






二叉树结构:
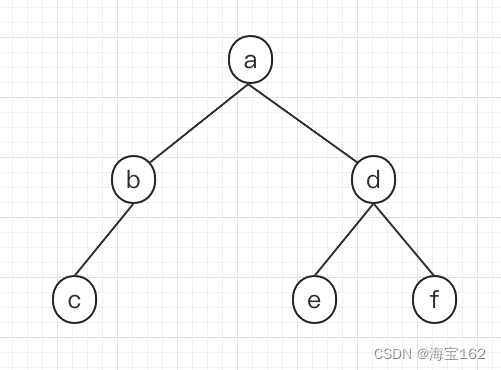
输入#符号表示节点结束:

重要性质:
1.在二叉树的第k层上至多有个结点
2.深度为k的二叉树至多有个节点(此时为满二叉树)
3.
(1)
一个非根节点的节点,总是会有一个父节点挂着它,所以分支的数量B等于非根节点的数量,所以 (2)
(1)式-(2)式得到
4.有n个节点的二叉树深度为
5.完全二叉树中编号为i的节点,左孩子编号为2i,右孩子编号为2i+1。2i大于节点总数n则无左孩子,2i+1大于右孩子则无右孩子。该性质在堆排序中很重要,根据最后一个节点k需要得出最后一个非叶子节点位置k/2或者(k-1)/2。
1. 先序遍历,中序遍历,后序遍历
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdlib.h>
#include <time.h>
typedef struct BiTNode
{
char data;
struct BiTNode *lchild, *rchild;
} BiTNode, *BiTree;
void CreateBiTree(BiTree &T)
{
char data;
scanf("%c", &data);
while (getchar() != '\n')
{
;
} // 清除scanf缓存区
if (data != '#')
{
T = (struct BiTNode *)malloc(sizeof(struct BiTNode));
T->lchild = NULL;
T->rchild = NULL;
T->data = data;
CreateBiTree(T->lchild);
CreateBiTree(T->rchild);
} else {
T = NULL; // 孩子节点为空
}
}
void CenterInOrderTraverse(BiTree &T)
{
if (T)
{
CenterInOrderTraverse(T->lchild);
printf("节点字符%c\n", T->data);
CenterInOrderTraverse(T->rchild);
}
}
void FrontInOrderTraverse(BiTree &T)
{
if (T)
{
printf("节点字符%c\n", T->data);
FrontInOrderTraverse(T->lchild);
FrontInOrderTraverse(T->rchild);
}
}
void EndInOrderTraverse(BiTree &T)
{
if (T)
{
EndInOrderTraverse(T->lchild);
EndInOrderTraverse(T->rchild);
printf("节点字符%c\n", T->data);
}
}
int main()
{
BiTree T;
CreateBiTree(T);
// a
// b d
// c # e f
// # # # # # #
// 输入abc###de##f##
// CenterInOrderTraverse(T); // cbaedf
FrontInOrderTraverse(T); // abcdef
// EndInOrderTraverse(T); // cbefda
return 0;
}输入:abc###de##f##,生成二叉树。
- 中序遍历:为cbaedf。
- 先序遍历:abcdef。
- 后序遍历:cbefda。
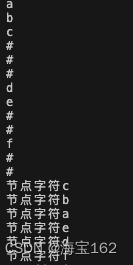
2. 使用链表栈实现非递归的中序遍历
链表栈里的数据保存的是二叉树的节点BiTreeNode结构主要步骤:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdlib.h>
#include <time.h>
// 中序遍历的非递归算法
// 二叉树
typedef struct BiTreeNode
{
char data;
struct BiTreeNode *lchild, *rchild;
} BiTreeNode, *BiTree;
// 链表栈
typedef struct StackNode {
