






1. LoRA微调
loader:
# -*- coding: utf-8 -*-
import json
import re
import os
import torch
import numpy as np
from torch.utils.data import Dataset, DataLoader
from transformers import BertTokenizer
"""
数据加载
"""
class DataGenerator:
def __init__(self, data_path, config):
self.config = config
self.path = data_path
self.index_to_label = {0: '家居', 1: '房产', 2: '股票', 3: '社会', 4: '文化',
5: '国际', 6: '教育', 7: '军事', 8: '彩票', 9: '旅游',
10: '体育', 11: '科技', 12: '汽车', 13: '健康',
14: '娱乐', 15: '财经', 16: '时尚', 17: '游戏'}
self.label_to_index = dict((y, x) for x, y in self.index_to_label.items())
self.config["class_num"] = len(self.index_to_label)
if self.config["model_type"] == "bert":
self.tokenizer = BertTokenizer.from_pretrained(config["pretrain_model_path"])
self.vocab = load_vocab(config["vocab_path"])
self.config["vocab_size"] = len(self.vocab)
self.load()
def load(self):
self.data = []
with open(self.path, encoding="utf8") as f:
for line in f:
line = json.loads(line)
tag = line["tag"]
label = self.label_to_index[tag]
title = line["title"]
if self.config["model_type"] == "bert":
input_id = self.tokenizer.encode(title, max_length=self.config["max_length"], pad_to_max_length=True)
else:
input_id = self.encode_sentence(title)
input_id = torch.LongTensor(input_id)
label_index = torch.LongTensor([label])
self.data.append([input_id, label_index])
return
def encode_sentence(self, text):
input_id = []
for char in text:
input_id.append(self.vocab.get(char, self.vocab["[UNK]"]))
input_id = self.padding(input_id)
return input_id
#补齐或截断输入的序列,使其可以在一个batch内运算
def padding(self, input_id):
input_id = input_id[:self.config["max_length"]]
input_id += [0] * (self.config["max_length"] - len(input_id))
return input_id
def __len__(self):
return len(self.data)
def __getitem__(self, index):
return self.data[index]
def load_vocab(vocab_path):
token_dict = {}
with open(vocab_path, encoding="utf8") as f:
for index, line in enumerate(f):
token = line.strip()
token_dict[token] = index + 1 #0留给padding位置,所以从1开始
return token_dict
#用torch自带的DataLoader类封装数据
def load_data(data_path, config, shuffle=True):
dg = DataGenerator(data_path, config)
dl = DataLoader(dg, batch_size=config["batch_size"], shuffle=shuffle)
return dl
if __name__ == "__main__":
from config import Config
dg = DataGenerator("valid_tag_news.json", Config)
print(dg[1])
model:
import torch.nn as nn
from config import Config
from transformers import AutoTokenizer, AutoModelForSequenceClassification, AutoModel
from torch.optim import Adam, SGD
TorchModel = AutoModelForSequenceClassification.from_pretrained(Config["pretrain_model_path"])
def choose_optimizer(config, model):
optimizer = config["optimizer"]
learning_rate = config["learning_rate"]
if optimizer == "adam":
return Adam(model.parameters(), lr=learning_rate)
elif optimizer == "sgd":
return SGD(model.parameters(), lr=learning_rate)
evaluate:
# -*- coding: utf-8 -*-
import torch
from loader import load_data
"""
模型效果测试
"""
class Evaluator:
def __init__(self, config, model, logger):
self.config = config
self.model = model
self.logger = logger
self.valid_data = load_data(config["valid_data_path"], config, shuffle=False)
self.stats_dict = {"correct":0, "wrong":0} #用于存储测试结果
def eval(self, epoch):
self.logger.info("开始测试第%d轮模型效果:" % epoch)
self.model.eval()
self.stats_dict = {"correct": 0, "wrong": 0} # 清空上一轮结果
for index, batch_data in enumerate(self.valid_data):
if torch.cuda.is_available():
batch_data = [d.cuda() for d in batch_data]
input_ids, labels = batch_data #输入变化时这里需要修改,比如多输入,多输出的情况
with torch.no_grad():
pred_results = self.model(input_ids)[0]
