






第一步,安装Ollama。打开官网下载:https://ollama.com/download
可以选择Download for Windows来下载。然后双击OllamaSetup.exe按提示安装完成。
第二步,打开Windows PowerShell,或者CMD命令。
如下载Qwen3-Embedding-0.6B,可以输入Ollama命令:
ollama run dengcao/Qwen3-Embedding-0.6B:F16如下载Qwen3-Reranker-0.6B,可以输入Ollama命令:
ollama run dengcao/Qwen3-Reranker-0.6B:F16接下来等待下载完成即可。
下面列出Qwen3-Embedding和Qwen3-Reranker各个版本的Ollama安装命令。
Qwen3-Embedding-0.6B系列:
ollama run dengcao/Qwen3-Embedding-0.6B:Q8_0
ollama run dengcao/Qwen3-Embedding-0.6B:F16
Qwen3-Embedding-4B系列:
ollama run dengcao/Qwen3-Embedding-4B:Q4_K_M
ollama run dengcao/Qwen3-Embedding-4B:Q5_K_M
ollama run dengcao/Qwen3-Embedding-4B:Q8_0
ollama run dengcao/Qwen3-Embedding-8B:F16
Qwen3-Embedding-8B系列:
ollama run dengcao/Qwen3-Embedding-8B:Q4_K_M
ollama run dengcao/Qwen3-Embedding-8B:Q5_K_M
ollama run dengcao/Qwen3-Embedding-8B:Q8_0
Qwen3-Reranker-0.6B系列:
ollama run dengcao/Qwen3-Reranker-0.6B:Q8_0
ollama run dengcao/Qwen3-Reranker-0.6B:F16
Qwen3-Reranker-4B系列:
ollama run dengcao/Qwen3-Reranker-4B:Q4_K_M
ollama run dengcao/Qwen3-Reranker-4B:Q5_K_M
ollama run dengcao/Qwen3-Reranker-4B:Q8_0
Qwen3-Reranker-8B系列:
ollama run dengcao/Qwen3-Reranker-8B:Q3_K_M
ollama run dengcao/Qwen3-Reranker-8B:Q4_K_M
ollama run dengcao/Qwen3-Reranker-8B:Q5_K_M
ollama run dengcao/Qwen3-Reranker-8B:Q8_0
ollama run dengcao/Qwen3-Reranker-8B:F16
关于量化版本的说明:
q8_0:与浮点数16几乎无法区分。资源使用率高,速度慢。不建议大多数用户使用。
q6_k:将Q8_K用于所有张量。
q5_k_m:将 Q6_K 用于一半的 attention.wv 和 feed_forward.w2 张量,否则Q5_K。
q5_0: 原始量化方法,5位。精度更高,资源使用率更高,推理速度更慢。
q4_k_m:将 Q6_K 用于一半的 attention.wv 和 feed_forward.w2 张量,否则Q4_K
q4_0:原始量化方法,4 位。
q3_k_m:将 Q4_K 用于 attention.wv、attention.wo 和 feed_forward.w2 张量,否则Q3_K
q2_k:将 Q4_K 用于 attention.vw 和 feed_forward.w2 张量,Q2_K用于其他张量。
根据经验,建议使用 Q5_K_M,因为它保留了模型的大部分性能。或者,如果要节省一些内存,可以使用 Q4_K_M。
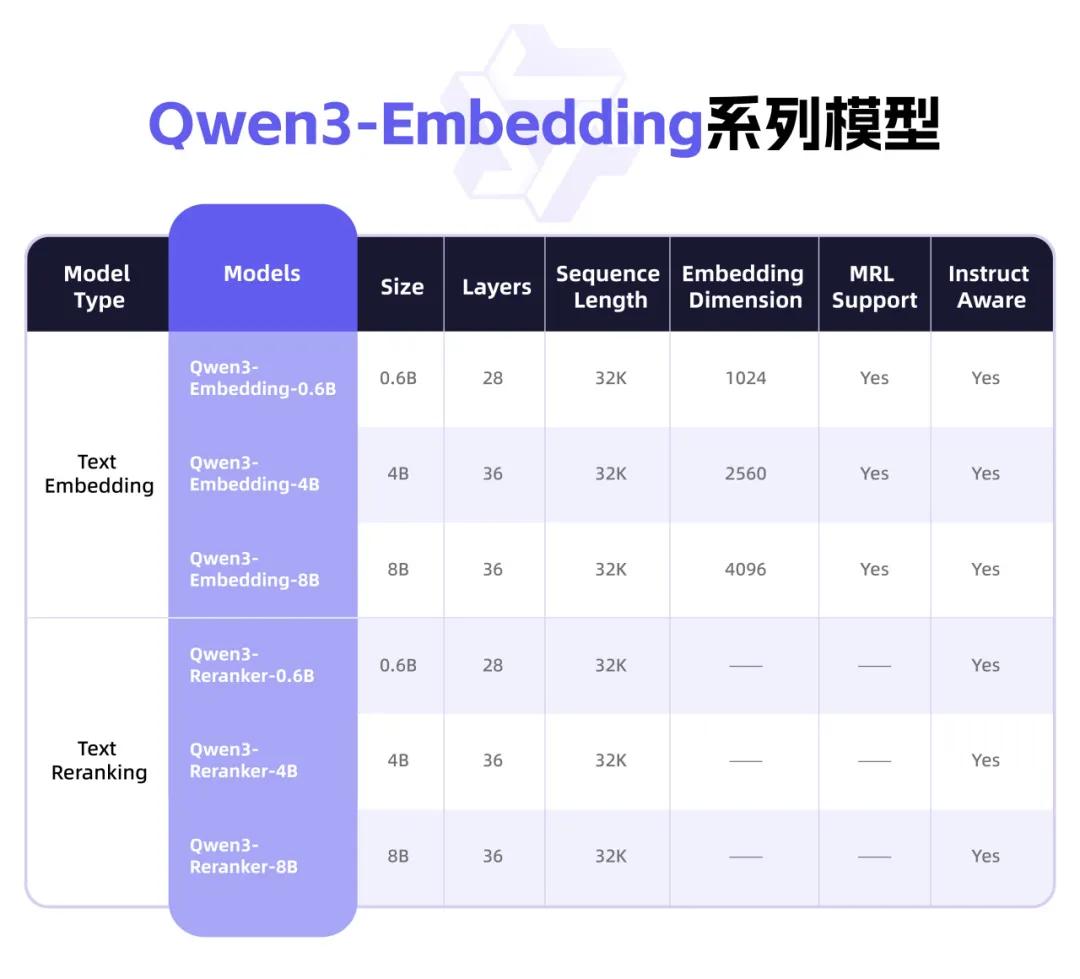
Qwen3深夜上新,Embedding系列和Reranker系列全新登场!
它专为文本表征、检索与排序任务设计,旨在将文本(如句子、段落)转换为高质量的向量表示,以便在语义搜索、问答系统、推荐引擎等应用中更有效地处理和理解自然语言。
可用于文档检索、RAG、分类、情感分析、检索等任务。
它在Qwen3基础模型上训练而来,充分发挥Qwen3的多语言优势。
一共有0.6B/4B/8B三种尺寸,8B版本在MTEB多语言Leaderboard榜单中排名第一,性能超越一众商业API服务。

















 1167
1167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