struct BiTreeNode *tree;
struct StackNode *next;
} StackNode, *LinkStack;
int isEmptyStack(LinkStack &S) {
if (S == NULL) {
return 1; // 空栈
} else {
return 0;
}
}
void InitBiTree(BiTree &T)
{
char ch;
scanf("%c", &ch);
while (getchar() != '\n')
{
;
}
if (ch != '#')
{
T = (BiTreeNode *)malloc(sizeof(struct BiTreeNode));
T->data = ch;
T->lchild = NULL;
T->rchild = NULL;
InitBiTree(T->lchild);
InitBiTree(T->rchild);
}
}
// 不需要初始化空节点,直接为空
void InitStack(LinkStack &S) {
S = NULL;
}
void PushStack(LinkStack &S, BiTree &T) {
struct StackNode *p = (struct StackNode *)malloc(sizeof(struct StackNode));
p->tree = T;
p->next = S; // S代表地址;
S = p; // p也是地址
}
void PopStack(LinkStack &S, BiTree &T) {
if (S) {
T = S->tree;
S = S->next;
}
}
// 中序遍历的非递归算法
void CenterTraverseByStack(LinkStack &S, BiTree T) {
BiTree p = T; // 不要直接操作p里的值,参数一般为BiTree T而不是BiTree &T。
while (p || !isEmptyStack(S)) { // p不存在,弹出栈顶元素访问,下次循环栈顶的右孩子
if(p) {
PushStack(S, p); // 将数据入栈,指针p指向
p = p->lchild;
} else {
BiTree q;
PopStack(S, q);
printf("%c ", q->data);
p = q->rchild;
}
}
}
void CenterTraverse(BiTree &T)
{
if (T)
{
CenterTraverse(T->lchild);
printf("%c ", T->data);
CenterTraverse(T->rchild);
}
}
int main()
{
BiTree T;
// a
// b d
// c # e f
// # # # # # #
// 输入abc###de##f##
puts("---输入abc###de##f##创建二叉树---");
InitBiTree(T);
puts("---中序遍历---");
CenterTraverse(T); // c b a e d f
LinkStack S;
InitStack(S);
puts("---使用栈遍历树---");
CenterTraverseByStack(S, T);
puts("---end---");
return 0;
}
3. 复制二叉树
将二叉树进行遍历,然后将里面的每个节点复制到另一个空树中,以javascript为例:
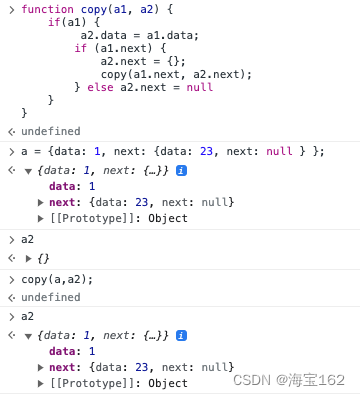
JavaScript里不要对形参直接等于号操作,那样当前循环的等于号操作改变不了上一个循环调用的实参里的成员。C语言里我们可以传入引用&NewT,然后NewT = xxx影响实参:
void Copy(BiTree T, BiTree &NewT) {
if (T)
{
NewT = (struct BiTNode *)malloc(sizeof(struct BiTNode));
NewT->data = T->data;
Copy(T->lchild, NewT->lchild);
Copy(T->rchild, NewT->rchild);
} else {
NewT = NULL;
