, q_b,
k_w, k_b,
v_w, v_b,
attention_output_weight, attention_output_bias,
self.num_attention_heads,
self.hidden_size)
#bn层,并使用了残差机制
x = self.layer_norm(x + attention_output,attention_layer_norm_w, attention_layer_norm_b)
#feed forward层
feed_forward_x = self.feed_forward(x, intermediate_weight, intermediate_bias, output_weight, output_bias)
#bn层,并使用了残差机制
x = self.layer_norm(x + feed_forward_x, ff_layer_norm_w, ff_layer_norm_b) #最后一次归一化+前馈网络
return x
def self_attention(self, x, q_w, q_b, k_w, k_b, v_w, v_b,attention_output_weight,
attention_output_bias,num_attention_heads,hidden_size):
# x.shape = max_len * hidden_size
# q_w, k_w, v_w shape = hidden_size * hidden_size
# q_b, k_b, v_b shape = hidden_size
q = np.dot(x, q_w.T) + q_b # shape: [max_len, hidden_size]
k = np.dot(x, k_w.T) + k_b # shape: [max_len, hidden_size]
v = np.dot(x, v_w.T) + v_b # shape: [max_len, hidden_size]
attention_head_size = int(hidden_size / num_attention_heads)
# q.shape = num_attention_heads, max_len, attention_head_size
q = self.transpose_for_scores(q, attention_head_size, num_attention_heads)
# k.shape = num_attention_heads, max_len, attention_head_size
k = self.transpose_for_scores(k, attention_head_size, num_attention_heads)
# v.shape = num_attention_heads, max_len, attention_head_size
v = self.transpose_for_scores(v, attention_head_size, num_attention_heads)
# qk.shape = num_attention_heads, max_len, max_len
qk = np.matmul(q, k.swapaxes(1,2))
qk /= np.sqrt(attention_head_size)
qk = softmax(qk)
# qkv.shape = num_attention_heads, max_len, attention_head_size
qkv = np.matmul(qk, v)
# qkv.shape = max_len, hidden_size
qkv = qkv.swapaxes(0, 1).reshape(-1, hidden_size)
# attention.shape = max_len, hidden_size
attention = np.dot(qkv, attention_output_weight.T) + attention_output_bias
return attention
# 多头机制
def transpose_for_scores(self, x, attention_head_size, num_attention_heads):
# hidden_size = 768 num_attent_heads = 12 attention_head_size = 64
max_len, hidden_size = x.shape
x = x.reshape(max_len, num_attention_heads, attention_head_size)
# swapaxes两轴相转
x = x.swapaxes(1, 0) # output shape = [num_attention_heads, max_len, attention_head_size]
return x
#前馈网络的计算
def feed_forward(self,
x,
intermediate_weight, # intermediate_size, hidden_size
intermediate_bias, # intermediate_size
output_weight, # hidden_size, intermediate_size
output_bias # hidden_size
):
# output shpae: [max_len, intermediate_size]
x = np.dot(x, intermediate_weight.T) + intermediate_bias
x = gelu(x)
# output shpae: [max_len, hidden_size]
x = np.dot(x, output_weight.T) + output_bias
return x # 经过feed Forward,结构还是V * hidden_size(768)
#链接[cls] token的输出层
def pooler_output_layer(self, x):
x = np.dot(x, self.pooler_dense_weight.T) + self.pooler_dense_bias
x = np.tanh(x)
return x
def forward(self, x):
x =self.embedding_forward(x)
sequence_output = self.all_transformer_layer_forward(x)
pooler_output = self.pooler_output_layer(sequence_output[0])
return sequence_output, pooler_output
#测试
db = DiyBert(state_dict)
diy_sequence_output, diy_pooler_output = db.forward(x)
#torch
torch_sequence_output, torch_pooler_output = bert(torch_x)
print(diy_sequence_output)
print(torch_sequence_output)
# print(diy_pooler_output)
# print(torch_pooler_output)
T5:encode-decode模型,
bert:


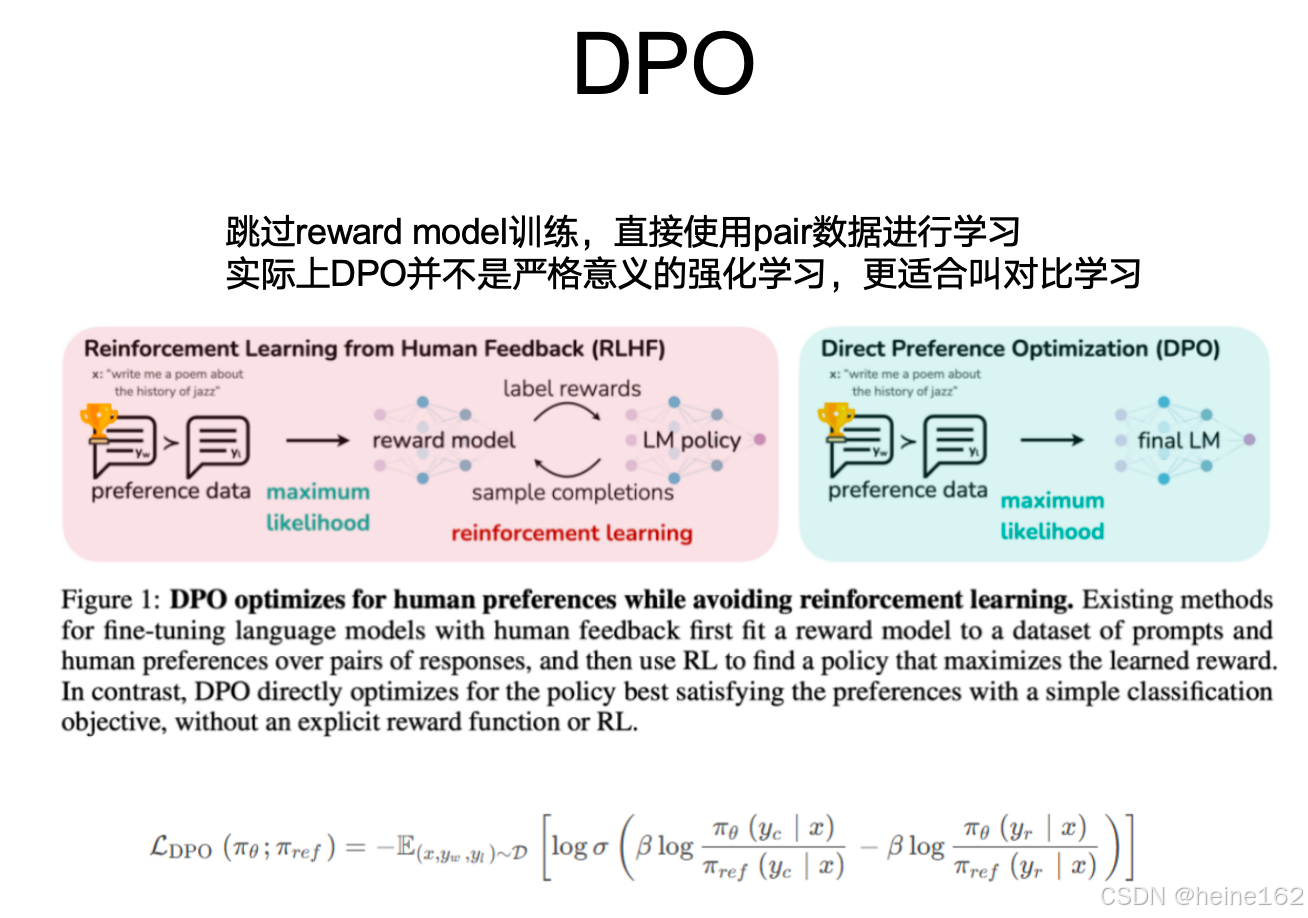
ppo中,主要训练演员(actor)模型一开始和sft模型相同,以及评论家(critic)模型一开始和RM奖励模型相同,演员模型负责生成动作,核心目标是最大化累积奖励。
收集的数据包括状态、动作、动作概率和奖励等信息。使用广义优势函数GAE来计算优势函数。
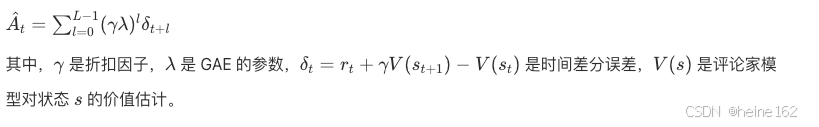
重要性采样比:

重要性采样比和GAE构成目标损失函数:

利用梯度上升法最大化目标函数,更新演员模型参数θ。
5.10面试题:
multi-head有什么优点,是否冗余?
dpo和RLHF如何解决模型幻觉问题?


















 764
764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