self.write_stats(labels, pred_results)
acc = self.show_stats()
return acc
def write_stats(self, labels, pred_results):
# assert len(labels) == len(pred_results)
for true_label, pred_label in zip(labels, pred_results):
pred_label = torch.argmax(pred_label)
# print(true_label, pred_label)
if int(true_label) == int(pred_label):
self.stats_dict["correct"] += 1
else:
self.stats_dict["wrong"] += 1
return
def show_stats(self):
correct = self.stats_dict["correct"]
wrong = self.stats_dict["wrong"]
self.logger.info("预测集合条目总量:%d" % (correct +wrong))
self.logger.info("预测正确条目:%d,预测错误条目:%d" % (correct, wrong))
self.logger.info("预测准确率:%f" % (correct / (correct + wrong)))
self.logger.info("--------------------")
return correct / (correct + wrong)
main:
# -*- coding: utf-8 -*-
import torch
import os
import random
import os
import numpy as np
import torch.nn as nn
import logging
from config import Config
from model import TorchModel, choose_optimizer
from evaluate import Evaluator
from loader import load_data
from peft import get_peft_model, LoraConfig, \
PromptTuningConfig, PrefixTuningConfig, PromptEncoderConfig
#[DEBUG, INFO, WARNING, ERROR, CRITICAL]
logging.basicConfig(level=logging.INFO, format = '%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
"""
模型训练主程序
"""
seed = Config["seed"]
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
def main(config):
#创建保存模型的目录
if not os.path.isdir(config["model_path"]):
os.mkdir(config["model_path"])
#加载训练数据
train_data = load_data(config["train_data_path"], config)
#加载模型
model = TorchModel
#大模型微调策略
tuning_tactics = config["tuning_tactics"]
if tuning_tactics == "lora_tuning":
peft_config = LoraConfig(
r=8,
lora_alpha=32,
lora_dropout=0.1,
target_modules=["query", "key", "value"]
)
elif tuning_tactics == "p_tuning":
peft_config = PromptEncoderConfig(task_type="SEQ_CLS", num_virtual_tokens=10)
elif tuning_tactics == "prompt_tuning":
peft_config = PromptTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=10)
elif tuning_tactics == "prefix_tuning":
peft_config = PrefixTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=10)
model = get_peft_model(model, peft_config)
# print(model.state_dict().keys())
if tuning_tactics == "lora_tuning":
# lora配置会冻结原始模型中的所有层的权重,不允许其反传梯度
# 但是事实上我们希望最后一个线性层照常训练,只是bert部分被冻结,所以需要手动设置
for param in model.get_submodule("model").get_submodule("classifier").parameters():
param.requires_grad = True
# 标识是否使用gpu
cuda_flag = torch.cuda.is_available()
if cuda_flag:
logger.info("gpu可以使用,迁移模型至gpu")
model = model.cuda()
#加载优化器
optimizer = choose_optimizer(config, model)
#加载效果测试类
evaluator = Evaluator(config, model, logger)
#训练
for epoch in range(config["epoch"]):
epoch += 1
model.train()
logger.info("epoch %d begin" % epoch)
train_loss = []
for index, batch_data in enumerate(train_data):
if cuda_flag:
batch_data = [d.cuda() for d in batch_data]
optimizer.zero_grad()
input_ids, labels = batch_data #输入变化时这里需要修改,比如多输入,多输出的情况
output = model(input_ids)[0]
loss = nn.CrossEntropyLoss()(output, labels.view(-1))
loss.backward()
optimizer.step()
train_loss.append(loss.item())
if index % int(len(train_data) / 2) == 0:
logger.info("batch loss %f" % loss)
logger.info("epoch average loss: %f" % np.mean(train_loss))
acc = evaluator.eval(epoch)
model_path = os.path.join(config["model_path"], "%s.pth" % tuning_tactics)
save_tunable_parameters(model, model_path) #保存模型权重
return acc
def save_tunable_parameters(model, path):
saved_params = {
k: v.to("cpu")
for k, v in model.named_parameters()
if v.requires_grad
}
torch.save(saved_params, path)
if __name__ == "__main__":
main(Config)