}
}4.计算深度
int Depth(BiTree T) {
if (T) {
int m = Depth(T->lchild);
int n = Depth(T->rchild);
if (m > n) {
return m + 1;
} else return n + 1;
} else return 0;
}5.统计节点个数
int NodeCount(BiTree T)
{
if (T)
{
return NodeCount(T->lchild) + NodeCount(T->rchild) + 1;
}
else
return 0;
}6.根据中序和后序生成二叉树
在学习线索二叉树之前,先看看如何根据中序和后序生成二叉树,不然每次使用scanf去一个个输入太麻烦,对于后序遍历而言,最后一个节点就是二叉树(整个树或者子树)的根节点,再根据中序的特点:左子树都在根节点左边,右子树都在根节点右边进行递归遍历。另外不管是哪种遍历方式左孩子总是在右孩子前面。
所以假设有10个节点,根节点在第4个位置,那么中序遍历中,前3个是左子树,后面6个是右子树。而在后序遍历中,前3个是左子树,第4-9个是右子树,最后一个是根节点。此时中序遍历这10个节点,根节点右子树上的所有节点不可能在后序遍历中的前3位出现。因为左子树总是在右子树的前面遍历。
考虑二叉树:
+
a *
b -
c d
定义变量:
char center[] = "a+b*c-d"; // 中序遍历
char right[] = "abcd-*+"; // 后续遍历
然后期望是根据这两个变量生成二叉树,节省一个个输入字符的时间。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdlib.h>
#include <time.h>
// 中序线索二叉树
typedef struct BiThrNode
{
char data;
struct BiThrNode *lchild, *rchild;
int Ltag; // 1:前驱 0:左节点
int RTag; // 1:后驱 0:右节点
} BiThrNode, *BiThrTree;
// a+b*(c-d)
// +
// a *
// b -
// c d
void printThread(BiThrTree &p)
{
if (p)
{
printThread(p->lchild);
printf("%c ", p->data);
printThread(p->rchild);
}
}
// 根据中序遍历和后续遍历生成二叉树
void rebuild(BiThrTree &tree, char* start, char* end, int centerLength) {
// 子树的长度
if (centerLength <= 0) {
return;
} else {
BiThrTree current = (struct BiThrNode *)malloc(sizeof(struct BiThrNode));
current->data = *(end + centerLength - 1);
current->lchild = NULL;
current->rchild = NULL;
current->Ltag = 0;
current->RTag = 0;
tree = current;
// end是中序遍历的数组,最后一个是子树的根节点
int rootIndex = 0;
while (rootIndex < centerLength && start[rootIndex] != *(end + centerLength - 1))
{
rootIndex++; // 找到根节点的位置
}
rebuild(tree->lchild, start, end, rootIndex);
// printf("%c %d \n", *(start + rootIndex + 1), centerLength - rootIndex - 1);
rebuild(tree->rchild, start + rootIndex + 1, end + rootIndex, centerLength - rootIndex - 1);
}
}
int main()
{
BiThrTree p;
