




 本文探讨了可解释机器学习(IML)的发展历程,从线性回归到深度学习,以及当前的IML方法,如分析模型组件和敏感性。尽管IML在回归和规则学习上历史悠久,但在2015年后显著增长。常见的IML方法包括线性模型、决策树和CNN特征可视化。然而,统计不确定性、因果解释和特征依赖是当前面临的挑战。未来,IML需要跨领域合作,以满足不同背景的解释需求。
本文探讨了可解释机器学习(IML)的发展历程,从线性回归到深度学习,以及当前的IML方法,如分析模型组件和敏感性。尽管IML在回归和规则学习上历史悠久,但在2015年后显著增长。常见的IML方法包括线性模型、决策树和CNN特征可视化。然而,统计不确定性、因果解释和特征依赖是当前面临的挑战。未来,IML需要跨领域合作,以满足不同背景的解释需求。
近年来,可解释机器学习(IML) 的相关研究蓬勃发展。尽管这个领域才刚刚起步,但是它在回归建模和基于规则的机器学习方面的相关工作却始于20世纪60年代。最近,arXiv上的一篇论文简要介绍了解释机器学习(IML)领域的历史,给出了最先进的可解释方法的概述,并讨论了遇到的挑战。
当机器学习模型用在产品、决策或者研究过程中的时候,“可解释性”通常是一个决定因素。
可解释机器学习(Interpretable machine learning ,简称 IML)可以用来来发现知识,调试、证明模型及其预测,以及控制和改进模型。
研究人员认为 IML的发展在某些情况下可以认为已经步入了一个新的阶段,但仍然存在一些挑战。
可解释机器学习(IML)简史
最近几年有很多关于可解释机器学习的相关研究, 但是从数据中学习可解释模型的历史由来已久。
线性回归早在19世纪初就已经被使用,从那以后又发展成各种各样的回归分析工具,例如,广义相加模型(generalized additive models)和弹性网络(elastic net)等。
这些统计模型背后的哲学意义通常是做出某些分布假设或限制模型的复杂性,并因此强加模型的内在可解释性。
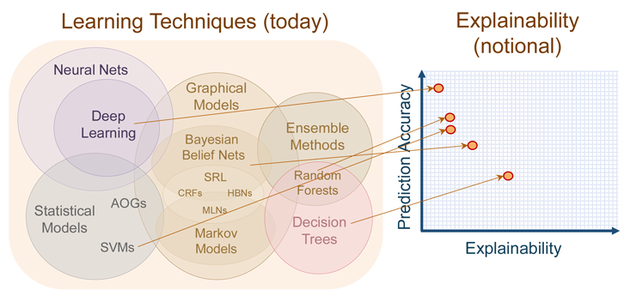
而在机器学习中,使用的建模方法略有不同。
机器学习算法通常遵循非线性,非参数方法,而不是预先限制模型的复杂性,在该方法中,模型的复杂性通过一个或多个超参数进行控制,并通过交叉验证
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7828
7828

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