pred:
import torch
import logging
from model import TorchModel
from peft import get_peft_model, LoraConfig, PromptTuningConfig, PrefixTuningConfig, PromptEncoderConfig
from evaluate import Evaluator
from config import Config
logging.basicConfig(level=logging.INFO, format = '%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
#大模型微调策略
tuning_tactics = Config["tuning_tactics"]
print("正在使用 %s"%tuning_tactics)
if tuning_tactics == "lora_tuning":
peft_config = LoraConfig(
r=8,
lora_alpha=32,
lora_dropout=0.1,
target_modules=["query", "key", "value"]
)
elif tuning_tactics == "p_tuning":
peft_config = PromptEncoderConfig(task_type="SEQ_CLS", num_virtual_tokens=10)
elif tuning_tactics == "prompt_tuning":
peft_config = PromptTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=10)
elif tuning_tactics == "prefix_tuning":
peft_config = PrefixTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=10)
#重建模型
model = TorchModel
# print(model.state_dict().keys())
# print("====================")
model = get_peft_model(model, peft_config)
# print(model.state_dict().keys())
# print("====================")
state_dict = model.state_dict()
#将微调部分权重加载
if tuning_tactics == "lora_tuning":
loaded_weight = torch.load('output/lora_tuning.pth')
elif tuning_tactics == "p_tuning":
loaded_weight = torch.load('output/p_tuning.pth')
elif tuning_tactics == "prompt_tuning":
loaded_weight = torch.load('output/prompt_tuning.pth')
elif tuning_tactics == "prefix_tuning":
loaded_weight = torch.load('output/prefix_tuning.pth')
print(loaded_weight.keys())
state_dict.update(loaded_weight)
#权重更新后重新加载到模型
model.load_state_dict(state_dict)
#进行一次测试
model = model.cuda()
evaluator = Evaluator(Config, model, logger)
evaluator.eval(0)
2. transform XL
状态复用和块级别循环解决文本长度不够问题,相对位置编码ROPE是XL的两个特点。
transformer处理长文本将文本切成固定长度的序列块,如每一块长度为4,transformer先训练x1、x2、x3、x4,在训练x5、x6、x7、x8。这样块之间没法进行关联,如果以滑动窗口的形式,效率又比较低,所以一种能够想到的思路就是把x1、x2、x3、x4的隐藏层输出值加入到x5、x6、x7、x8中训练,transform XL的第一个特点就是如此:
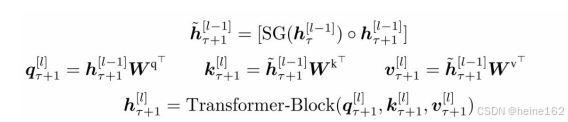
函数SG()表示停止梯度传输, ◦ 表示沿长度维度进行拼接,h_t表示第t块文本,h_t+1表示第t+1块,l表示第l层的transformer隐藏层,上图是计算第t+1块在l层transformer的隐藏层,q_t+1只和上一个隐藏层有关,也就是只计算当前块,和上一个序列块没有关系,k和v是包含h_t+1在l-1隐藏层的上文信息和上一个块h_t在l-1层的输出信息,然后q,k,v进TransformerBlock层计算输出,TransformerBlock就是multi-head attention层。
由于把第1块和第2块放一起了,对于同一行而言,他们的位置信息相同,这样position embedding后同一行不同块的位置信息无法区别,而ROPE就是用来解决这个事情的。
def merge(ids, pair, idx):
# in the list of ints (ids), replace all consecutive occurences of pair with the new token idx
newids = []
i = 0
while i < len(ids):
# if we are not at the very last position AND the pair matches, replace it
if i < len(ids) - 1 and ids[i] == pair[0] and ids[i+1] == pair[1]:
newids.append(idx)
i += 2
else:
newids.append(ids[i])
i += 1
return newids
print(merge([5, 6, 6, 7, 9, 1], (6, 7), 99))
tokens2 = merge(tokens, top_pair, 256)
print(tokens2)
print("length:", len(tokens2))3. RAG
import json
import math
import os
import pickle
import sys
from typing import Dict, List
class BM25:
EPSILON = 0.25
PARAM_K1 = 1.5 # BM25算法中超参数
PARAM_B = 0.6 # BM25算法中超参数
def __init__(self, corpus: Dict):
"""
初始化BM25模型
:param corpus: 文档集, 文档集合应该是字典形式,key为文档的唯一标识,val对应其文本内容,文本内容需要分词成列表
"""
self.corpus_size = 0 # 文档数量
self.wordNumsOfAllDoc = 0 # 用于计算文档集合中平均每篇文档的词数 -> wordNumsOfAllDoc / corpus_size
self.doc_freqs = {} # 记录每篇文档中查询词的词频
self.idf = {} # 记录查询词的 IDF
self.doc_len = {} # 记录每篇文档的单词数
self.docContainedWord = {} # 包含单词 word 的文档集合
self._initialize(corpus)
def _initialize(self, corpus: Dict):
"""
根据语料库构建倒排索引
"""
# nd = {} # word -> number of documents containing the word
for index, document in corpus.items():