// +a##*b##-c##d##
char center[] = "a+b*c-d"; // 中序遍历
char right[] = "abcd-*+"; // 后续遍历
rebuild(p, center, right, sizeof(right) / sizeof(right[0]) - 1);
printThread(p);
return 0;
}7. 线索二叉树
线索二叉树的优点是遍历的时间复杂度,实现的原理是遍历的过程中如果没有左孩子,则lchild指向前驱节点, 如果没有右孩子则指向后继节点,因此还需要引入两个标识LTag和RTag,1表示有左孩子和右孩子,0表示没有孩子。前驱和后继节点的概念适用于中序遍历,前驱节点就是比节点小的最近一个节点,后继节点是比节点大的最近一个节点。按照遍历的方式,分为前序、中序和后序线索二叉树:
每次遍历的节点保留到pre变量中,这样遍历时可以访问到上一个前驱节点:
BiThrTree pre = NULL; // 指向上一个访问的节点
void InTheading(BiThrTree &p) {
if(p) {
InTheading(p->lchild);
if(!p->lchild) {
p->Ltag = 1;
p->lchild = pre;
} else {
p->Ltag = 0; // 有左孩子为0,没有左孩子为1,指向前一个节点
}
if (!pre->rchild) {
pre->RTag = 1;
pre->rchild = p; // 没有右孩子,指向下一个节点
} else {
p->RTag = 0;
}
pre = p;
InTheading(p->rchild);
}
}
8. 树的存储
第一种双亲表示法,用数组存储,每个数组存在节点信息,包括数据和唯一的父节点的索引。
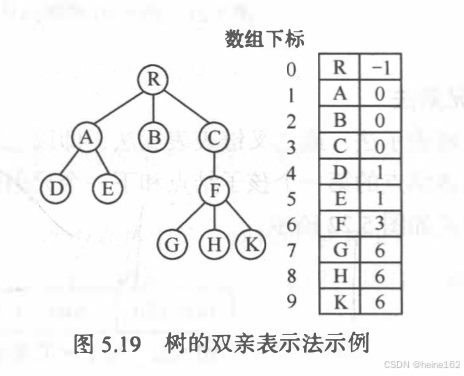
第二种孩子节点法,每个节点有多个指针,指向孩子节点。这些指针可以用数组保存也可以是顺序表,如果是顺序表的话他们没有层级关系,都是节点的孩子节点:
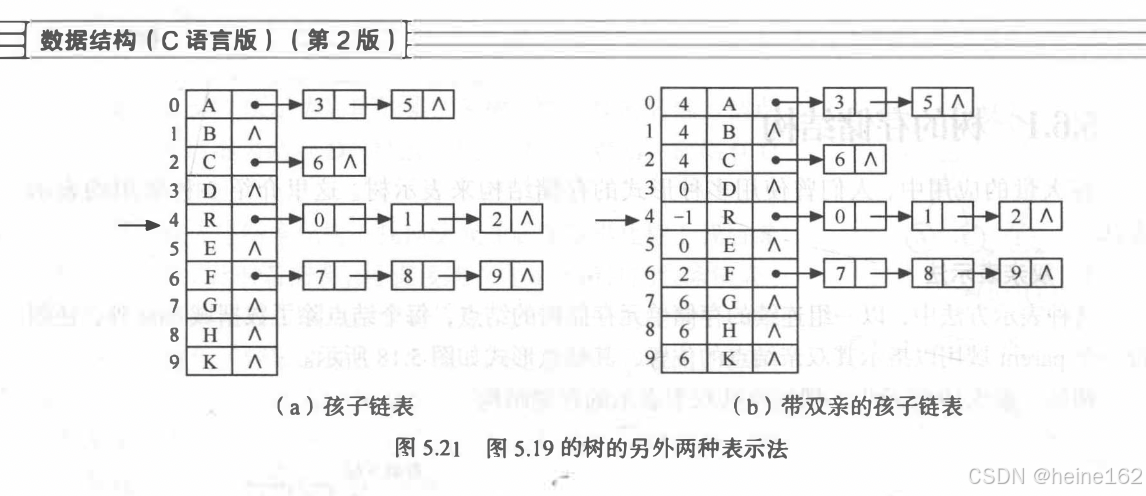
如果将双亲节点和孩子节点结合起来就是上右图。此外每个节点都被单独拎出来了,而不是json的格式。
第三种是孩子兄弟法,节点有两个指针域,一个代表孩子,一个代表右边的兄弟。用孩子兄弟法表示一般的树,能够将一般的树转化成二叉树处理。所以孩子兄弟法是最普遍的树的存储方法:
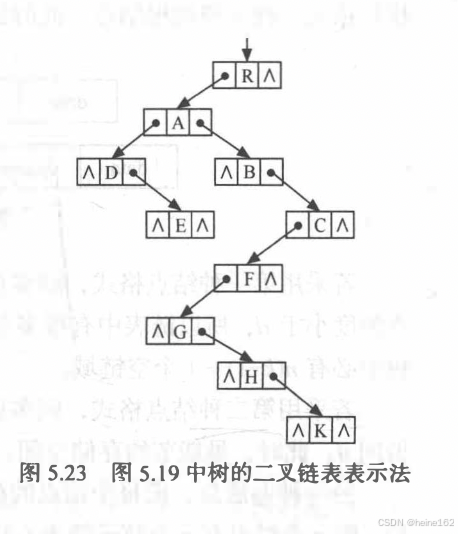
左边放的总是孩子,右边放的总是兄弟。
9. 图的存储
领接矩阵、邻接表、十字链表存储有向图,领接多重表存储无向图。
数据结构(十)----图(万字超全知识点!)_数据结构图的知识点-优快云博客
10. DFS(广度优先搜索)和BFS (深度优先搜索) js版本
如果安装了nodejs,使用 node xxx.js直接运行js代码,或者粘贴到浏览器F12控制台里。
// 1
// 2 3 4
// 5 6 7 8
// 9 10
const tree = {
data: 1,
next: [{
data: 2,
next: [{
data: 5,
next: [{
data: 9,
next: null
}]
}]
},
{
data: 3,
next: [{
data: 6,
next: [{
data: 10,
next: null
}],
}, {
data: 7,
next: null
}]
},
{
data: 4,
next: [null, {
data: 8,
next: null
}]
}
]
}
// 深度优先搜索,将节点放在一个栈里。因为是先一直往下找,所以同一层次的节点从右到左的入栈,然后栈顶出栈访问并压入它的子节点。
// 对于图而言,还需要构造一个visited数组,这样一个节点如果有多个父节点,只会访问一次。
function dfs(tree) {
const stack = [];
stack.push(tree); // 根节点入栈
while(stack.length) {
const currentNode = stack.pop(); // 提取数组最后一个
console.log(currentNode.data);
if (currentNode.next && currentNode.next.length) {
let i = currentNode.next.length;
// 倒序入栈,不要currentNode.next.reverse().forEach,这样会改变原有tree的结构。
while(i) {
currentNode.next[i-1] && stack.push(currentNode.next[i-1]);
i--;
}
}
}
}
console.log("---深度搜索---");
dfs(tree);
// 广度搜索,构造一个队列,将子节点按从左到右入队,然后出队访问
function bfs(tree) {
const stack = [];
stack.push(tree); // 根节点入栈
while(stack.length) {
const currentNode = stack.shift(); // 提取数组第一个
console.log(currentNode.data);
if (currentNode.next && currentNode.next.length) {
currentNode.next.forEach(item => {
if(item) { // 非空节点
stack.push(item);
}
});
}
}
}
console.log("---广度搜索---");
bfs(tree);思路其实很简单,用一个数组模拟栈或者队列。唯一需要注意的是形参是复杂类型的对象,不用调用reverse()方法去遍历入栈,这样要遍历的树结构会改变。不过这样一来交换二叉树的左右孩子是不是思路就有了?
11. BP和KMP算法
next[j]表示去匹配j个字符,前面j-1个相同,第j个不同时,要回溯到第next[j]个元素(前面的next[j]-1个元素相等),然后拿next[j]位置去和第j个元素匹配。如next[5]=3,意味着匹配到第5个字符时,发现不同了,则把字符串往右移位直到第三个位置,此时前两个位置t1t2=t3t4,所以可以拿t3去和母串的第5个位置去匹配,这时的结果就依赖于母串的值,而next[j]是可以通过递归逐级得到,因为计算next[j]总是意味着前面j-1个元素是匹配上的。
然后使用书上的例子进行验证:
// BMP算法
// 主串 ababcabcacbab
// 子串 abcac
// abcac 不行,因为和abcac和abcab不等。取出主串的abca和子串的abc比较,由于匹配到第5个字符不等,前面4个字符相等的,
// 所以可以看做是子串abca部分和去掉末尾以后的abc对比,因为abca同时是主串和子串序列。这样转化的好处是需要往前移到哪个字符对比只和子串自身有关。
// abca
// abc 不行,因为c不等于a,这里就已经有规律了,即往前匹配时,先要保证找到的字符等于末尾,即a的前面一个a
// a 此时只有一个字符a,这样就匹配上了1个字符,避免了还去从第4个字符开始重新匹配。实际上假设前面还有字符,想要匹配上只有可能是c,即ca去和abca的最后两位匹配。
// 这样的例子很容易推导出: 子串等于cabcax,主串为cabcabcax。第一次匹配卡在了主串的第6个字符b时,则前5个字符cabca和ca匹配上。这样由于第4,5位是ca对上了
// 所以下一次匹配是从子串的第三个字符b和主串的第6个字符b对比,当然如果主串的第6个字符不是b,那实际上就从ca开始往前找了,由于c不等于a,找不到相同的部分
// 所以这时就只能从第一个字符c和主串的第6个字符比(例:子串是cabcax,主串是cabcadcabcax,此时主串第6个字符不是b,要从ca往前找)。
// 将子串需要往前移的index下标放在next数组里记录,如abaabc就定义next是6维数组,next[6]表示第6个字符c匹配不上时,要返回的位置。
// 这时候考虑abaab,和ab匹配上,所以next[6]= 3,表示ab不用匹配了,从第三个字符a开始。又比如next[1]表示第一个字符就匹配不上,那只能拿子串的第一个字符重头开始匹配主串的下一个字符。
// next[j]计算思路方式很简单,如果用T表示子串,那么就是往前找到第一个和T[j-1]相等的位置k,然后还需要保证k之前的k-1个字符都和T[j-2]之前的k-1个字符相等。