self.corpus_size += 1
self.doc_len[index] = len(document) # 文档的单词数
self.wordNumsOfAllDoc += len(document)
frequencies = {} # 一篇文档中单词出现的频率
for word in document:
if word not in frequencies:
frequencies[word] = 0
frequencies[word] += 1
self.doc_freqs[index] = frequencies
# 构建词到文档的倒排索引,将包含单词的和文档和包含关系进行反向映射
for word in frequencies.keys():
if word not in self.docContainedWord:
self.docContainedWord[word] = set()
self.docContainedWord[word].add(index)
# 计算 idf
idf_sum = 0 # collect idf sum to calculate an average idf for epsilon value
negative_idfs = []
for word in self.docContainedWord.keys():
doc_nums_contained_word = len(self.docContainedWord[word])
idf = math.log(self.corpus_size - doc_nums_contained_word +
0.5) - math.log(doc_nums_contained_word + 0.5)
self.idf[word] = idf
idf_sum += idf
if idf < 0:
negative_idfs.append(word)
average_idf = float(idf_sum) / len(self.idf)
eps = BM25.EPSILON * average_idf
for word in negative_idfs:
self.idf[word] = eps
@property
def avgdl(self):
return float(self.wordNumsOfAllDoc) / self.corpus_size
def get_score(self, query: List, doc_index):
"""
计算查询 q 和文档 d 的相关性分数
:param query: 查询词列表
:param doc_index: 为语料库中某篇文档对应的索引
"""
k1 = BM25.PARAM_K1
b = BM25.PARAM_B
score = 0
doc_freqs = self.doc_freqs[doc_index]
for word in query:
if word not in doc_freqs:
continue
score += self.idf[word] * doc_freqs[word] * (k1 + 1) / (
doc_freqs[word] + k1 * (1 - b + b * self.doc_len[doc_index] / self.avgdl))
return [doc_index, score]
def get_scores(self, query):
scores = [self.get_score(query, index) for index in self.doc_len.keys()]
return scores
import json
import os
import jieba
import numpy as np
from zhipuai import ZhipuAI
from bm25 import BM25
'''
基于RAG来介绍Dota2英雄故事和技能
用bm25做召回
同样以来智谱的api作为我们的大模型
'''
#智谱的api作为我们的大模型
def call_large_model(prompt):
client = ZhipuAI(api_key="3c82da390b9342a5affea43aa9e8fc9a.kZgYNFi3MEj9NUnH") # 填写您自己的APIKey
response = client.chat.completions.create(
model="glm-3-turbo", # 填写需要调用的模型名称
messages=[
{"role": "user", "content": prompt},
],
)
response_text = response.choices[0].message.content
return response_text
class SimpleRAG:
def __init__(self, folder_path="Heroes"):
self.load_hero_data(folder_path)
def load_hero_data(self, folder_path):
self.hero_data = {}
for file_name in os.listdir(folder_path):
if file_name.endswith(".txt"):
with open(os.path.join(folder_path, file_name), "r", encoding="utf-8") as file:
intro = file.read()
hero = file_name.split(".")[0]
self.hero_data[hero] = intro
corpus = {}
self.index_to_name = {}
index = 0
for hero, intro in self.hero_data.items():
corpus[hero] = jieba.lcut(intro)
self.index_to_name[index] = hero
index += 1
self.bm25_model = BM25(corpus)
return
def retrive(self, user_query):
scores = self.bm25_model.get_scores(jieba.lcut(user_query))
sorted_scores = sorted(scores, key=lambda x: x[1], reverse=True)
hero = sorted_scores[0][0]
text = self.hero_data[hero]
return text
def query(self, user_query):
print("user_query:", user_query)
print("=======================")
retrive_text = self.retrive(user_query)
print("retrive_text:", retrive_text)
print("=======================")
prompt = f"请根据以下从数据库中获得的英雄故事和技能介绍,回答用户问题:\n\n英雄故事及技能介绍:\n{retrive_text}\n\n用户问题:{user_query}"
response_text = call_large_model(prompt)
print("模型回答:", response_text)
print("=======================")
if __name__ == "__main__":
rag = SimpleRAG()
user_query = "高射火炮是谁的技能"
rag.query(user_query)
print("----------------")
print("No RAG (直接请求大模型回答):")
print(call_large_model(user_query))RAG在数值计算上效果不太好,知识图谱需要结构化的数据,整理起来花费时间



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