// 因此next[j+1]=next[101]=k=10,其含义表示:1-10个字和91到100个字相等,即T[j-1]=T[k-1]。求next[j+1]是一个递归的过程,设next[j]=k。如果T[j-1]=T[k],则带上前面k-1个数就相等。
// 此时next[j+1]= next[j]+1。如果S中第j个数不等于第k个数,就去前面找匹配的字符,这时候去找next[k]= t,这时候如果第j个数T[j-1]= T[t-1],说明前面t-1个字带上第t个字T[t-1],一共t个字符是匹配的
// 此时next[j+1] = t + 1。
const str1 = "abaabcac";
// const str = "aba";
function get_next(T) {
let i = 2;
let next = [];
next[1] = 0; // 第一个匹配不上,应该拿子串的第一个字符去匹配主串的下一个字符了。
j = 0; // 保存next[i]的值。
while (i <= T.length) {
if (j == 0) {
next[i] = j + 1; // 第一次进来的时候next[2] = 1; 子串的第二个字符对不上,表示下一次拿子串的第一个去匹配主串的当前字符。
i++;
j++;
} else if(T[i-2] == T[j-1]) {
// 求next[i]时,考虑第i-1个数和第next[i-1]=k个数是否相等
next[i] = j + 1;
j++;
i++;
} else {
j = next[j];
}
}
// next.shift(); // 去掉第一个即可。不建议去,因为j = next[j],j=1时就是死循环,而j需要从1变成0。
return next;
}
console.log(get_next(str1)); // [undefined, 0, 1, 1, 2, 2, 3, 1, 2 ]
const S = "ababcabcacbab";
const T = "abcac";
function Index_KMP(S, T, _pos = 0) {
let j = 0;
let i = _pos;
const next = get_next(T); // 获取next的计算值
console.log("next:", next);
while(i < S.length && j < T.length) { // 匹配没结束
if (S[i] == T[j]) {
// j = 0意味着也要重新开始匹配
i++;
j++;
} else if(j == 0) {
i++;
} else {
j = next[j];
}
}
if(j == T.length) {
return i - j + 1;
} else return -1;
}
console.log(Index_KMP(S,T));需要注意的是本文没有像书本那样将if条件合并就是为了方便理解,因为它们的含义是不一样的。

12. 哈夫曼树
书上讲的不好
class Fn { }
class Node extends Fn {
constructor(data) {
super();
this.data = data;
this.left = null;
this.right = null;
}
}
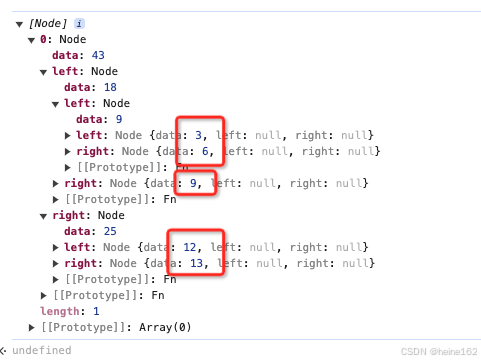
let arr = [12, 9, 13, 6, 3];
arr = arr.map(a => new Node(a));
let prev = {};
while(arr.length > 1) {
arr.sort((x,y) => y.data - x.data);
let min1 = arr.pop();
let min2 = arr.pop();
let nodes = new Node(min1.data + min2.data);
nodes.left = min1;
nodes.right = min2;
arr.push(nodes);
}
console.log(arr);
然后在浏览器控制台运行,数据放在叶子节点:
13. 表达式树的求值
之前使用两个栈进行计算。

后续遍历的常见场景,从叶子节点开始算起,一层层往上计算。
最后总结:

14. 二叉排序树
节点的左孩子节点的数据总是小于该节点的数据,节点的右孩子节点的数据总是大于该节点的数据。
二叉排序树的删除会比较复杂,最复杂的一种情况是删除的节点有左孩子和右孩子,这时候需要获取删除节点的前驱节点,把前驱节点的值赋值给删除的节点,然后delete该前驱节点,这里面又有下面三种情况,以删除节点p为例子:
例如要删除节点p,就不需要关心p的右孩子,考虑p的前驱节点,令p的data值等于前驱节点的data,再将前驱节点删掉。
/**
* p
* x1
* x2 s
* x3
*
* 此时s是前驱节点,x1.rchild = s.lchild让x1的右孩子指向s的左孩子,delete s节点(其实x1
* 的右孩子指向s的左孩子就等于已经删了)。如果s下面有右孩子,则转到下面第三种情况s有右孩子x4
*
* p
* x1
* x2
*
* 此时x1是前驱节点,p.lchild = x1.lchild,delete x1节点
*
* p
* x1
* x2 s
* x3 x4
*
* 此时x4是p的前驱节点,令p.data = x4.data, 由于x4没有孩子了,delete x4节点即可。可以
* 通过s.rchild = null实现
*/以上三种目标都是删除节点p,其核心思路是删除发生了转移,即删除p的前驱节点而不是删除p,另外如果p 下面的两个孩子都是叶子节点x1,x2,虽然delete p.x2也没问题,但为了统一思路,这里实际的操作是p.data = x1.data,然后p.lchild = null。这样就会感觉平衡二叉树的删除工作非常巧妙了。
构造一颗二叉排序树结构,然后删除其中的24:
// 45
// 24 61
// 3 37 53 78
// 12 100
// 90完整代码:
/**
* 二叉排序树
*/
class BSTNode {
constructor(data) {
this.key = data; // 索引,用于排序
this.data = data;
this.lchild = null;
this.rchild = null;
}
}
function initBST(arr) {
let tree = null;
for (let i = 0; i < arr.length; i++) {
let current = new BSTNode(arr[i]);
// 根节点初始化
if (tree == null) {
tree = current;
} else {
// 递归插入节点
insertNode(tree, arr[i]);
}
}
return tree;
/**
* 二叉排序树插入
* js中复杂类型也一定要通过T.lchild = xxx的方式去赋值,T = T.lchild, T = xxx不起作用
*/
function insertNode(T, element) {
if (!T) {
return;
} else {
// element比节点数据小,尝试放在左子树
if (T.data > element) {
if (T.lchild) {
// 去跟左孩子比较
insertNode(T.lchild, element);
} else {
// 左孩子为空,创建左孩子节点
T.lchild = new BSTNode(element);
}
} else if (T.data < element) {
if (T.rchild) {
insertNode(T.rchild, element);
} else {
T.rchild = new BSTNode(element);
}
}
}
}
}
// 复制一棵树
function copy(origin, target) {
if (origin) {
target.data = origin.data;
target.lchild = {};
target.rchild = {};
copy(origin.lchild, target.lchild);
copy(origin.rchild, target.rchild);
}
}
// 删除一个节点,分三种情况
function deleteBST(T, element) {
let p = T; // 要删除的节点
let parent = null; // p节点的父节点
while (p) {
// 找到节点p就跳出循环,此时p为要删除的节点
if (p.data == element) {
break;
}
parent = p; // 记录要删除的节点的父节点
// 比要找的数据大,从左子树开始找
if (p.data > element) {
p = p.lchild;
} else {
p = p.rchild;
}
}
if (!p) {
return; // 没有找到要删除的节点
}
if (p.lchild && p.rchild) {
let q = p;
s = p.lchild; // 如果p节点左右孩子都有,不用考虑p节点的右孩子。此时我们的目标是把左孩子的最大节点删了,值赋给p
// 非空对象
while (s.rchild && Object.keys(s.rchild).length) {
q = s; // 前驱节点的父节点
s = s.rchild; // 找到前驱节点
}
p.data = s.data; // 将前驱节点放在要删除的节点
if (p != q) {
// 删除p节点,我们的目标是删除p的前驱节点s,将s的值赋值给p。如果s还有子节点,想办法把s的子节点如s3连到x1下面
// 所以需要一直取右孩子,取到s,同时记录s的父节点x1记为q,q.rchild = s.lchild的含义就是x1的右孩子指向x3。
// p
// x1
// x2 s
// x3
if (s.lchild) {
q.rchild = s.lchild; // x1的右孩子指向x3
} else {
// p
// x1
// x2 s
// x3 x4
// 以上的结构,代码里的s指向x4,只需要删除x4
q.rchild = null; // 删除x4
}
} else {
// p
// x1
// x2
q.lchild = s.lchild; // 此时s是x1,p的左孩子指向x2。当然如果x1没有x2子孩子的话,q.lchild=null也依然成立。
}
// 前驱节点删了
delete s;
return;
} else {
let s = {}; // 如果p是叶子节点,父节点的孩子为{},表示直接删除
if (p.lchild) {
s = p.lchild;
}
if (p.rchild) {
s = p.rchild;
}
if(!parent) {
// 执行T=s
for(let o in s) {
T[o] = s[o];
}
return;
}
if (p == parent.lchild) {
parent.lchild = s;
} else {
parent.rchild = s;
}
}
}
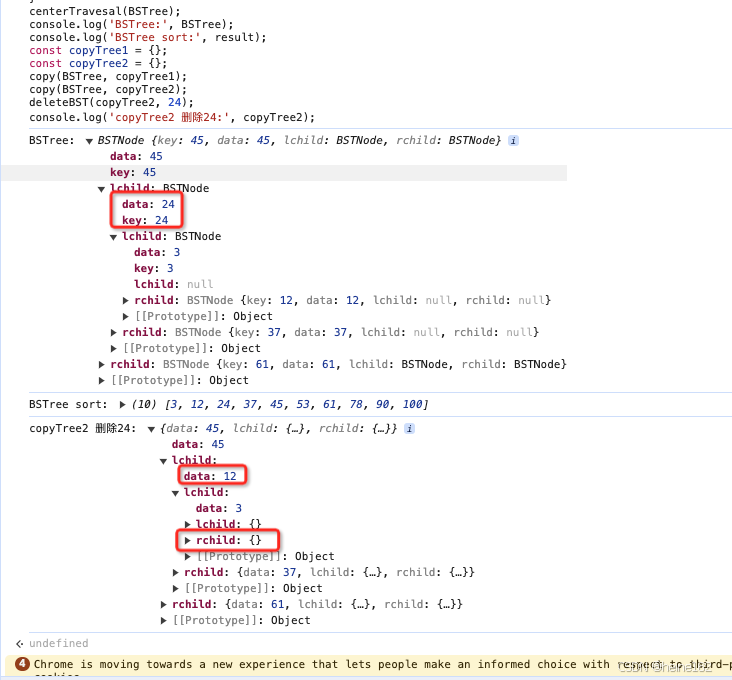
let list = [45, 61, 24, 78, 3, 100, 53, 12, 90, 37];
// 45
// 24 61
// 3 37 53 78
// 12 100
// 90
const BSTree = initBST(list); // 排序树
const result = []; // 中序遍历结果
function centerTravesal(root) {
if (root) {
centerTravesal(root.lchild);
result.push(root.data);
centerTravesal(root.rchild);
}
}
centerTravesal(BSTree);
console.log('BSTree:', BSTree);
console.log('BSTree sort:', result);
const copyTree1 = {};
const copyTree2 = {};
copy(BSTree, copyTree1);
copy(BSTree, copyTree2);
deleteBST(copyTree2, 24);
console.log('copyTree2 删除24:', copyTree2);
与课本上逻辑基本一致,然后在浏览器中运行:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











